IBM Researchers Propose a New Adversarial Attack Framework Capable of Generating Adversarial Inputs for AI Systems Regardless of the Modality or Task
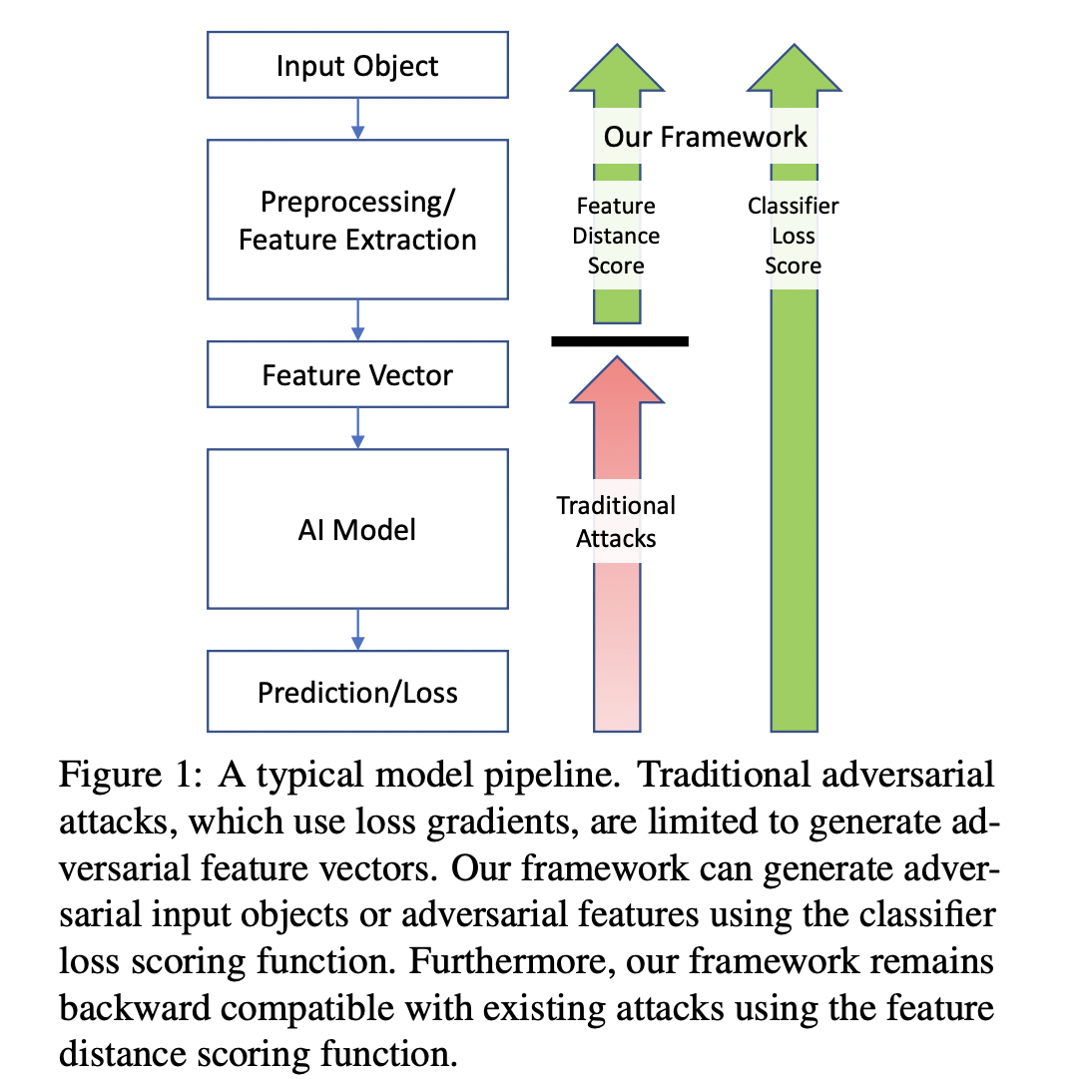
In the ever-evolving landscape of artificial intelligence, a growing concern has emerged. The vulnerability of AI models to adversarial evasion attacks. These cunning exploits can lead to misleading model outputs with subtle alterations in input data, a threat extending beyond computer vision models. The need for robust defenses against such attacks is evident as AI deeply integrates into our daily lives.
Due to their numerical nature, existing efforts to combat adversarial attacks have primarily focused on images, making them convenient targets for manipulation. While substantial progress has been made in this domain, other data types, such as text and tabular data, present unique challenges. These data types must be transformed into numerical feature vectors for model consumption, and their semantic rules must be preserved during adversarial modifications. Most available toolkits need help to handle these complexities, leaving AI models in these domains vulnerable.
URET is a game-changer in the battle against adversarial attacks. URET treats malicious attacks as a graph exploration problem, with each node representing an input state and each edge representing an input transformation. It efficiently identifies sequences of changes that lead to model misclassification. The toolkit offers a simple configuration file on GitHub, allowing users to define exploration methods, transformation types, semantic rules, and objectives tailored to their needs.
In a recent paper from IBM research, the URET team demonstrated its prowess by generating adversarial examples for tabular, text, and file input types, all supported by URET’s transformation definitions. However, URET’s true strength lies in its flexibility. Recognizing the vast diversity of machine learning implementations, the toolkit provides an open door for advanced users to define customized transformations, semantic rules, and exploration objectives.
URET relies on metrics highlighting its effectiveness in generating adversarial examples across various data types to measure its capabilities. These metrics demonstrate URET’s ability to identify and exploit vulnerabilities in AI models while also providing a standardized means of evaluating model robustness against evasion attacks.
In conclusion, the advent of AI has ushered in a new era of innovation, but it has also brought forth new challenges, such as adversarial evasion attacks. The Universal Robustness Evaluation Toolkit (URET) for evasion emerges as a beacon of hope in this evolving landscape. With its graph exploration approach, adaptability to different data types, and a growing community of open-source contributors, URET represents a significant step toward safeguarding AI systems from malicious threats. As machine learning continues to permeate various aspects of our lives, the rigorous evaluation and analysis offered by URET stand as the best defense against adversarial vulnerabilities, ensuring the continued trustworthiness of AI in our increasingly interconnected world.
Check out the Paper, GitHub link, and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.