How to Keep Foundation Models Up to Date with the Latest Data? Researchers from Apple and CMU Introduce the First Web-Scale Time-Continual (TiC) Benchmark with 12.7B Timestamped Img-Text Pairs for Continual Training of VLMs
A paradigm change in multimodal learning has occurred thanks to the contributions of large multimodal foundation models like CLIP, Flamingo, and Stable Diffusion, enabling previously unimaginable improvements in image generation and zero-shot generalization. These baseline models are generally trained on big, web-scale, static datasets. Whether or not legacy models, like OpenAI’s CLIP models, which were trained on internet-scale data up to 2020, will function on future data is unknown.
To start, researchers from Apple and Carnegie Mellon University examine how OpenAI’s CLIP models stack up against those in the OpenCLIP repository that were developed using more up-to-date curated web datasets that include data through 2022 in terms of their robustness. Due to the lack of a standard against which CLIP models can be measured, they have compiled a set of dynamic classification and retrieval tasks covering 2014–2022. While OpenCLIP models maintain their performance, the team discovered that OpenAI models show a substantial disparity in retrieval performance on data from 2021-2022 compared with 2014-2016. While OpenAI’s CLIP models are marginally more robust than OpenCLIP models, this is not fully reflected in typical tests like accuracy on ImageNet distribution shifts.
Their work reveals that using static benchmarks (like ImageNet) has its limitations and that models need to adapt and evolve in tandem with shifting distributions of data. One simplistic but frequent method of accommodating changing data is to start again whenever they get a fresh set of image-text data and train a new CLIP model. The reasoning behind this method is that it is more challenging to adapt a model’s behavior to new input when training is initiated from an already existing model. However, it is impractical to repeatedly invest the time and energy required to train new foundation models from the start.
Recent efforts focusing on perpetual learning techniques for CLIP models have mostly aimed to boost efficiency in a single downstream task or a small number of tasks. Although some recent research has begun to tackle these issues, current benchmarks are either too modest in scope or lack linked image-text data to be truly useful.
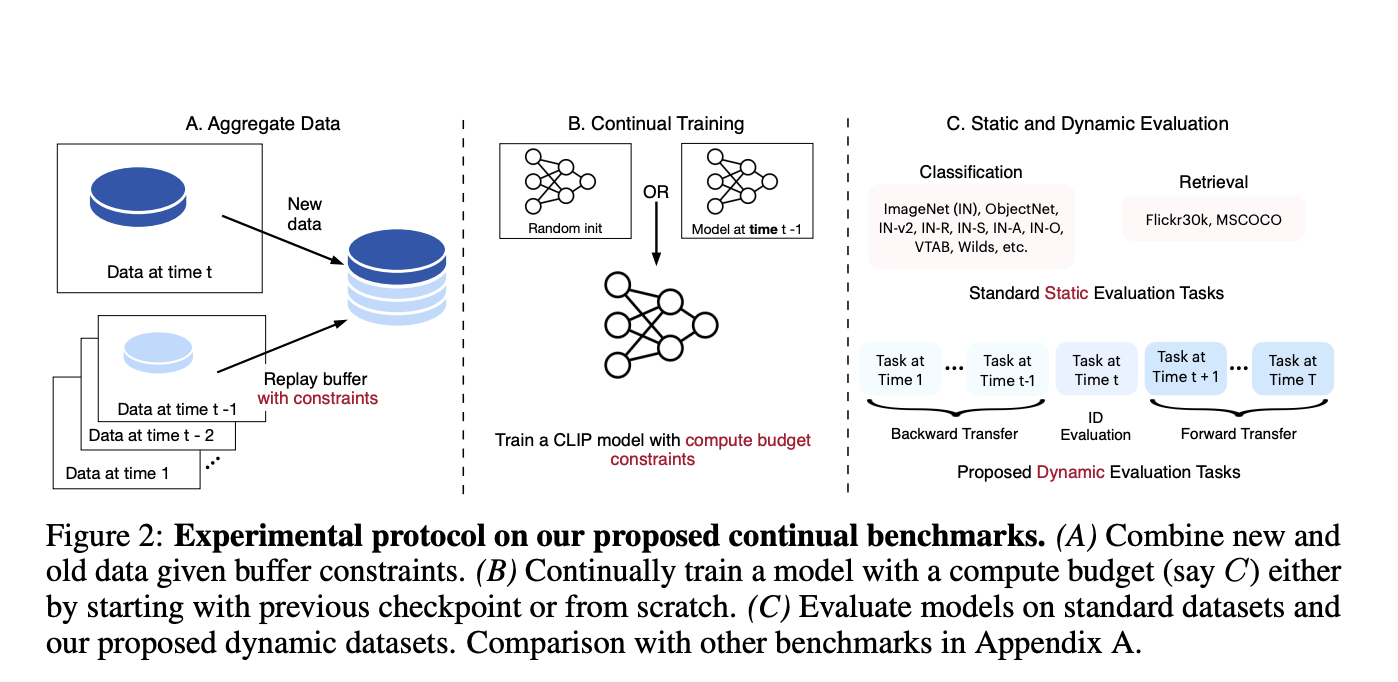
As a first step toward Time-Continuous (TIC) training of CLIP models, the researchers observe the natural change in data distribution over time. By including “crawl time” data in the already-existing CommonPool dataset, they establish TIC-DataComp as a new benchmark for the Time-Continual training of CLIP models. The researchers also recycle large-scale datasets from the internet, collected from places like Reddit and Flickr, for new purposes. In particular, they use the time information provided by YFCC and Redcaps to curate TIC-YFCC and TICRedCaps, respectively. Whenever a new data set becomes available, this work aims to build continuous learning techniques that can function within a limited computational budget. These strategies go against Oracle, which resets its training parameters whenever new data is received and spends its cumulative computing budget on a brand-new model.
The researchers conduct a zero-shot evaluation of models trained in the TIC-CLIP framework using a battery of 28 well-established classification and retrieval tasks, such as ImageNet, ImageNet distribution shifts, and Flickr. Finally, using their benchmarks, they design and test a variety of continuous learning approaches, including replay buffers, learning rate schedules, and other types of checkpoints (such as warm start, patching, and distillation).
The team draws an important lesson that by starting training at the most recent checkpoint and replaying all historical data, the cumulative technique delivers performance on par with an Oracle at 2.7x the computing efficiency. They also get significant insights into learning rate schedules for sequential training and show interesting trade-offs between buffer sizes for static and dynamic performance. Their findings are consistent across dimensions and techniques, highlighting trends from datasets ranging from 11M samples to 3B. The code and timing data collected on top of existing datasets will soon be made public so the wider community can use the proposed benchmarks. The team hopes that by shedding light on this underexplored topic, their work may pave the way for continuous training of foundation models.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.