How Large Language Models are Redefining Data Compression and Providing Unique Insights into Machine Learning Scalability? Researchers from DeepMind Introduce a Novel Compression Paradigm
Was this response better or worse?BetterWorseSame
It has been said that information theory and machine learning are “two sides of the same coin” because of their close relationship. One exquisite relationship is the fundamental similarity between probabilistic data models and lossless compression. The essential theory defining this concept is the source coding theorem, which states that the predicted message length in bits of an ideal entropy encoder equals the negative log2 probability of the statistical model. In other words, decreasing the amount of bits needed for each message is comparable to increasing the log2 -likelihood. Different techniques to achieve lossless compression with a probabilistic model include Huffman coding, arithmetic coding, and asymmetric numeral systems.
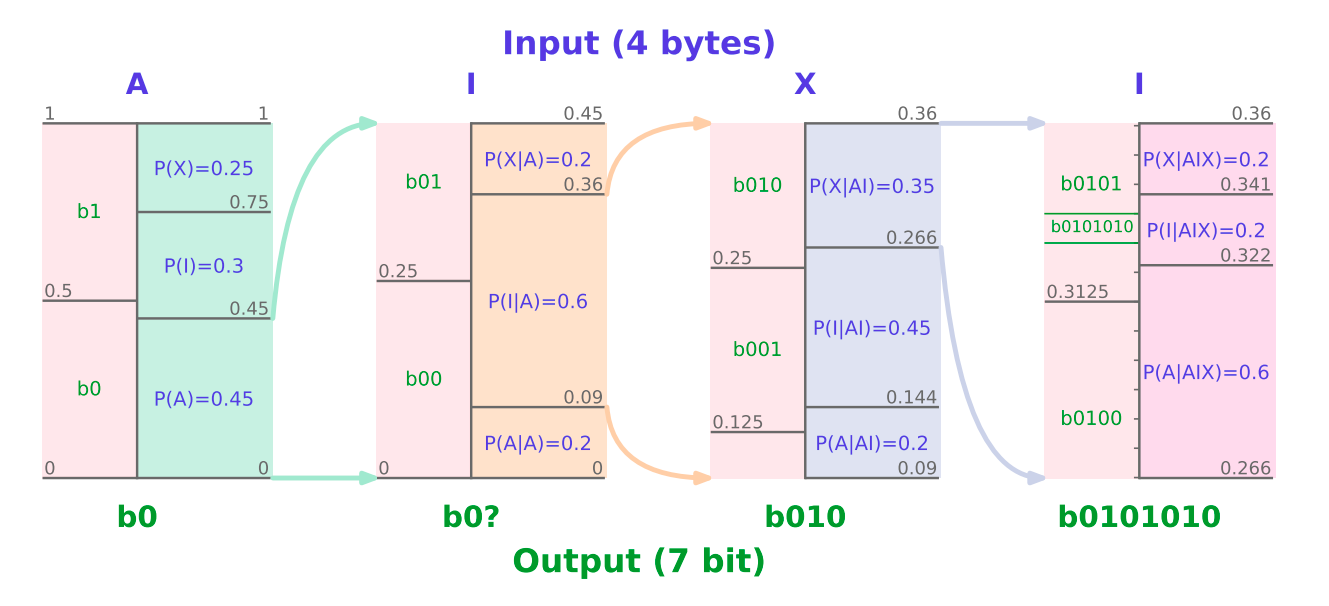
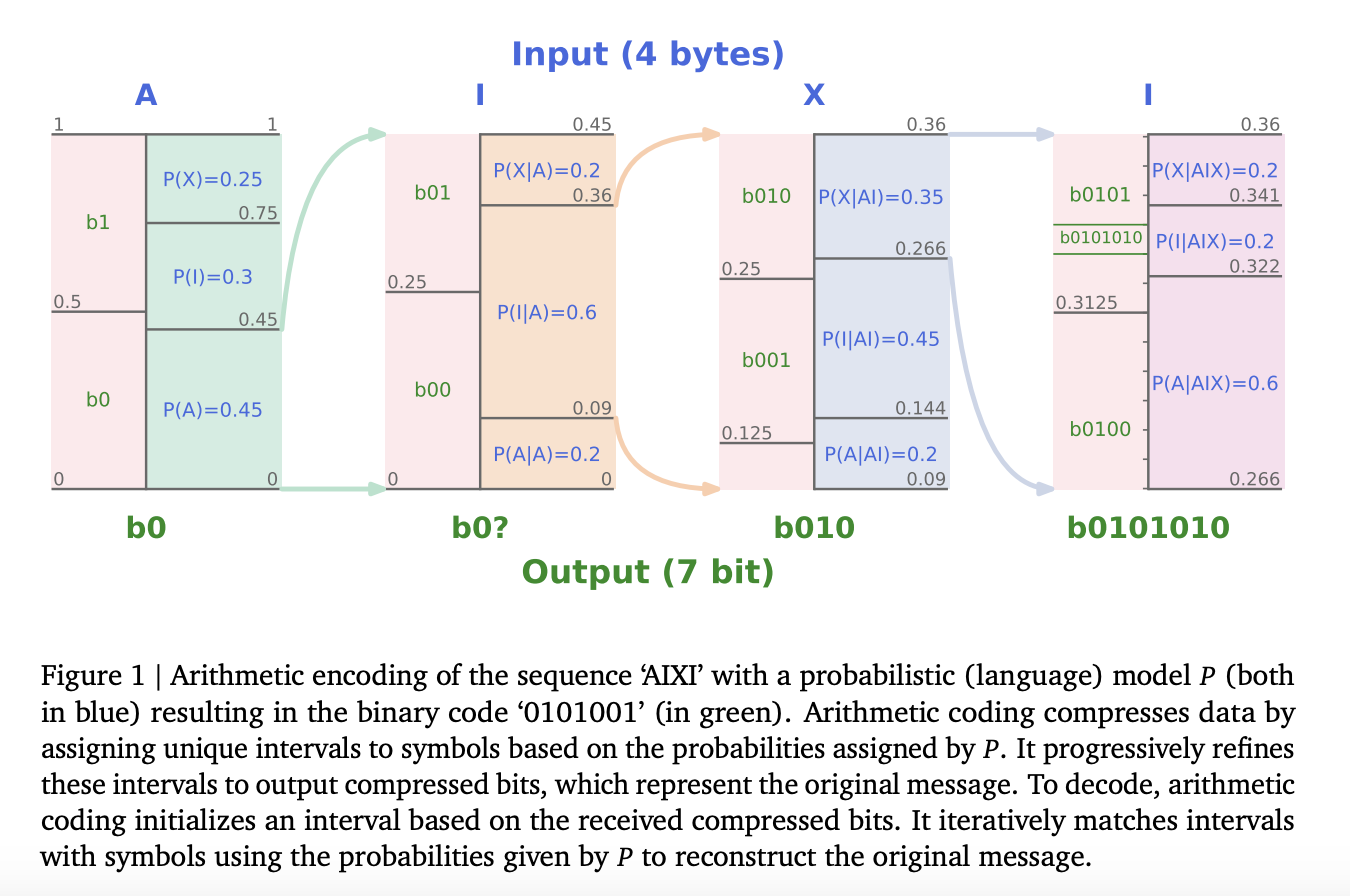
Figure 1 | Arithmetic encoding of the sequence ‘AIXI’ with a probabilistic (language) model P (both in blue) yields the binary code ‘0101001’ (in green). Data is compressed via arithmetic coding by giving symbols certain intervals depending on the probability given by P. It gradually smoothes out these pauses to produce compressed bits that stand in for the original message. Based on the incoming compressed bits, arithmetic coding initializes an interval during decoding. To rebuild the original message, it iteratively matches intervals with symbols using the probabilities provided by P.
The total compression efficiency is dependent on the capabilities of the probabilistic model since arithmetic coding is known to be optimal in terms of coding length (Fig. 1). Furthermore, huge pre-trained Transformers, also known as foundation models, have recently demonstrated excellent performance across a variety of prediction tasks and are thus attractive candidates for use with arithmetic coding. Transformer-based compression with arithmetic coding has generated cutting-edge results in online and offline environments. The offline option they consider in their work involves training the model on an external dataset before using it to compress a (perhaps different) data stream. In the online context, a pseudo-randomly initialized model is immediately trained on the stream of data that is to be compressed. As a result, offline compression uses a fixed set of model parameters and is done in context.
Transformers are perfectly suited for offline reduction since they have shown outstanding in-context learning capabilities. Transformers are taught to compress effectively, as they will describe in this task. Therefore, they need to have strong contextual learning skills. The context length, a critical offline compression limiting factor, determines the maximum number of bytes a model can squeeze simultaneously. Transformers are computationally intensive and can only compress a small amount of data (a “token” is programmed with 2 or 3 bytes). Since many difficult predicting tasks (such as algorithmic reasoning or long-term memory) need extended contexts, extending the context lengths of these models is a significant issue that is receiving more attention. The in-context compression view sheds light on how the present foundation models fail. Researchers from Google DeepMind and Meta AI & Inria promote using compression to explore the prediction problem and assess how well big (foundation) models compress data.
They make the following contributions:
• They do empirical research on the foundation models’ capacity for lossless compression. To that purpose, they explore arithmetic coding’s role in predictive model compression and draw attention to the relationship between the two fields of study.
• They demonstrate that foundation models with in-context learning capabilities, trained mostly on text, are general-purpose compressors. For instance, Chinchilla 70B outperforms domain-specific compressors like PNG (58.5%) or FLAC (30.3%), achieving compression rates of 43.4% on ImageNet patches and 16.4% on LibriSpeech samples.
• They present a fresh perspective on scaling laws by demonstrating that scaling is not a magic fix and that the size of the dataset sets a strict upper limit on model size in terms of compression performance.
• They use compressors as generative models and use the compression-prediction equivalence to represent the underlying compressor’s performance graphically.
• They show that tokenization, which can be thought of as a pre-compression, does not, on average, improve compression performance. Instead, it enables models to increase the information content in their environment and is typically used to enhance prediction performance.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.