IBM AI Research Introduces Unitxt: An Innovative Library For Customizable Textual Data Preparation And Evaluation Tailored To Generative Language Models
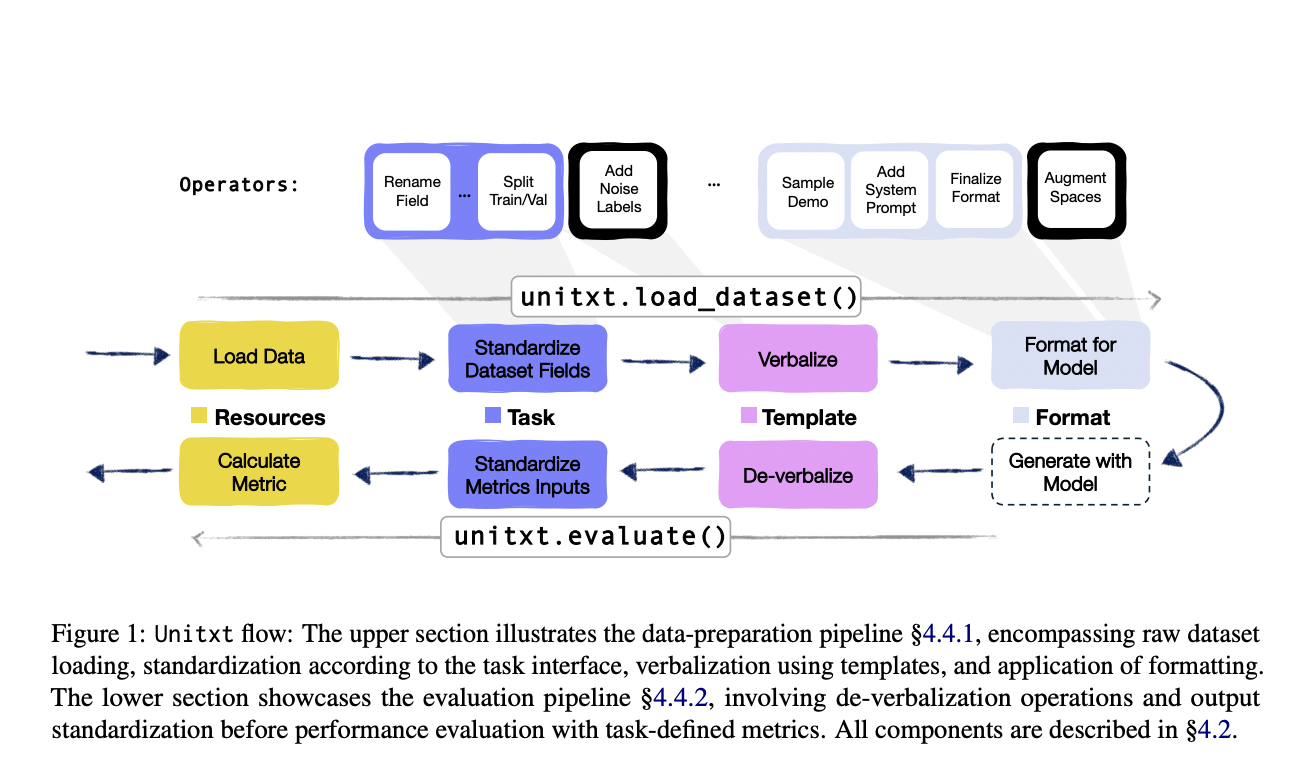
Though it has always played an essential part in natural language processing, textual data processing now sees new uses in the field. This is especially true when it comes to LLMs’ function as generic interfaces; these interfaces take examples and general system instructions, tasks, and other specifications expressed in natural language. As a result, there are now many various kinds of inputs (or prompts) that a model can receive, including task instructions, in-context examples, system prompts, and more. Also, various methods and paradigms can be used to assess and evaluate text generation models because the model outputs represent rich textual data in and of itself. Because of this, analyzing textual data for LLMs is becoming more complicated. It contains several non-trivial design decisions and characteristics, which make it more difficult to keep LLM research flexible and reproducible.
IBM Research introduces Unitxt, a novel collaborative platform for processing unified textual data, presented here. With its new Python module, users can handle textual data in many languages using recipes, essentially configurable pipelines. The operators that load data preprocess it, prepare different portions of a prompt, or evaluate model predictions are all part of a recipe, a sequence of operators for textual data processing. Unitxt comes with a catalog full of pre-defined recipes for different jobs to promote reuse.
The catalog also has a broad set of built-in operators upon which these are based. Collaboration, transparency, and reproducibility are all enhanced by having all of these components in one location, where operators or recipes can be added or shared by anybody. The modularity of Unitxt allows users to mix and match ingredients to build new recipes, just like fitting a recipe. Users can experiment with many recipes, jobs, datasets, and additional formatting options by mixing and matching ingredients, allowing Unitxt to handle over 100,000 recipe configurations. Unitxt understands how annoying it is to switch libraries; to make things easier, it is built to work with existing code, so users can use it without installing pip.
To illustrate, Unitxt can load HuggingFace datasets and provide outputs that follow the same format, which enables it to blend in perfectly with other sections of the software.
Evaluation frameworks that evaluate models over an enormous amount of datasets, workloads, and settings are necessary for the rising capabilities of LLMs. Efforts like these can rely on Unitxt as its foundation since it allows for simple adjustments across several crucial dimensions, such as languages, tasks, prompt structure (e.g., verbalizations, instructions, etc.), augmentation robustness, and more. In addition, the Unitxt Catalog allows separate projects to share their whole evaluation pipelines, which makes data preparation and assessment metrics replication easier.
Modern LLM training frameworks demand a large amount of data to achieve state-of-the-art performance. To impart broad skills, leveraging several datasets across numerous disciplines and languages is required. To enable instruction-following, various prompt formulations and verbalizations are necessary. Nevertheless, substantial technical obstacles exist to overcome when merging textual representations with diverse data sources. Data augmentation, multitask learning, and few-shot tuning become extremely difficult without a shared underlying foundation. Unitxt is a crucial data backbone that comes into play here. With Unitxt, integrating different datasets is a breeze. In addition to allowing for model-specific formatting, data augmentations, dynamic prompt generation, and updates to datasets, the standard format also makes it easy to use other features. Unitxt allows academics to concentrate on developing secure, robust, and performant LLMs by addressing the difficulty of data wrangling. Multiple teams working on different natural language processing (NLP) activities have already used Unitxt as a core utility for LLMs in IBM. These teams work on classification, extraction, summarization, generation, question answering, code, biases, etc.
Unitxt has already been used to train and evaluate big language models at IBM. The team hopes to see the library’s adoption rate rise so that LLM textual data processing can reach new heights as it develops with the help of the open-source community. Because it unifies textual data processing, the team believes that Unitxt can accelerate progress toward more capable, safer, and trustworthy LLMs through its emphasis on cooperation, reproducibility, and adaptability.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.