How to Instruction Tune Code LLMs without GPT4 Data? Meet OctoPack: A Set of AI Models for Instruction Tuning Code Large Language Models
It has been demonstrated that the usability and overall performance of large language models (LLMs) can be enhanced by fine-tuning various language tasks provided via instructions (instruction tuning). Models trained with visual, auditory, and multilingual data have all fared well with the instruction tuning paradigm.
Code-learning machines are taught by researchers how to code. Indirectly instructing Code LLMs to generate desired code using code comments is possible, but the process is fragile and fails when the desired result is natural language. Code LLMs’ steerability could be enhanced, and their applicability could be broadened by explicit instructive tuning.
Researchers prefer to use open-source models to produce synthetic data and avoid utilizing data with restrictive licenses. They compare four common databases of code instructions:
- xP3x, which compiles results from widely used code benchmarks
- A lax Code LLM enables Independent data generation by scholars.
- OASST is primarily a repository of linguistic information with minimal coding examples.
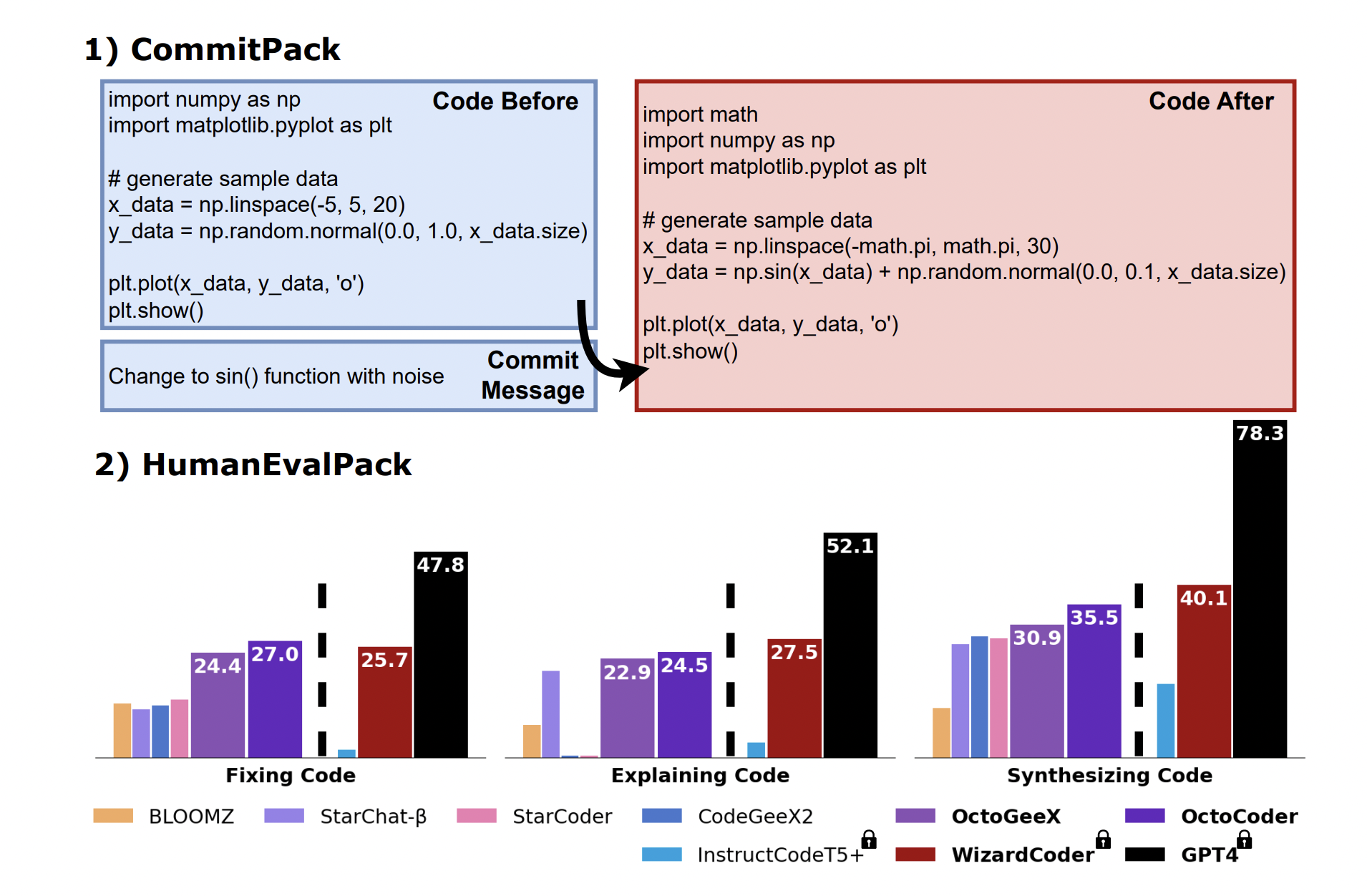
- The brand new 4TB trove of Git commits, dubbed COMMITPACK.
Researchers’ contributions
- For pre-training, you have access to 4 terabytes (TB) of code commits written in 350 different programming languages under a permissive license; tuning gives you access to a filtered variant of COMMITPACK containing high-quality code instructions.
- Code LLM Generalization Benchmark (HUMANEVALPACK) for Six Programming Languages (Python, JavaScript, Java, Go, C++, and Rust) and Three Scenarios (Code Repair, Code Explanation, and Code Synthesis).
- The most lenient Code LLMs are OCTOCODER and OCTOGEEX.
Researchers use the action dump of GitHub commits on Google BigQuery as the basis for their dataset. To guarantee that commit messages are very specific and to avoid additional complexity from dealing with many files, they employ several quality filters, filter for commercially friendly licensing, and delete all commits that affect more than one file. The impacted GitHub source code files are extracted before and after the commit using the filtered information.
For tasks that need a natural language (NL) response, the input for instruction tuning LLMs is an NL instruction with optional NL context. When tuning instructions with code data, the code may be included only in the input, the output, or both the input and the output alongside the NL instruction. Although most existing benchmarks focus on code synthesis variants, customers may desire to employ models in all three cases. As a result, the three input-output permutations for six languages are now included in the code synthesis benchmark HumanEval.
In all three evaluation circumstances, OCTOCODER outperforms all other permissive models by a significant margin. OCTOGEEX has the fewest parameters of any model benchmarked at 6 billion, but it still achieves the best results compared to other permissive Code LLMs. When compared to other models, GPT-4 has the highest performance. Despite being a probable larger model than others, GPT-4 is closed-source.
Everything required, including code, models, and data, may be found at https://github.com/bigcode-project/octopack
To sum it up, large language models (LLMs) benefit greatly from being fine-tuned on instructions, allowing them to perform better on various natural language tasks. Researchers use coding to fine-tune human instructions, using the innate structure of Git commits to pair code changes with human guidance. Four terabytes of Git commits from 350 different languages are compiled into COMMITPACK. For the StarCoder model with 16B parameters, they compare COMMITPACK to other natural and synthetic code instructions. For the HumanEval Python test, they reach state-of-the-art performance among models not trained on OpenAI outputs. In addition, they present HUMANEVALPACK, which adds support for six additional programming languages (Python, JavaScript, Java, Go, C++, and Rust) and three new coding tasks (Code Repair, Code Explanation, and Code Synthesis) to the HumanEval benchmark. The models, OCTOCODER and OCTOGEEX, show the benefits of COMMITPACK by providing the best performance throughout HUMANEVALPACK among all permissible models.
Check out the Paper and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.