In a Latest Machine Learning Research, Amazon Researchers Propose an End-To-End Noise-Tolerant Embedding Learning Framework, ‘PGE’, to Jointly Leverage Both Text Information and Graph Structure in PG to Learn Embeddings for Error Detection
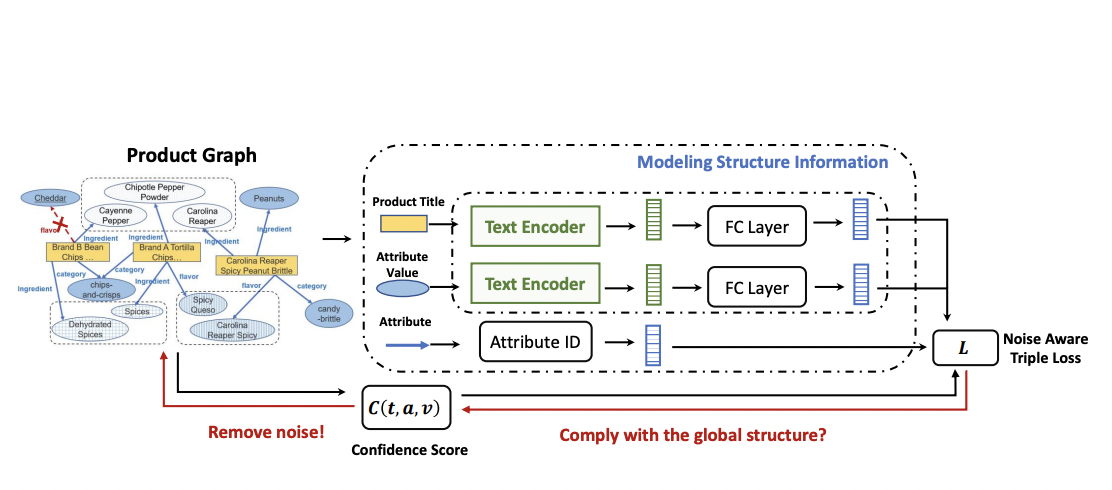

With the rapid rise of the internet, e-commerce websites like Amazon, eBay, and Walmart have become essential avenues for online buying and business transactions. Product knowledge graphs (PGs) have garnered significant interest in recent years as an effective approach to organizing product-related information, enabling several real-world applications such as product search and recommendations.
A knowledge graph (KG) that represents product attribute values is referred to as a PG. It’s made up of data from a product catalog. Each product in a PG has numerous attributes, including the product brand, product category, and additional information about product qualities like flavor and ingredients.
Unlike traditional KGs, where most triples take the form (head entity, relation, tail entity), the majority of triples in a PG take the form (product, attribute, attribute value), with the attribute value being a short text, such as (“Brand A Tortilla Chips Spicy Queso, 6 – 2 oz bags”, flavor, “Spicy Queso”). Attribute triples are a type of triple.
Individual shops contribute the vast majority of product catalog data. These self-reported statistics are always riddled with inconsistencies, erroneous values, and confusing values. When such errors are absorbed by a PG, they cause the downstream applications to perform poorly. Manual validation is not possible in a PG due to a large number of products. A solution for automatic validation is desperately needed.
The state-of-the-art in finding effective representations for multi-relational graph data is currently held by knowledge graph embedding (KGE) approaches. Its goal is to figure out which triples should conform to which network structure. In KGs, KG embedding approaches have demonstrated promising results in error detection (i.e., determining whether or not a triple is accurate).
Because they are linked through several products, the PG structures can imply a strong linkage between the component “pepper” and the flavor “spicy.” Errors such as (“Brand B Bean Chips Spicy Queso, High Protein and Fiber, Gluten-Free, Vegan Snack, 5.5 Ounce (Pack of 6)”, taste, “Cheddar”) can be easily spotted by comparing it to the network structure. Unfortunately, current KG embedding methods can’t be utilized to immediately detect faults in a PG.
Short writings, such as titles and descriptions, are frequently used to describe products in a PG. These texts provide a wealth of information about the features of the products. For example, the product title “Brand A Tortilla Chips Spicy Queso, 6 – 2 oz bags” includes brand, product category, flavor, and size information. The accuracy of these qualities can be easily verified by comparing them to the product title. Furthermore, in PG, the attribute values are free texts. As a result, the traditional method of mapping entity ids to embeddings is no longer valid.
Despite the fact that some recent publications have attempted to use the rich textual information in KGs, the network topology and text information have not been combined into a single representation. For example, distinct loss functions were used to learn text-based and structure-based representations, which were then combined into a single joint representation using a linear combination.
Handling “unseen attribute values” is equally difficult due to the flexibility of textual attribute values. Because they don’t have representations for entities outside of KGs, traditional KG embedding models can’t deal with this inductive situation. Furthermore, constructing a good embedding model for error detection in a PG necessitates clean data. However, noise in a PG might lead to the embedding model learning the incorrect structure information, resulting in a significant reduction in error detection performance.
There is no existing approach that can address all of the aforementioned issues. As a result, Amazon researchers set out to tackle this difficult research question: how to build embeddings for a text-rich, error-prone knowledge graph to aid error detection in a recent study. They introduce robust Product Graph Embedding (PGE), a unique embedding learning paradigm for learning effective embeddings for such knowledge graphs.
The framework is built around two main concepts. First, the embeddings seamlessly blend the signals from attribute triple textual information and knowledge graph structure information. This is accomplished by using a CNN encoder to learn text-based representations for product titles and attribute values and then integrating these text-based representations into the triplet structure to capture the knowledge graph’s underlying patterns. Second, the researchers provide a noise-aware loss function that prevents noisy triples in the PG from causing the embeddings to be misguided during training.
The model predicts the correctness of a triple based on its consistency with the rest of the triples in the KG for each positive case in the training data and down weights an instance when the confidence in its correctness is low. PGE is resilient to noise and can model both textual evidence and graph structure.
The proposed model is scalable and generic. First, as the researchers demonstrate in their tests, it applies not only to the product domain but also to other domains such as Freebase KG. Second, by carefully selecting deep learning models, the model can be trained on KGs with millions of nodes in just a few hours and is resistant to noise and unseen values found in real data.
To encapsulate the network structure of a PG, the team uses a fully-connected neural network layer to transform a text-based representation into its final representation. Researchers employ randomly initialized learnable vectors to represent relations instead of CNN encoders since the number of attributes in a PG is limited and well-defined compared to titles and attribute values. The team defines the goal function by maximizing the joint probability of the observed triples given the embeddings of both entities and relations to capture the network structure of PG.
To lessen the impact of noisy triples on the representation learning process, researchers suggest a unique noise-aware approach. To maintain global consistency with all triples in PG, knowledge representations are learned. Correct triples are intrinsically consistent, allowing them to jointly reflect PG’s global network structure; noisy triples, on the other hand, frequently conflict with these global network structures. As a result, performance is compromised unnecessarily by imposing consistency between right triples and sounds.
PGE is tested on two datasets: a real-world e-commerce dataset gathered from publicly accessible Amazon webpages and the commonly used benchmark dataset FB15K-237. Each product in the Amazon dataset has numerous properties with short text values, such as product title, brand, and flavor. There are 750,000 goods in the Amazon dataset, each having 27 structured attributes and 5 million triples. To prevent bias, the researchers took samples from 325 product categories in a variety of disciplines, including food, beauty, and pharmaceuticals.
The FB15K dataset is the most often used knowledge graph benchmark dataset. It includes textual mentions of Freebase entity pairs as well as knowledge graph relation triples. The FB15K-237 dataset is a variation of the FB15K dataset that removes inverse relations to avoid information leaking in the test dataset.
PGE consistently outperforms KG embedding models as well as CKRL in all cases with a significant performance gain (improving by 24 percent to 30 percent on PR AUC), which ascribes to the use of textual information associated with entities; (2) PGE also outperforms NLP-based approaches because they cannot leverage graph structure information in KGs; (3) PGE also outperforms NLP-based approaches because they cannot leverage graph structure information in KGs. NLP-based approaches, in particular, perform poorly on the FB15k-237 dataset while doing well on the Amazon dataset.
The major reason is that FB15k-237 contains much richer graph information compared to the Amazon dataset (i.e., there are 27 attributes in Amazon dataset while 234 relations in FB15k-237). Therefore, graph structure plays a more critical role in the error detection tasks in FB15k-237; (3) PGE shows better performance compared to DKRL and SSP. The major reason is that DKRL and SSP learn the structural representations and the textual representations by separate functions.
Conclusion
Researchers propose PGE, a unique end-to-end noise-aware embedding learning framework for error detection in PG, to learn embeddings on top of text-based representations of things. Experiment results on a real-world product graph reveal that PGE improves PR AUC in a transductive environment by 18% on average over state-of-the-art approaches. Despite the fact that this research focuses on the product domain, the studies show that the same strategies perform well in other domains such as textual information and noises. The team’s next step would be to look into more efficient Transformer architecture in order to improve PGE’s text encoder strength and efficiency.
Paper: https://www.amazon.science/publications/pge-robust-product-graph-embedding-learning-for-error-detection
Suggested
Credit: Source link
Comments are closed.