Hugging Face Transformers Gets Its First Text-to-Speech Model With The Addition of SpeechT5
The world of AI has drastically transformed the day-to-day lives of humans. Features like voice recognition have made it relatively more straightforward to perform tasks like note-taking, typing documents, etc. The fact that voice recognition is faster is what makes it highly efficient. With the development of AI, voice recognition applications have expanded quickly. Virtual assistants like Google, Alexa, and Siri implement voice recognition software to interact with users. Similarly, features like text-to-speech, speech-to-text, and text-to-text have also gained popularity with varying applications.
Encouraged by the outstanding performance of T5 (Text-To-Text Transfer Transformer) in pre-trained natural language processing models, scientists proposed a unified-model SpeechT5 framework that explores the encoder-decoder pre-training for self-supervised speech/text
representation learning. SpeechT5 is offered in Hugging Face Transformers, an open-source toolkit that provides straightforward implementations of cutting-edge machine learning models.
SpeechT5 offers three different kinds of speech models in one architecture. Using a standard encoder-decoder structure, SpeechT5’s unified model framework enables learning combined contextual representations for voice and text data. Its different speech models are :
- Text-to-speech: to create audio from scratch.
- Speech-to-text: to recognize speech automatically.
- Speech-to-speech: for performing speech augmentation or switching between voices.
SpeechT5’s fundamental principle is to pre-train one model using a combination of text-to-speech, speech-to-text, text-to-text, and speech-to-speech data. In this manner, the model simultaneously learns from speech and text. This pre-training method produces a model with a single space of hidden representations shared by text and audio.
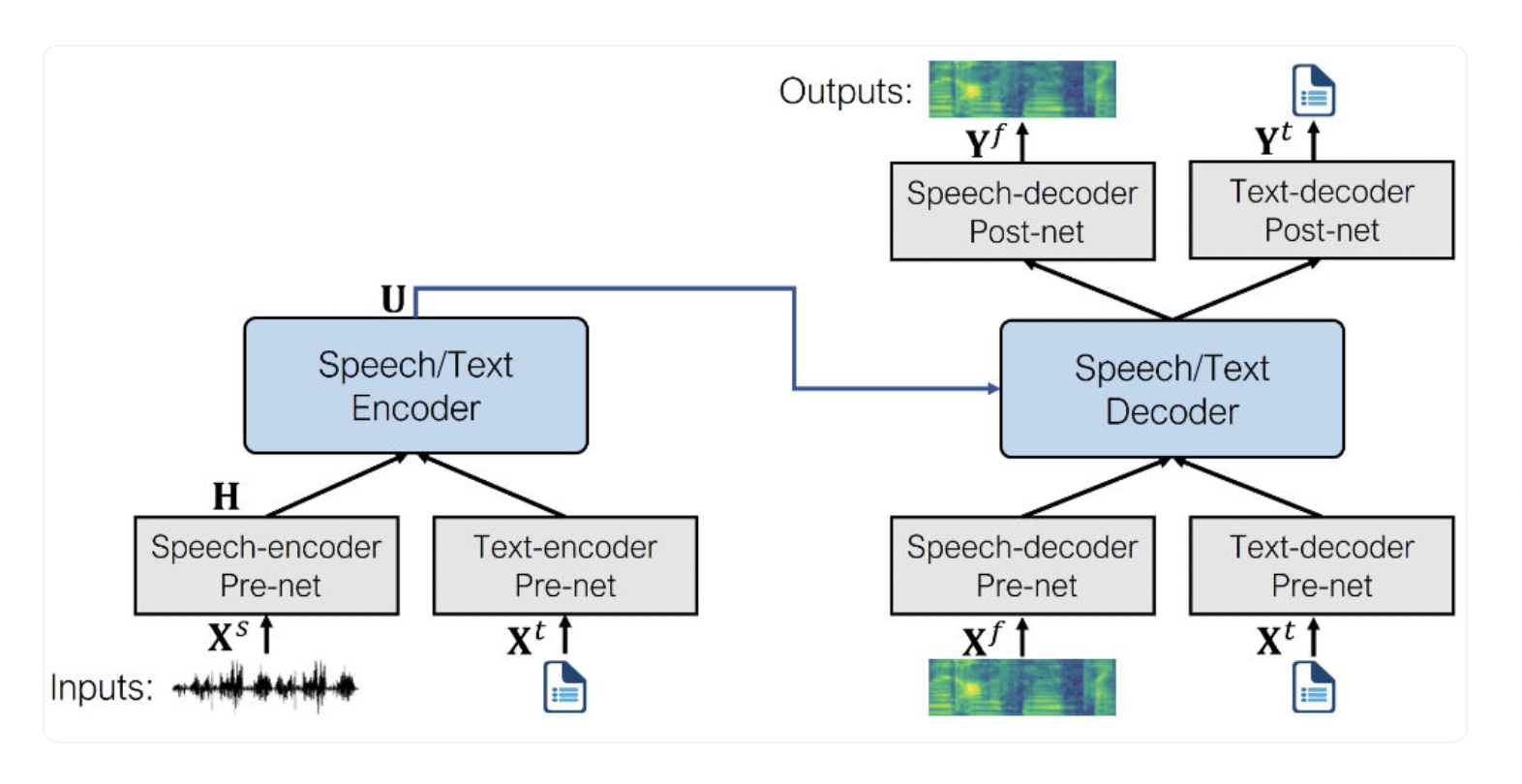
SpeechT5 is based on a standard Transformer encoder-decoder model. The encoder-decoder network simulates a sequential transformation using hidden representations, much like any other Transformer. All SpeechT5 tasks share the same Transformer framework.
Adding pre-nets and post-nets allowed the same Transformer to handle text and speech data. The pre-role nets translate the input text or speech into the Transformer’s hidden representations. The post-net takes the Transformer’s outputs and reformats them as text or speech. To train the model for a diverse set of languages, the team feeds the model with text/speech formats as input and thus generates corresponding output in text/speech format.
Text-to-speech: The model employs the following pre-nets and post-nets for the TTS task:
- Pre-net text encoder. A layer that translates text tokens to the concealed representations the encoder anticipates. Comparable to what occurs in an NLP model like BERT.
- Pre-net speech decoder. It takes a log mel spectrogram as input and compresses it into hidden representations using linear layers.
- Post-net speech decoder. It uses data from Tacotron 2 to forecast a residual to be added to the output spectrogram and to improve the findings.
Speech-to-text: The model employs the following pre-nets and post-nets for the speech-to-text task:
- Speech encoder pre-net.
- Text decoder pre-net.
- Text decoder post-net.
Speech-to-speech: Text-to-speech and SpeechT5’s speech-to-speech modeling are conceptually equivalent. Just replace the speech encoder pre-net with the text encoder pre-net. The remaining model is similar.
In contrast to other models, SpeechT5 is unique as it enables users to carry out numerous activities using the same architecture. All that changes are the pre-nets and post-nets. The model can do each separate task more adeptly after being fine-tuned by pre-training it on these combined tasks. The suggested unified encoder-decoder approach is capable of supporting generation tasks like voice and speech conversion. Large-scale tests reveal that SpeechT5 considerably surpasses all baselines in various spoken language processing tasks. The research team will pre-train the SpeechT5 in the future with a larger model and more unlabeled data. For future work, scientists are also interested in developing the SpeechT5 framework to solve tasks involving spoken language processing across multiple languages.
Check out the Paper and Related Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.