How Should We Store AI Images? Google Researchers Propose an Image Compression Method Using Score-based Generative Models

A year ago, generating realistic images with AI was a dream. We were impressed by seeing generated faces that resemble real ones, despite the majority of outputs having three eyes, two noses, etc. However, things changed quite rapidly with the release of diffusion models. Nowadays, it is difficult to distinguish an AI-generated image from a real one.
The ability to generate high-quality images is one part of the equation. If we were to utilize them properly, efficiently compressing them plays an essential role in tasks such as content generation, data storage, transmission, and bandwidth optimization. However, image compression has predominantly relied on traditional methods like transform coding and quantization techniques, with limited exploration of generative models.
Despite their success in image generation, diffusion models and score-based generative models have not yet emerged as the leading approaches for image compression, lagging behind GAN-based methods. They often perform worse or on par with GAN-based approaches like HiFiC on high-resolution images. Even attempts to repurpose text-to-image models for image compression have yielded unsatisfactory results, producing reconstructions that deviate from the original input or contain undesirable artifacts.
The gap between the performance of score-based generative models in image generation tasks and their limited success in image compression raises intriguing questions and motivates further investigation. It is surprising that models capable of generating high-quality images have not been able to surpass GANs in the specific task of image compression. This discrepancy suggests that there may be unique challenges and considerations when applying score-based generative models to compression tasks, necessitating specialized approaches to harness their full potential.
So we know there is a potential for using score-based generative models in image compression. The question is, how can it be done? Let us jump into the answer.
Google researchers proposed a method that combines a standard autoencoder, optimized for mean squared error (MSE), with a diffusion process to recover and add fine details discarded by the autoencoder. The bit rate for encoding an image is solely determined by the autoencoder, as the diffusion process does not require additional bits. By fine-tuning diffusion models specifically for image compression, it is shown that they can outperform several recent generative approaches in terms of image quality.

The method explores two closely related approaches: diffusion models, which exhibit impressive performance but require a large number of sampling steps, and rectified flows, which perform better when fewer sampling steps are allowed.
The two-step approach consists of first encoding the input image using the MSE-optimized autoencoder and then applying either the diffusion process or rectified flows to enhance the realism of the reconstruction. The diffusion model employs a noise schedule that is shifted in the opposite direction compared to text-to-image models, prioritizing detail over global structure. On the other hand, the rectified flow model leverages the pairing provided by the autoencoder to directly map autoencoder outputs to uncompressed images.
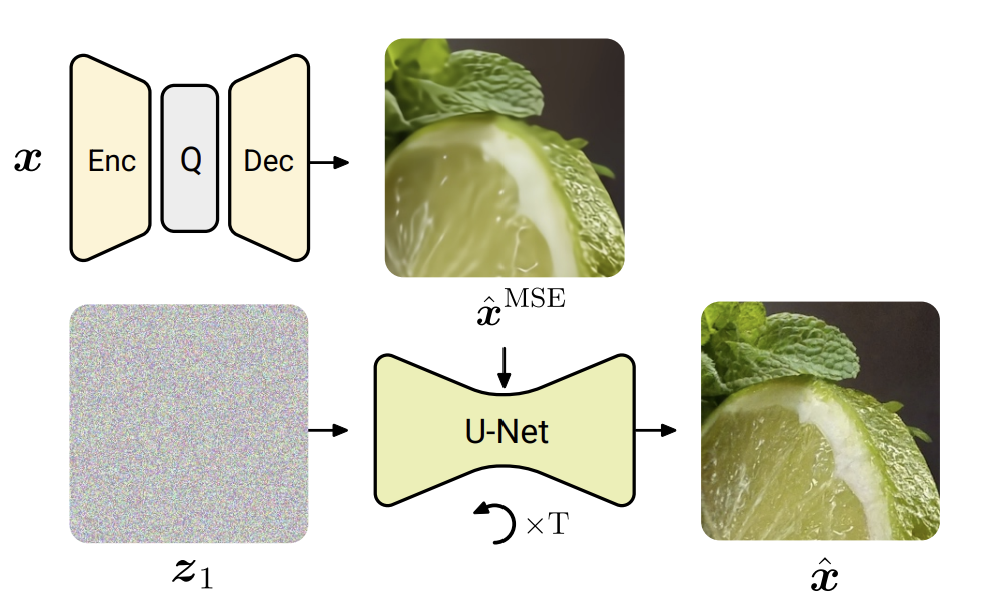
Moreover, the study revealed specific details that can be useful for future research in this domain. For example, it is shown that the noise schedule and the amount of noise injected during image generation significantly impact the results. Interestingly, while text-to-image models benefit from increased noise levels when training on high-resolution images, it is found that reducing the overall noise of the diffusion process is advantageous for compression. This adjustment allows the model to focus more on fine details, as the coarse details are already adequately captured by the autoencoder reconstruction.
Check Out The Paper. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
Credit: Source link
Comments are closed.