How Can Automated Retail Checkouts Recognize Unlabeled Produce? Meet the PseudoAugment Computer Vision Approach
With the advancements in machine learning and deep learning techniques, there has also been an increase in automation of various dimensions. Automation is progressively reducing the need for human intervention in numerous routine aspects of daily life, particularly within retail.
They enable us to keep track of natural resources and also help in environmental sustainability. Automated systems help optimize the supply chain by enhancing inventory management, demand forecasting, and logistics coordination. However, there are some instances where automation is tough and complex. The identification of produce without a barcode is one example.
The ability to discern weighted objects is required to bill a consumer at a self-checkout station appropriately. Such a system must be able to identify all the many types of unpackaged produce, grains, and other goods sold. Generally, in many retail shops, customers need to remember a product code and weigh goods in the section to identify the type of fruits or vegetables themselves.
To overcome this problem, researchers from Skoltech and other institutions have devised a new way to distinguish weighted goods at a supermarket. The researchers used computer vision to facilitate this process. This approach speeds up neural network training even when new produce varieties are introduced.
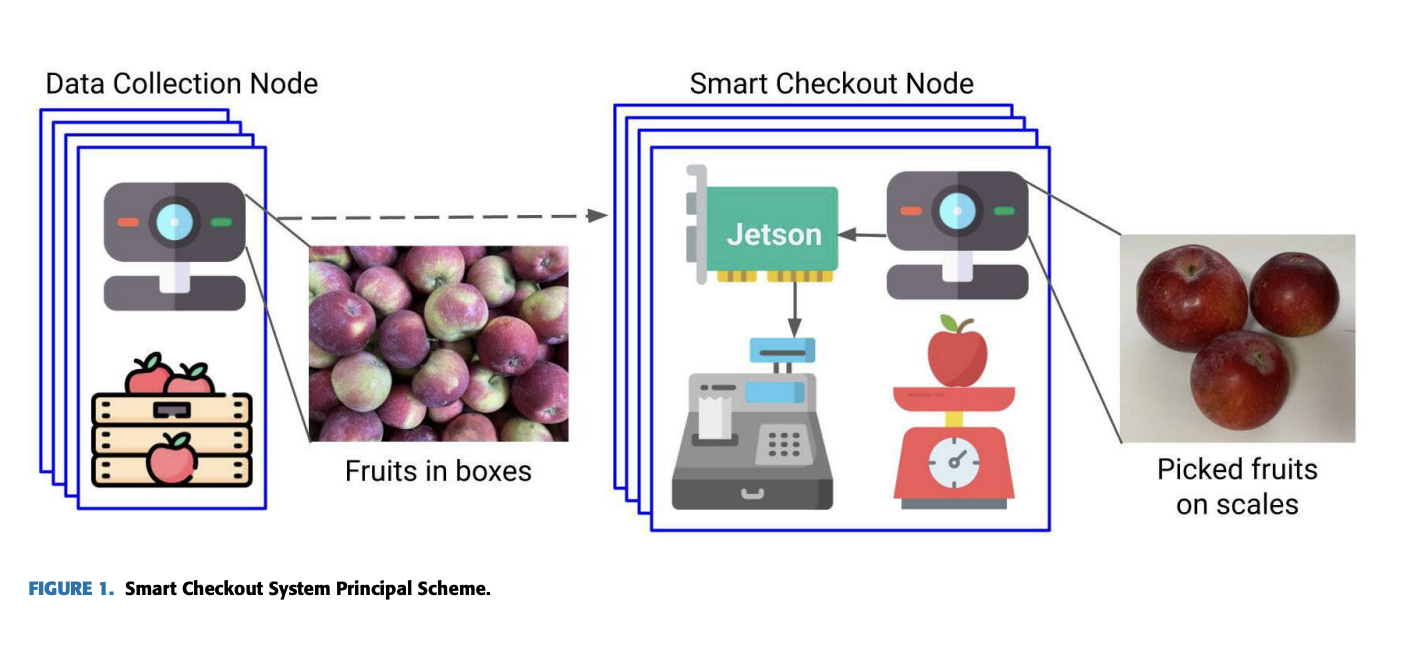
To facilitate this research, the researchers collected different types of images. The images they collected were taken in various locations: in a garden, at a local grocery store, and in a lab setting. They took 1000 natural images per class, totaling 5000 natural images. Another type of image they used contains top-view container images in which many objects were in the top-view. They used 70 top-view images per class, with 7.1 objects per image on average. They combined different images and backgrounds, applied various transformations, and generated more training images than the number of cropped objects.
The researchers also augmented(a visual manipulation of raw data that adds created images to photos) the images by ensuring that detection quality degradation is much lower than that without PseudoAugment.
The research team said that there exist a few limitations with the earlier types of processes. They said the difficulty is that many visually similar fruits or vegetables are at the supermarket, and new types often appear. Classical computer vision systems need to be retrained every time a new variety is delivered. They further said that it is time-consuming because we have to collect a lot of data and then label it manually.
To check the accuracy and performance of this approach, the researchers categorized five different types of fruits, and they found that when the number of natural training photos is under 50, the default pipeline output was essentially a guess. They emphasized that the advantage of this approach can be seen when the original training image is below 250. The researchers further tested the accuracy of the approach on the fruit classification problem and observed that the approach can reach 98.3% accuracy with no natural training images.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.