Illuminating the Black Box of AI: How DeepMind’s Advanced AtP* Technique is Pioneering a New Era of Transparency and Precision in Large Language Model Analysis
Google DeepMind researchers have revealed a pioneering approach called AtP* to understand the behaviors of large language models (LLMs). This groundbreaking method stands on the shoulders of its predecessor, Attribution Patching (AtP), by preserving the essence of efficiently attributing actions to specific model components and significantly refining the process to address and correct its inherent limitations.
At the heart of AtP* lies an ingenious solution to a complex problem: identifying the role of individual components within LLMs without succumbing to the prohibitive computational demands typical of traditional methods. Previous techniques, although insightful, stumbled upon the sheer volume of components in state-of-the-art models, rendering them less feasible. AtP*, however, introduces a nuanced, gradient-based approximation that dramatically reduces the computational load, analyzing possible and efficient LLM behaviors.
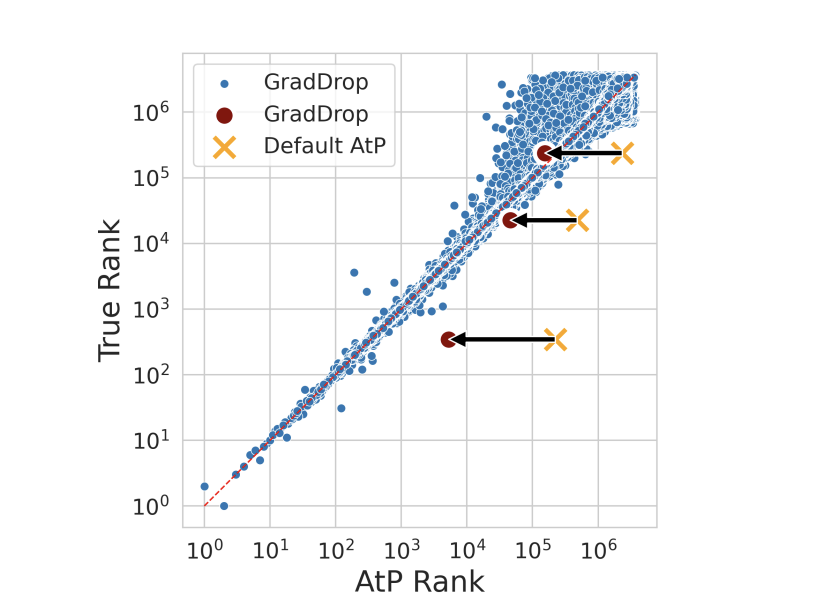
The motivation behind AtP* stemmed from the observation that the original AtP method exhibited notable weaknesses, particularly in generating significant false negatives. This flaw not only clouded the accuracy of the analysis but also cast doubts on the reliability of the findings. In response, the Google DeepMind team embarked on a mission to refine AtP, culminating in the development of AtP*. By recalibrating the attention softmax and incorporating dropout during the backward pass, AtP* successfully addresses the failure modes of its predecessor, enhancing both the precision and reliability of the method.
One cannot overstate the transformative impact of AtP* on AI and machine learning. Through meticulous empirical evaluation, the DeepMind researchers have convincingly demonstrated that AtP* eclipses other existing methods regarding efficiency and accuracy. Specifically, the technique significantly improves the identification of individual component contributions within LLMs. For instance, the research highlighted that AtP*, when compared to traditional brute-force activation patching, can achieve remarkable computational savings without sacrificing the quality of the analysis. This efficiency gain is particularly notable in attention nodes and MLP neurons, where AtP* shines in pinpointing their specific roles within the LLM architecture.
Beyond the technical prowess of AtP*, its real-world implications are vast. By offering a more granular understanding of how LLMs operate, AtP* paves the way for optimizing these models in ways previously unimagined. This means enhanced performance and the potential for more ethically aligned and transparent AI systems. As AI technologies continue to permeate various sectors, the importance of such tools cannot be understated—they are crucial for ensuring that AI operates within the bounds of ethical guidelines and societal expectations.
AtP* represents a significant leap forward in the quest for comprehensible and manageable AI. The method is a testament to the ingenuity and dedication of the researchers at Google DeepMind, offering a new lens through which to view and understand the inner workings of LLMs. As we stand on the brink of a new era in AI transparency and interpretability, AtP* illuminates the path forward and beckons us to rethink what is possible in artificial intelligence. With its introduction, we are one step closer to demystifying the complex behaviors of LLMs, ushering in a future where AI is powerful, pervasive, understandable, and accountable.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.