How Do Large Language Models Perform in Long-Form Question Answering? A Deep Dive by Salesforce Researchers into LLM Robustness and Capabilities
While Large Language Models (LLMs) like ChatGPT and GPT-4 have demonstrated better performance across several benchmarks, open-source projects like MMLU and OpenLLMBoard have quickly progressed in catching up across multiple applications and benchmarks. Understanding their capabilities, constraints, and distinctions becomes more crucial as they enter the new era of LLMs with rapid advancements in new models and methodologies. Although LLMs have demonstrated their ability to generate coherent text in tasks like summarization, more is needed about how well they do on LFQA.
One of the significant problems that still needs to be solved is long-form question answering (LFQA), which has numerous and significant real-world applications (such as support forums, troubleshooting, customer service, etc.). Answering such inquiries frequently calls for complicated thinking skills to comprehend the question and make sense of the material that is dispersed across the original paper. The main points of the articles are condensed into abstract summaries. They assume that follow-up inquiries from these summaries would necessitate a better comprehension of the subjects connecting various sections of the source material. Additionally, other researchers show that responses that call for comprehension of more than a third of a lengthy material are frequently evaluated as “HARD” by people.
Researchers from Salesforce suggest a scalable assessment approach to compare and contrast the differences between huge LLMs and smaller yet successful basic LLMs (such as Llama-7B, 13B) and their distilled counterparts (such as Alpaca-7B, 13B). To do this, they indicate that ChatGPT be instructed explicitly to construct complicated questions from document summaries. Their empirical study reveals that follow-up questions created from summaries present a difficult but more realistic setup for assessing the reasoning skills of LLMs on two fronts (complexity of generated questions and response quality of open-source LLMs). They use GPT-4 to determine the response quality on coherence, relevance, factual consistency, and correctness under earlier works because entirely depending on human review for long-form QA is expensive and challenging to scale. They also do a smaller-scale human evaluation, demonstrating that GPT-4 strongly correlates with human evaluation, making their assessment credible.
The following are their primary conclusions from this study:
• They recommend inferring from lengthier contexts by making numerous runs through the context for > 20% of the time to generate questions from abstractive summaries.
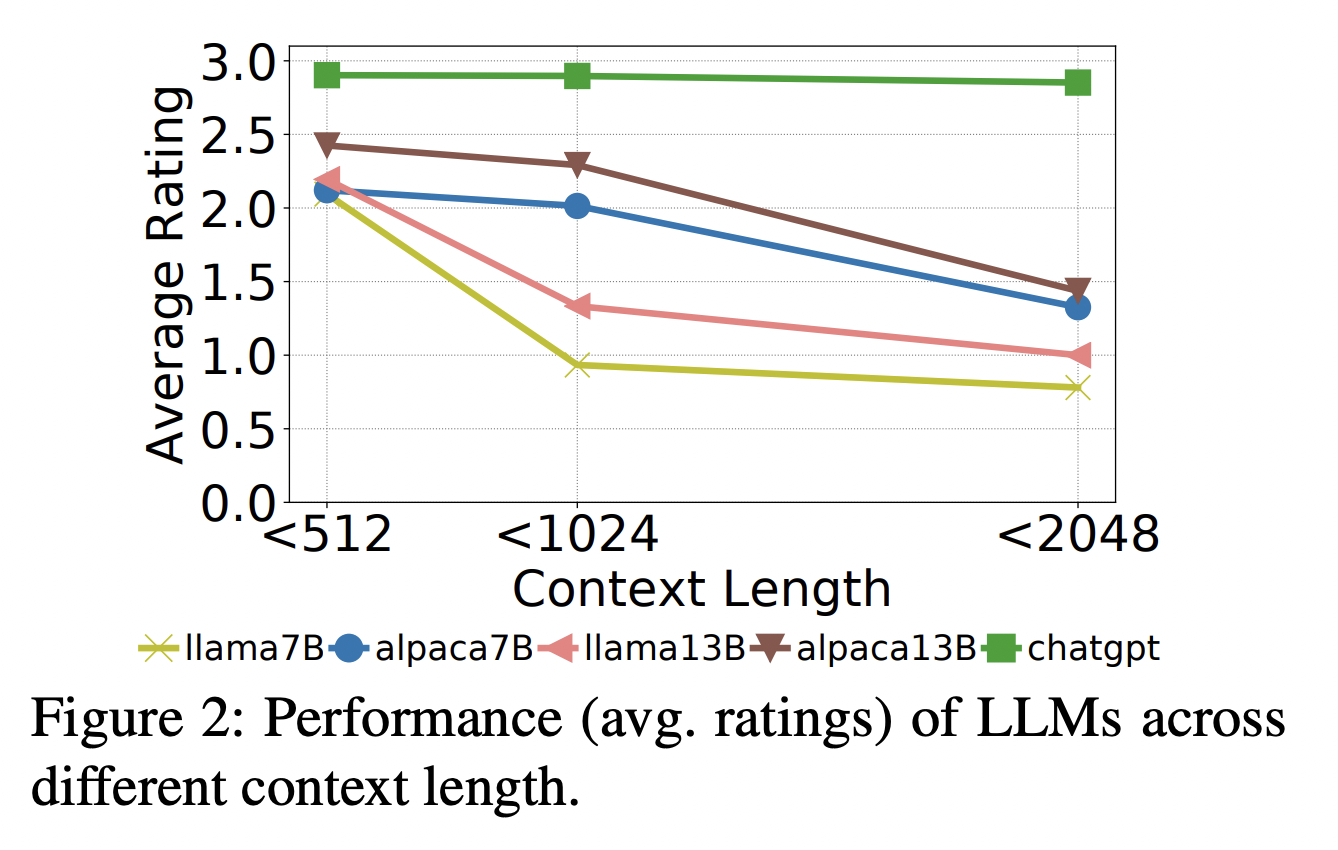
• Distilled LLMs (Alpaca-7B, 13B) often rely less on context when generating questions from the original material, but their ability to create questions from document summaries is greatly reduced.
• For questions derived from summaries (> 16.8%), responses produced by distilled LLMs can be consistent across contexts, but they frequently go off-topic, produce redundant replies, and are only partially accurate.
• Alpaca-7B and 13B are more sensitive to lengthier contexts (>1024 tokens) than base LLMs (Llama), although they typically produce sensible replies.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.