In A Latest Deep Reinforcement Learning Research, Deepmind AI Team Pursues An Alternative Approach In Which RL Agents Can Utilise Large-Scale Context Sensitive Database Lookups To Support Their Parametric Computations

DeepMind Researchers recently expressed concern about how reinforcement learning (RL) agents might use pertinent information to guide their judgments. They have published a new paper titled Large-Scale Retrieval for Reinforcement Learning, which presents a novel method that significantly increases the amount of information that reinforcement learning (RL) agents can access. This method enables RL agents to attend to millions of information pieces, incorporate new information without retraining, and learn how to use this information in their decision-making end-to-end.
Gradient descent on training losses is the traditional method for helping deep reinforcement learning (RL) agents make better decisions by progressively amortizing the knowledge they learn from their experiences. However, this approach makes it difficult to adapt to unexpected conditions and necessitates the creation of ever-larger models to handle ever-more complicated contexts. There is no end-to-end solution for enabling agents to attend to information outside their working memory to guide their actions, despite adding information sources that can improve agent performance.
In the proposed research, the team develops a semiparametric model-based agent that can forecast future policies and values based on future behavior in a specific state. They also incorporate a retrieval mechanism that allows the model to draw on data from a sizable dataset to help inform their predictions.
Finding a scalable technique to choose and obtain pertinent data and figuring out the most reliable way to use that data in the model were the two fundamental obstacles the team encountered while trying to improve agent predictions using auxiliary information.
The research team uses attention strategies to efficiently scale the information selection and retrieval process. They adopt an inner product in the proper key-query space and choose the top-N reverent results. A language-modeling-inspired embedding function is trained using a surrogate approach to learn key & query embeddings end-to-end to maximize final model predictions. Then, the domain-relevant similarity is represented using the resultant frozen function.
The researchers note that scaling also compels the closest-neighbors lookup to be approximate because it would be impractically time-consuming to acquire the nearest neighbors at the inference time, even though good approximations are still possible. The team supplies nearest-neighbor-related data as different input characteristics that the model learns to comprehend to fully utilize the data in the model. The model can more readily adapt to expansive and complicated situations because of this configuration.
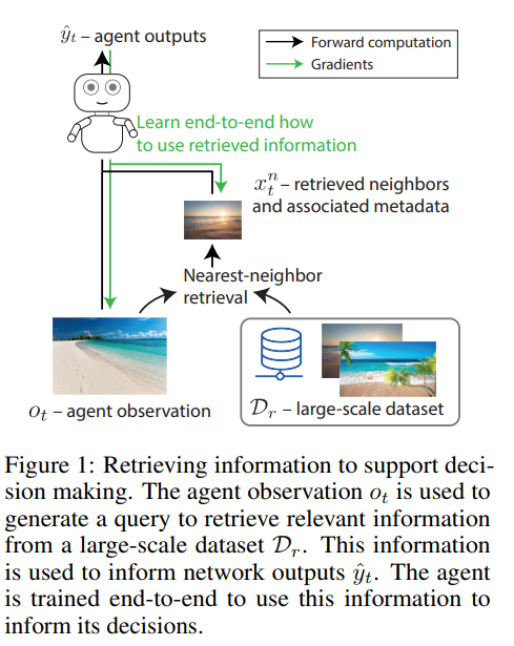
The team’s proposed retrieval method was empirically evaluated in the combinatorial state space of the traditional game of Go on a 9 by 9 board. The findings demonstrate the promise and potential of large-scale retrieval techniques for RL agents by showing that the suggested model can successfully retrieve pertinent data from tens of millions of expert demonstration states and achieve a significant boost in prediction accuracy.
This Article is written as a summary article by Marktechpost Staff based on the paper 'Large-Scale Retrieval for Reinforcement Learning'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, ref blog. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.