Huawei Researchers Develop Pangu-Σ: A Large Language Model With Sparse Architecture And 1.085 Trillion Parameters
Large Language Models (LLMs) have exhibited exceptional skills and potential in natural language processing, creation, and reasoning. By employing a large quantity of textual data, the performance of language models scales up with compute budget and model parameters, displaying significant zero/few-shot learning skills or even emerging abilities. Since GPT-3, several big language models have been developed and published, including the Megatron-Turing NLG, PanGu, ERNIE 3.0 Titan, Gopher, PaLM, OPT, Bloom, and GLM-130B. With more than one trillion parameters, researchers have begun constructing ever bigger language models. Generally, sparsely-activated models like Mixture-of-Experts (MoE) are used to achieve this.
Several notable works among the trillion-parameter models are available, including Switch-C, GLaM, MoE-1.1T, Wu Dao 2.0, and M6-10T. Unfortunately, only a chosen number have achieved the expected performance while publishing thorough assessment findings across various jobs. According to their observations, scaling efficiency is the main challenge. Current research on the scaling laws of language models shows that for LLMs to function at their best, there must be an adequate amount of training data and a reasonable computing budget. Designing a scalable model architecture and an effective distributed training system that can ingest the data with high training throughput is, therefore, one of the key motivations for this effort.
• Scaling the model: LLM model performance is anticipated to increase as the model size grows. Sparse architectures like a Mixture of Experts (MoE) are an intriguing option to scale the model size up without incurring a linear rise in computational cost compared to the high computational price for training dense Transformer models. Yet, issues such as an imbalanced workload and global communication delay plague MoE models. Also, there are still unresolved issues with adding MoE to an existing dense model and how many experts to place in each layer. Thus, developing a trillion-parameter sparse model with good performance and training efficiency is a critical but difficult challenge.
• Scaling the system: It has been suggested to use frameworks like DeepSpeed 4 to enable training models with a trillion parameters. The primary constraint is frequently a constrained compute budget, or more precisely, the number of accelerating devices (such as GPU, NPU, and TPU) that may be employed. Practitioners may train trillion-parameter models with workable batch sizes using tensor parallelism, pipeline parallelism, zero redundancy optimizer, and rematerialization over thousands of accelerating devices. By using heterogeneous computing strategies, such as shifting a portion of the processing to host machines, practitioners can minimize the number of computing resources.
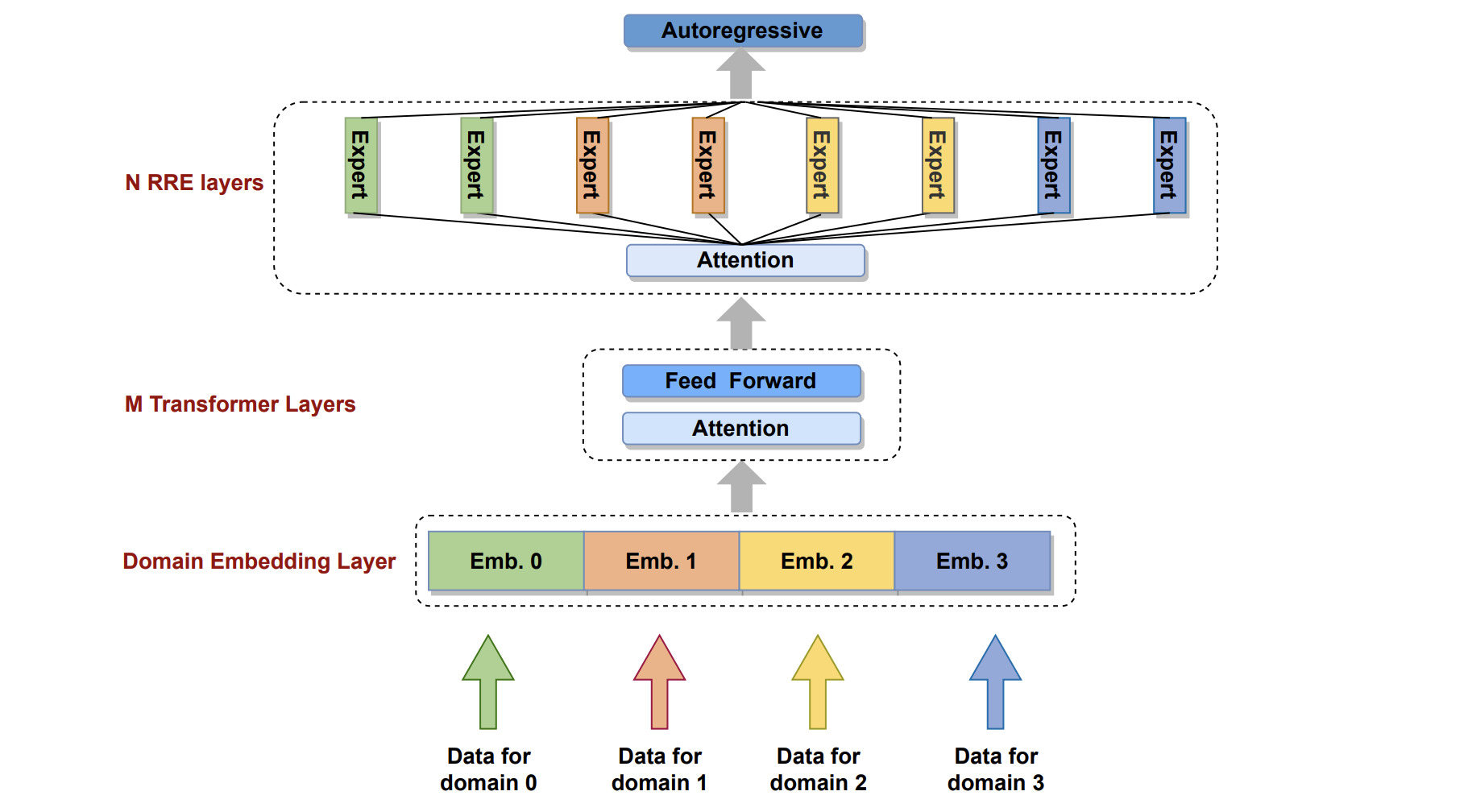
However, the poor bandwidth between the host and device and the CPUs’ limited computational power compared to accelerating devices make it impossible to feed big language models with a sufficient quantity of data and achieve optimal performance using the present methodologies. Consequently, the effectiveness of big language models depends on how to scale the system performance with a restricted computing budget. In this paper, researchers from Huawei introduce Pangu-Σ a large language model with sparse architecture and 1.085 trillion parameters. They create the Pangu-Σmodel within the MindSpore 5 framework and train it over 100 days on a cluster using 512 Ascend 910 AI Accelerators and 329 billion tokens.
PanGu’s built-in parameters are expanded using Random Routed Experts’ Transformer decoder architecture (RRE). RRE uses two levels of routing as opposed to traditional MoE. Experts are organized by task or domain at the first level, and tokens are evenly and randomly assigned to each group at the second level without using any learnable gating functions as in MoE. Using the RRE architecture, it is simple to extract sub-models from the Pangu-Σ for various downstream applications, including conversation, translation, code production, and interpreting natural language in general.
They suggest the Expert Computation and Storage Separation (ECSS) mechanism to make training systems efficient and scalable. This mechanism achieves 69905 tokens/s observed throughput in training 1.085 trillion Pangu-Σ on a cluster of 512 Ascend 910 accelerators and significantly reduces host-to-device and device-to-host communication as optimizer update computation. Overall, the training throughput is 6.3 times faster than it was for the model with the MoE architecture but with the same hyperparameters.
The sub-modal of Pangu-Σ in the Chinese domain significantly outperforms the previous SOTA models, including Pangu-Σ with 13B parameters and ERNIE 3.0 Titan with 260B parameters over 16 downstream tasks in six categories in the zero-shot setting without any multitask finetuning or instruction tuning. The Pangu-Σ model performs better in the relevant regions than the SOTA models. It uses 329B tokens in more than 40 natural and programming languages. Moreover, they evaluate how well Pangu-Σ has been tweaked in several application domains, including conversation, machine translation, and code production.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.