IBM’s Alignment Studio to Optimize AI Compliance for Contextual Regulations
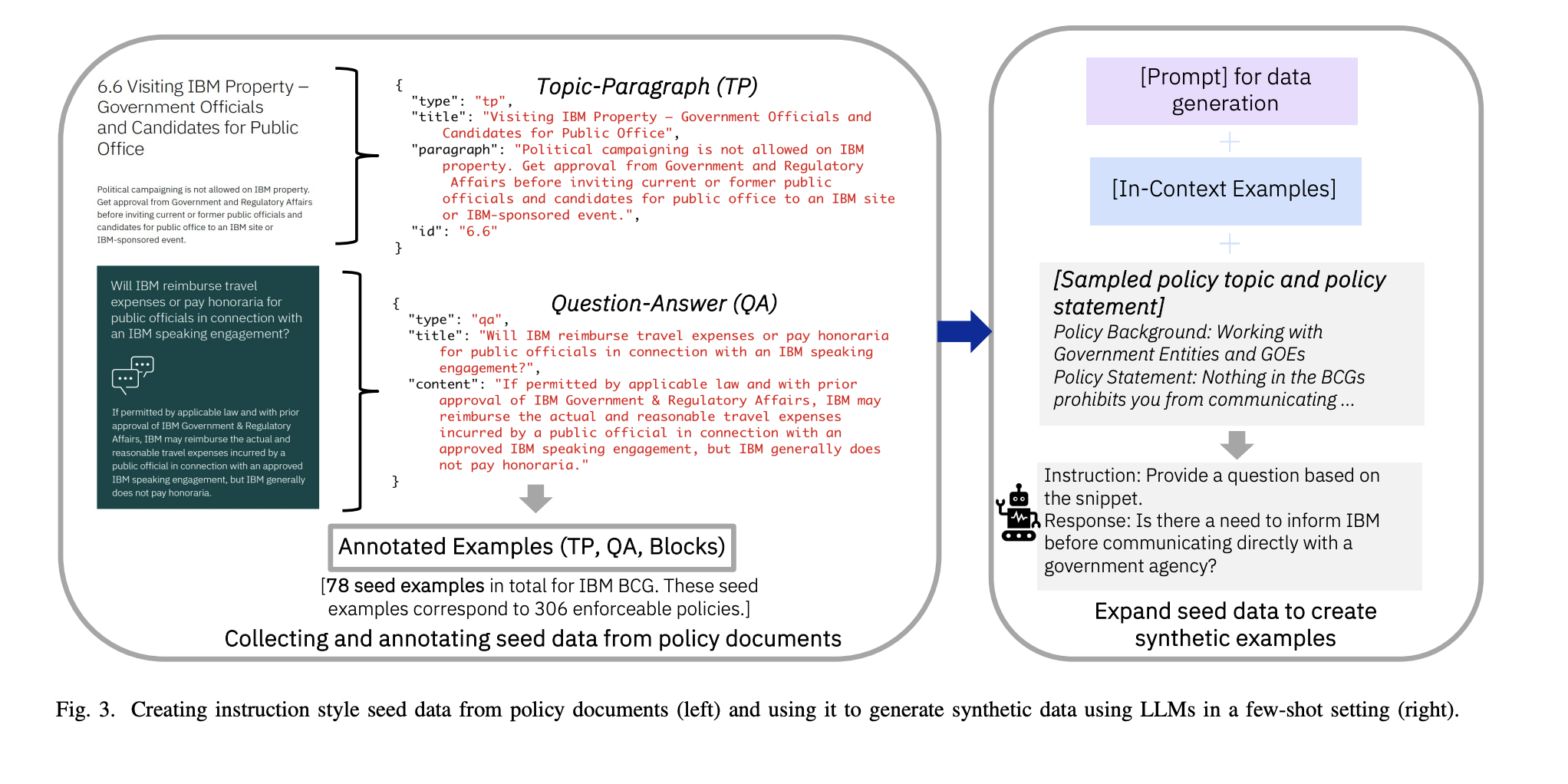
Aligning large language models (LLMs) involves tuning them to desired behaviors, termed ‘civilizing’ or ‘humanizing.’ While model providers aim to mitigate common harms like hate speech and toxicity, comprehensive alignment is challenging due to diverse contextual requirements. Specific industries and applications demand unique behaviors, such as medical applications requiring sensitivity to body part references and customer service bots handling offensive language. Cultural, legal, and organizational factors further shape desired LLM behaviors beyond common concerns.
The researchers from IBM Research present an architecture Alignment Studio that enables application developers to customize model behaviors according to their specific values, social norms, laws, and regulations. Comprising Framers, Instructors, and Auditors, the Alignment Studio orchestrates alignment efforts, addressing potential conflicts in context. The architecture is illustrated by aligning a company’s internal-facing enterprise chatbot with its business conduct guidelines, showcasing how it can tailor model behavior to meet specific organizational requirements.
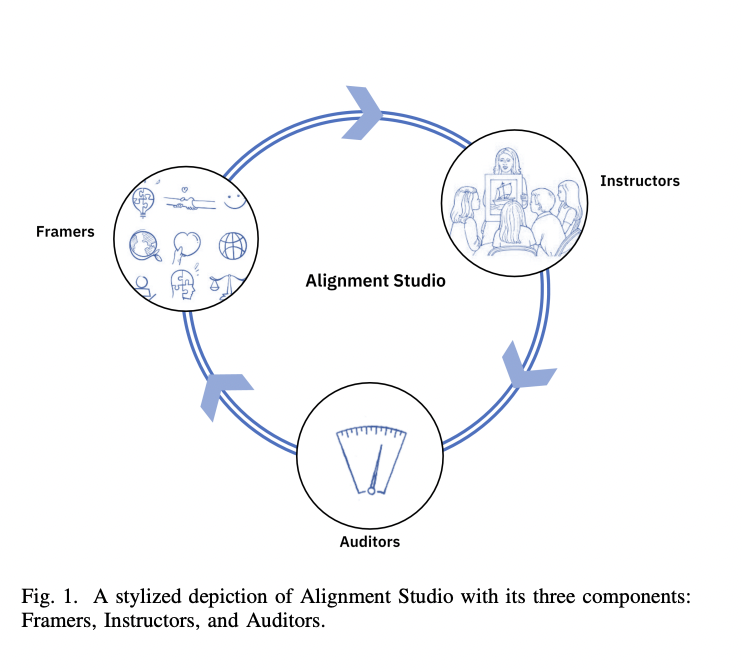
The Alignment Studio comprises Framers, Instructors, and Auditors, aiming to customize LLMs to specific regulations and values. Framers identify essential knowledge for model customization, generating instruction and scenario data. Instructors instill desired behaviors via supervised and reinforcement learning fine-tuning. Auditors ensure model performance through systematic evaluation, including domain-specific testing and red-teaming. This iterative pipeline enables LLMs to align with diverse contextual regulations efficiently.
- Framers: The Framers module customizes LLMs by identifying essential knowledge from domain-specific documents, such as IBM BCGs. It uses manual and synthetic approaches to create instruction and scenario data for model alignment. It also constructs domain-specific ontologies for comprehensive coverage and clarification.
- Instructors: The instructor module enables the instilling of desired values and behaviors in LLMs through supervised fine-tuning (SFT) and reinforcement learning fine-tuning (RLFT). It aligns LLMs with implicit values from regulatory documents like IBM BCGs. Instructors aggregate conflicting values and behaviors, allowing training of reward models. RLFT prioritizes values based on relative importance, resolving conflicts. It incorporates parameter-efficient optimization strategies for low-resource scenarios using (Q)LoRA.
- Auditors: Auditors ensure well-performing models by evaluating data from Framers and methods from Instructors against desired criteria and contextual regulations. Evaluation occurs at various stages: during, after, and post-deployment. Auditors assess the type of data used and the methodology employed, utilizing automated evaluation, human-in-the-loop red-teaming, or both.
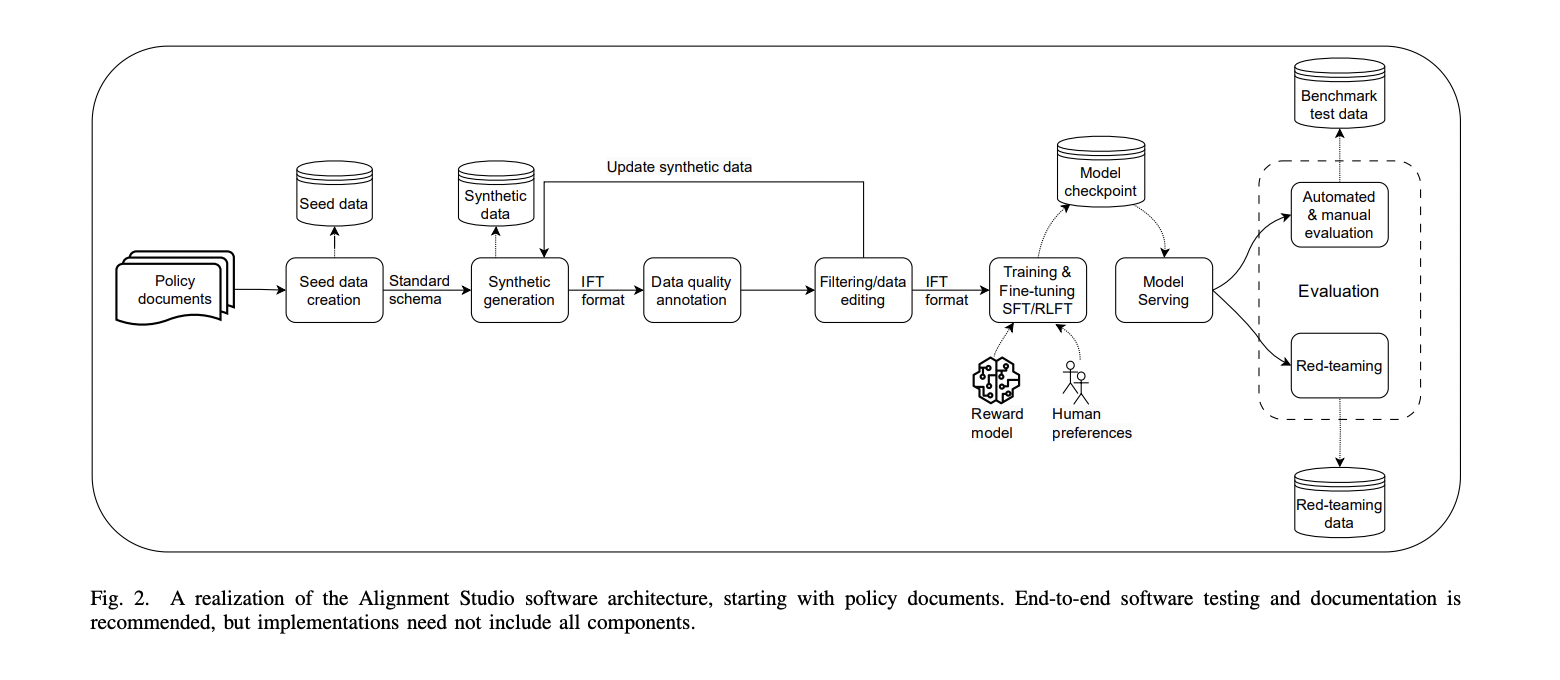
Alignment Studio is demonstrated by aligning an IBM Granite model to IBM BCGs using seed instruction data and SFT. Retrieval-augmented generation (RAG) improves faithfulness. A UI facilitates comparing aligned and unaligned model responses. Aligned models show improved faithfulness and relevance to policy guidelines compared to unaligned ones. Feedback UI enables further refinement of aligned model responses based on user input.
To conclude, the researchers from IBM Research present a principled approach for aligning LLMs with contextual regulations, utilizing a flexible and extensible architecture. Demonstrating alignment with the IBM Business Conduct Guidelines showcases the methodology’s efficacy. Future research aims to broaden the alignment to diverse value specifications and integrate semi-automated methods for identifying misaligned responses, enhancing the approach’s applicability and effectiveness.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link
Comments are closed.