How can the Effectiveness of Vision Transformers be Leveraged in Diffusion-based Generative Learning? This Paper from NVIDIA Introduces a Novel Artificial Intelligence Model Called Diffusion Vision Transformers (DiffiT)
How can the effectiveness of vision transformers be leveraged in diffusion-based generative learning? This paper from NVIDIA introduces a novel model called Diffusion Vision Transformers (DiffiT), which combines a hybrid hierarchical architecture with a U-shaped encoder and decoder. This approach has pushed the state of the art in generative models and offers a solution to the challenge of generating realistic images.
While prior models like DiT and MDT employ transformers in diffusion models, DiffiT distinguishes itself by utilizing time-dependent self-attention instead of shift and scale for conditioning. Diffusion models, known for noise-conditioned score networks, offer advantages in optimization, latent space coverage, training stability, and invertibility, making them appealing for diverse applications such as text-to-image generation, natural language processing, and 3D point cloud generation.
Diffusion models have enhanced generative learning, enabling diverse and high-fidelity scene generation through an iterative denoising process. DiffiT introduces time-dependent self-attention modules to enhance the attention mechanism at various denoising stages. This innovation results in state-of-the-art performance across datasets for image and latent space generation tasks.
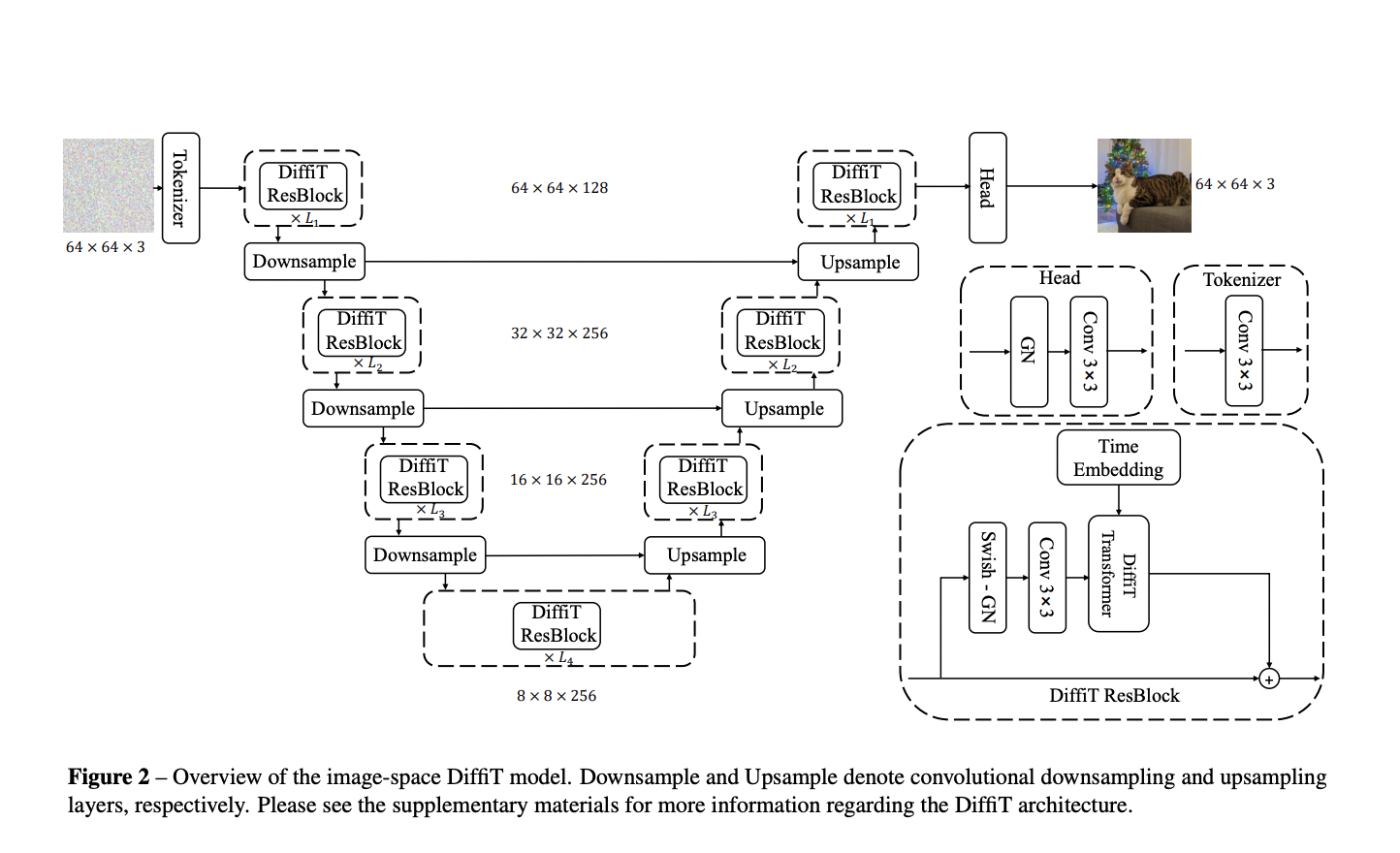
DiffiT features a hybrid hierarchical architecture with a U-shaped encoder and decoder. It incorporates a unique time-dependent self-attention module to adapt attention behavior during various denoising stages. Based on ViT, the encoder uses multiresolution steps with convolutional layers for downsampling. At the same time, the decoder employs a symmetric U-like architecture with a similar multiresolution setup and convolutional layers for upsampling. The study includes investigating classifier-free guidance scales to enhance generated sample quality and testing different scales in ImageNet-256 and ImageNet-512 experiments.
DiffiT has been proposed as a new approach to generating high-quality images. This model has been tested on various class-conditional and unconditional synthesis tasks and surpassed previous models in sample quality and expressivity. DiffiT has achieved a new record in the Fréchet Inception Distance (FID) score, with an impressive 1.73 on the ImageNet-256 dataset, indicating its ability to generate high-resolution images with exceptional fidelity. The DiffiT transformer block is a crucial component of this model, contributing to its success in simulating samples from the diffusion model through stochastic differential equations.
In conclusion, DiffiT is an exceptional model for generating high-quality images, as evidenced by its state-of-the-art results and unique time-dependent self-attention layer. With a new FID score of 1.73 on the ImageNet-256 dataset, DiffiT produces high-resolution images with exceptional fidelity, thanks to its DiffiT transformer block, which enables sample simulation from the diffusion model using stochastic differential equations. The model’s superior sample quality and expressivity compared to prior models are demonstrated through image and latent space experiments.
Future research directions for DiffiT include exploring alternative denoising network architectures beyond traditional convolutional residual U-Nets to enhance effectiveness and potential improvements. Investigation into alternative methods for introducing time dependency in the Transformer block aims to enhance the modeling of temporal information during the denoising process. Experimenting with different guidance scales and strategies for generating diverse and high-quality samples is proposed to improve DiffiT’s performance in terms of FID score. Ongoing research will assess DiffiT’s generalizability and potential applicability to a broader range of generative learning problems in various domains and tasks.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.