Huawei Researchers Tries to Rewrite the Rules with PanGu-π Pro: The Dawn of Ultra-Efficient, Tiny Language Models Is Here!
A groundbreaking study conducted by researchers from Huawei Noah’s Ark Lab, in collaboration with Peking University and Huawei Consumer Business Group, presents a transformative approach to developing tiny language models (TLMs) suitable for mobile devices. Despite their reduced size, these compact models aim to deliver performance on par with their larger counterparts, addressing the crucial need for efficient AI applications in resource-constrained environments.
The research team tackled the pressing challenge of optimizing language models for mobile deployment. Traditional large language models, while powerful, could be more practical for mobile use due to their substantial computational and memory requirements. This study introduces an innovative tiny language model, PanGu-π Pro, which leverages a meticulously designed architecture and advanced training methodologies to achieve remarkable efficiency and effectiveness.
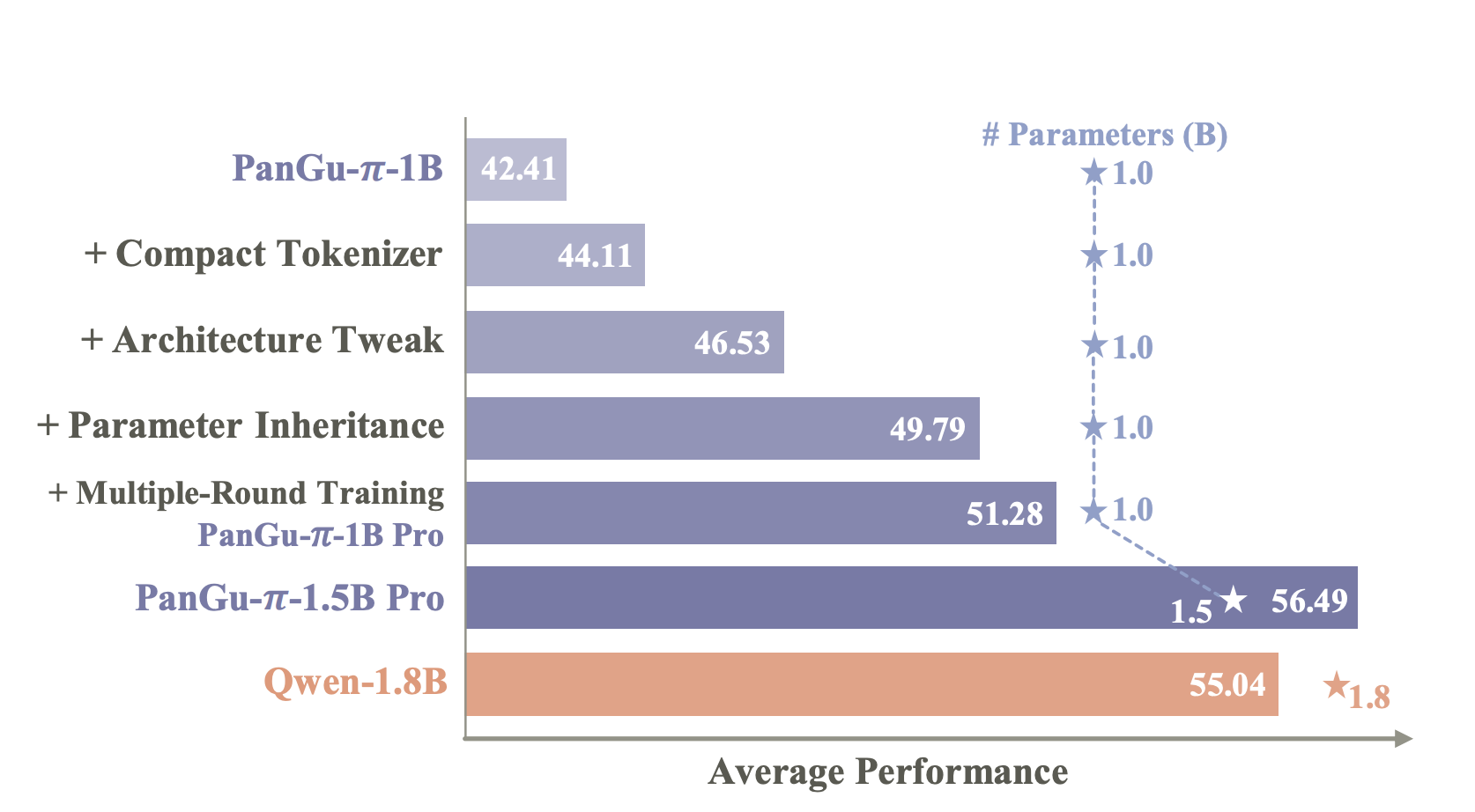
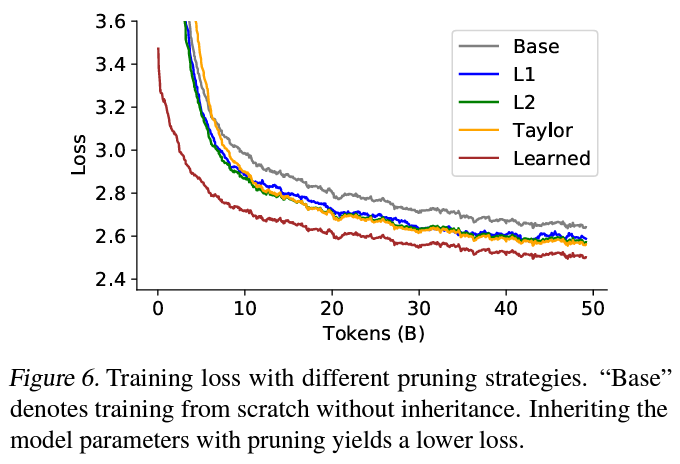
At the core of their methodology is a strategic optimization of the model’s components. The team embarked on a series of empirical studies to dissect the impact of various elements on the model’s performance. A notable innovation is the compression of the tokenizer, significantly reducing the model’s size without compromising its ability to understand and generate language. Furthermore, architectural adjustments were made to streamline the model, including parameter inheritance from larger models and a multi-round training strategy that enhances learning efficiency.
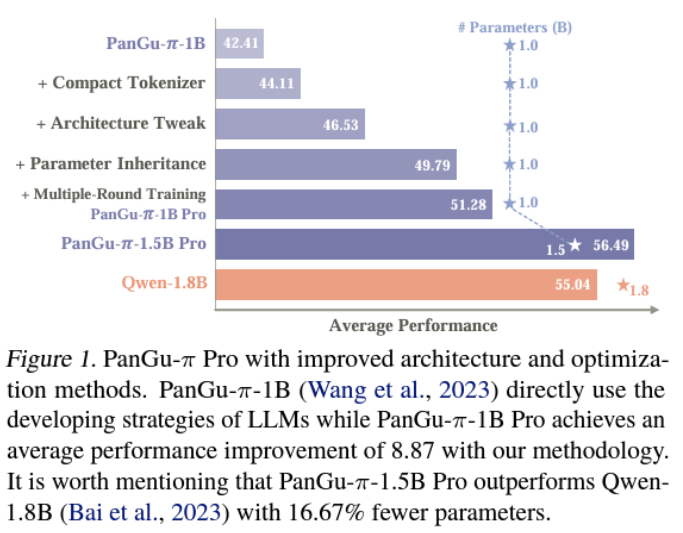
The introduction of PanGu-π Pro in 1B and 1.5B parameter versions marks a significant leap forward. Following the newly established optimization protocols, the models were trained on a 1.6T multilingual corpus. The results were astounding; PanGu-π-1B Pro demonstrated an average improvement of 8.87 on benchmark evaluation sets. More impressively, PanGu-π-1.5B Pro surpassed several state-of-the-art models with larger sizes, establishing new benchmarks for performance in compact language models.
The implications of this research extend far beyond the realm of mobile devices. By achieving such a delicate balance between size and performance, the Huawei team has opened new avenues for deploying AI technologies in various scenarios where computational resources are limited. Their work not only paves the way for more accessible AI applications but also sets a precedent for future research in optimizing language models.
This study’s findings are a testament to the possibilities inherent in AI, showcasing how innovative approaches can overcome the limitations of current technologies. The Huawei team’s contributions are poised to revolutionize how we think about and interact with AI, making it more ubiquitous and integrated into our daily lives. As we progress, the principles and methodologies developed in this research will undoubtedly influence the evolution of AI technologies, making them more adaptable, efficient, and accessible to all.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.