Hugging Face Researchers Introduce Distil-Whisper: A Compact Speech Recognition Model Bridging the Gap in High-Performance, Low-Resource Environments
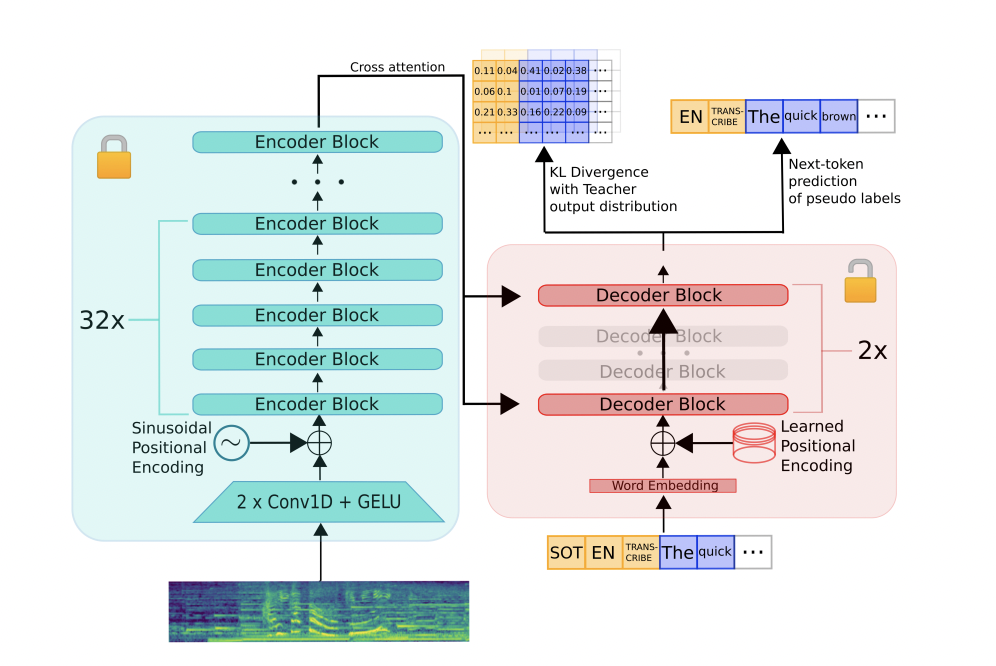
Hugging Face researchers have tackled the issue of deploying large pre-trained speech recognition models in resource-constrained environments. They accomplished this by creating a substantial open-source dataset through pseudo-labelling. The dataset was then utilised to distil a smaller version of the Whisper model, called Distil-Whisper.
The Whisper speech recognition transformer model was pre-trained on 680,000 hours of noisy internet speech data. It comprises transformer-based encoder and decoder components and achieves competitive results in a zero-shot scenario without fine-tuning. Distil-Whisper is a compact version derived through knowledge distillation using pseudo-labelling. Distil-Whisper upholds the Whisper model’s resilience in challenging acoustic conditions while mitigating hallucination errors in long-form audio. The research introduces a large-scale pseudo-labelling method for speech data, an underexplored yet promising avenue for knowledge distillation.
Automatic Speech Recognition (ASR) systems have reached human-level accuracy but face challenges due to the growing size of pre-trained models in resource-constrained environments. The Whisper, a large pre-trained ASR model, excels in various datasets but could be more practical for low-latency deployment. While knowledge distillation has compressed NLP transformer models effectively, its use in speech recognition is underexplored.
The proposed approach utilises pseudo-labelling to construct a sizable open-source dataset, facilitating knowledge distillation. To ensure training quality, a WER heuristic is employed for selecting optimal pseudo-labels. The knowledge distillation objective involves a combination of Kullback-Leibler divergence and pseudo-label terms, introducing a mean-square error component to align the student’s hidden layer outputs with the teacher’s. This distillation technique is applied to the Whisper model within the Seq2Seq ASR framework, ensuring uniform transcription formatting and offering sequence-level distillation guidance.
Distil-Whisper, derived from knowledge distillation, significantly enhances speed and reduces parameters compared to the original Whisper model while retaining resilience in challenging acoustic conditions. It boasts a 5.8x speedup with a 51% parameter reduction, achieving less than a 1% WER on out-of-distribution test data in a zero-shot scenario. The distil-medium.en model has a slightly higher WER but exhibits a 6.8x more immediate inference and 75% model compression. The Whisper model is susceptible to hallucination errors in long-form audio transcription, while Distil-Whisper mitigates these errors while maintaining competitive WER performance.
In conclusion, Distil-Whisper is a compact variant of the Whisper model achieved through knowledge distillation. This innovative approach yields remarkable benefits in terms of speed and parameter reduction, with Distil-Whisper being faster and having fewer parameters compared to the original Whisper model. The distil-medium.en model offers more immediate inference and substantial model compression despite a slightly higher WER.
Future research opportunities in audio domain knowledge distillation and pseudo-labelling for compressing transformer-based models in speech recognition are promising. Investigating the effects of various filtering methods and thresholds on transcription quality and downstream model performance can offer valuable insights for optimising knowledge distillation. Exploring alternative compression techniques, including layer-based methods and using mean-square error terms, may lead to even greater model compression without sacrificing performance. The provision of training code, inference code, and models in this work can be a valuable resource for further research and experimentation in knowledge distillation for speech recognition.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.