How Can We Effectively Compress Large Language Models with One-Bit Weights? This Artificial Intelligence Research Proposes PB-LLM: Exploring the Potential of Partially-Binarized LLMs
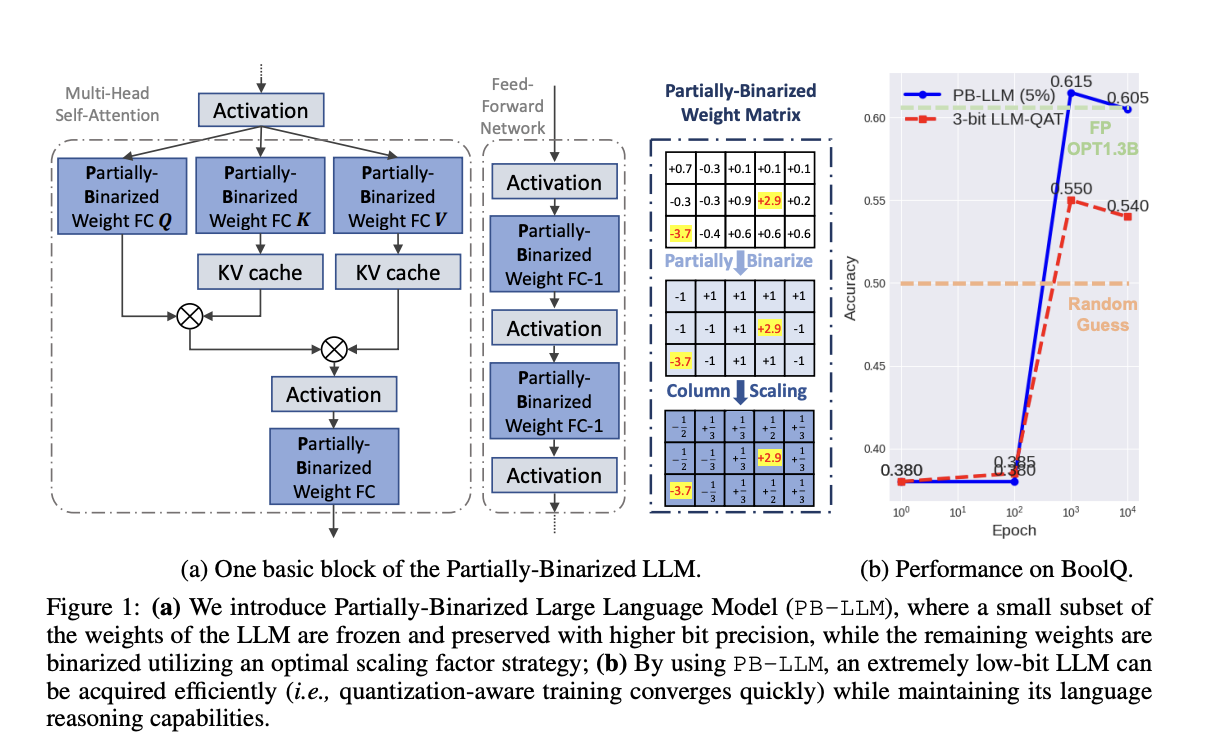
In Large Language Models (LLMs), Partially-Binarized LLMs (PB-LLM) is a cutting-edge technique for achieving extreme low-bit quantization in LLMs without sacrificing language reasoning capabilities. PB-LLM strategically filters salient weights during binarization, reserving them for higher-bit storage. Moreover, it introduces post-training quantization (PTQ) and quantization-aware training (QAT) methods to recover the reasoning capacity of quantized LLMs. This approach represents a significant advancement in network binarization for LLMs.
Researchers from the Illinois Institute of Technology, Huomo AI, and UC Berkeley introduced PB-LLM as an innovative approach for extreme low-bit quantization while preserving language reasoning capacity. Their course addresses the limitations of existing binarization algorithms and emphasizes the significance of salient weights. Their study further explores PTQ and QAT techniques to recover reasoning capacity in quantized LLMs. Their findings contribute to advancements in LLM network binarization, with the PB-LLM code available for further exploration and implementation.
Their method delves into the challenge of deploying LLMs on memory-constrained devices. It explores network binarization, reducing weight bit-width to one bit to compress LLMs. Their proposed approach, PB-LLM, aims to achieve extremely low-bit quantization while preserving language reasoning capacity. Their research also investigates the salient-weight property of LLM quantization and employs PTQ and QAT techniques to regain reasoning capacity in quantized LLMs.
Their approach introduces PB-LLM as an innovative method for achieving extremely low-bit quantization in LLMs while preserving their language reasoning capacity. It addresses the limitations of existing binarization algorithms by emphasizing the importance of salient weights. PB-LLM selectively bins a fraction of salient consequences into higher-bit storage, enabling partial binarization.
PB-LLM selectively binarizes a fraction of these salient weights, assigning them to higher-bit storage. The paper extends PB-LLM’s capabilities through PTQ and QAT methodologies, revitalizing the performance of low-bit quantized LLMs. These advancements contribute significantly to network binarization for LLMs and offer accessible code for further exploration. Their approach explored the viability of binarization techniques for quantizing LLMs. Current binarization algorithms struggle to quantize LLMs, suggesting the necessity for innovative approaches effectively.
Their research underscores the role of salient weights in effective binarization and proposes optimal scaling strategies. The combined use of PTQ and QAT can restore quantized LLM capacities. The provided PB-LLM code encourages research and development in LLM network binarization, particularly in resource-constrained environments.
In conclusion, the paper introduces PB-LLM as an innovative solution for extreme low-bit quantization in LLMs while preserving language reasoning capabilities. It addresses the limitations of existing binarization algorithms and emphasizes the importance of salient weights. PB-LLM selectively binarizes salient weights, allocating them to higher-bit storage. Their research extends PB-LLM through PTQ and QAT methodologies, revitalizing low-bit quantized LLMs’ performance. These advancements significantly contribute to network binarization for LLMs.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.