How to Keep Scaling Large Language Models when Data Runs Out? A New AI Research Trains 400 Models with up to 9B Parameters and 900B Tokens to Create an Extension of Chinchilla Scaling Laws for Repeated Data
Large Language Models (LLMs), the deep learning-based highly efficient models, are the current trend in the Artificial Intelligence community. The well-known chatbot developed by OpenAI, ChatGPT, is based on GPT architecture and has millions of users utilizing its abilities for content generation. Its incredible performance in imitating humans by generating the content, summarizing long paragraphs, translating languages, etc., is leading to its inclusion in almost every field.
The most popular way for scaling a Large Language Model has been growing both the number of parameters and the size of the training dataset. But considering the volume of text data on the internet, this way may eventually constrain this progress. To address this, the researchers have studied certain approaches to scale language models in data-constrained environments, thus finding an answer to how to keep scaling LLMs when data runs out.
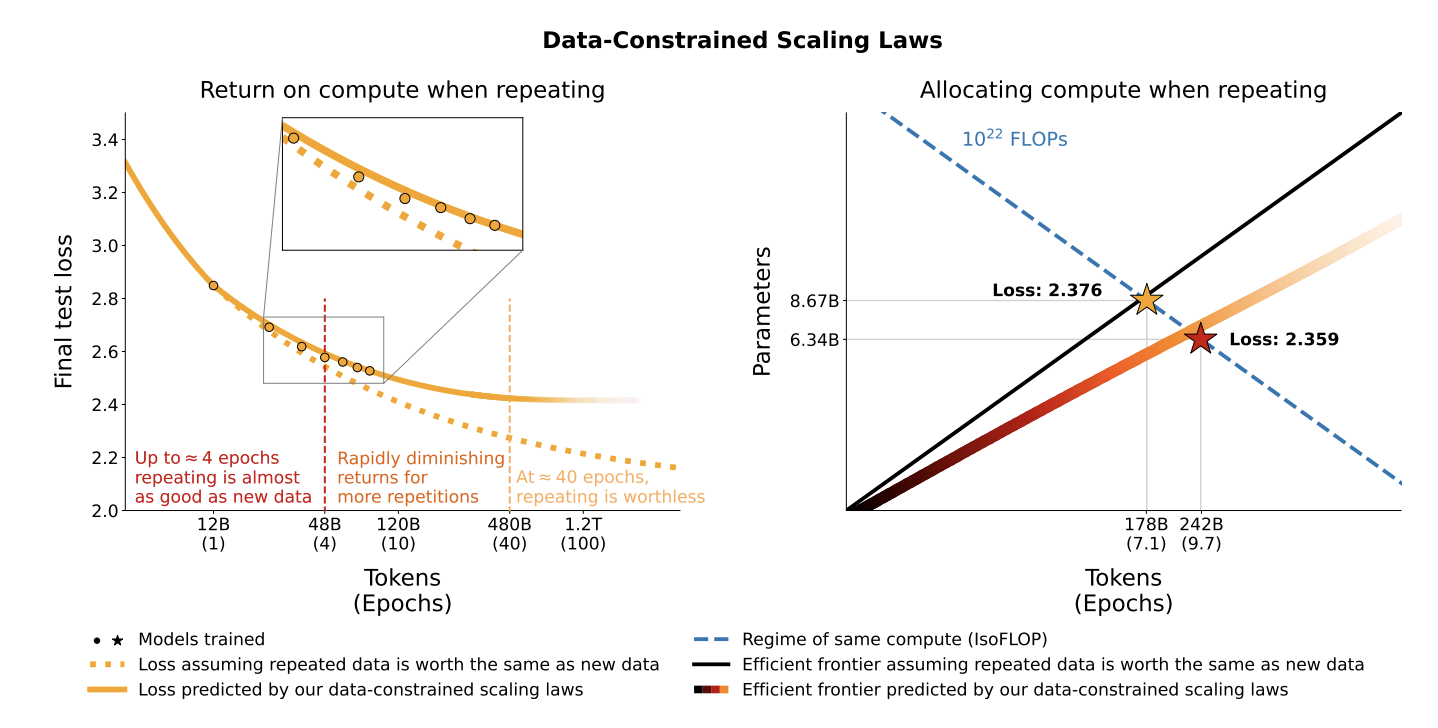
The researchers have run various trials with different amounts of data repetition and compute budget while training the models in the experiments using up to 900 billion training tokens and 9 billion parameters. The results showed that training with up to 4 epochs of repeated data had less effect on loss compared to training with unique data when data was confined, and the compute budget was fixed. However, the value of adding more compute resources decreased to zero as the amount of repeated data grew.
The researchers devised and empirically tested a scaling law for optimality computing and solving the problem of data scarcity, which considers how repeated tokens and extra parameters lose value over time. It offers guidance on how to allocate computing resources when working with little data optimally. The study has resulted in two approaches for reducing data scarcity: adding code data to the training dataset and removing common filters. The researchers combined coding data with natural language data to maximize the number of useful tokens available for training. They discovered that including code data significantly increased the number of effective tokens, even when solely evaluating natural language problems.
The researchers have observed that improved performance might be obtained by training smaller models on more data instead of training larger models with a set quantity of compute resources. This was shown by contrasting the performance of two models: the Chinchilla model, which has 70 billion parameters, and the Gopher model, which has 280 billion parameters. The Chinchilla model outperformed the Gopher model while utilizing the same computing budget since it was trained on four times as much data. According to the ‘Chinchilla scaling laws,’ which were developed as a result of this observation, even larger models, such as the 530-billion-parameter MT-NLG model, would necessitate 11 trillion tokens worth of training data.
The team has tested several data filtering techniques as well. They looked at the consequences of removing common filters and discovered that data filtering was especially useful for noisy datasets, increasing the accuracy upstream. In conclusion, this is a great study on scaling Large Language Models when data runs out.
Check out the Paper and Github. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com.
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.