In a New AI Paper, CMU and Google Researchers Redefine Language Model Outputs: How Delaying Responses with Pause Tokens Boosts Performance on QA and Reasoning Tasks
Tokens are generated in rapid succession using causal language models based on transformers. The model takes in the K preceding tokens and then iteratively calculates K intermediate vectors in each hidden layer to produce the (K + 1)th token. The module operates on the previous layer’s output vectors, and each vector in itself is the output of a module. Despite the complexity of the entire procedure, one unusual restriction must be met: the number of operations required to determine the next token is constrained by the number of tokens already viewed.
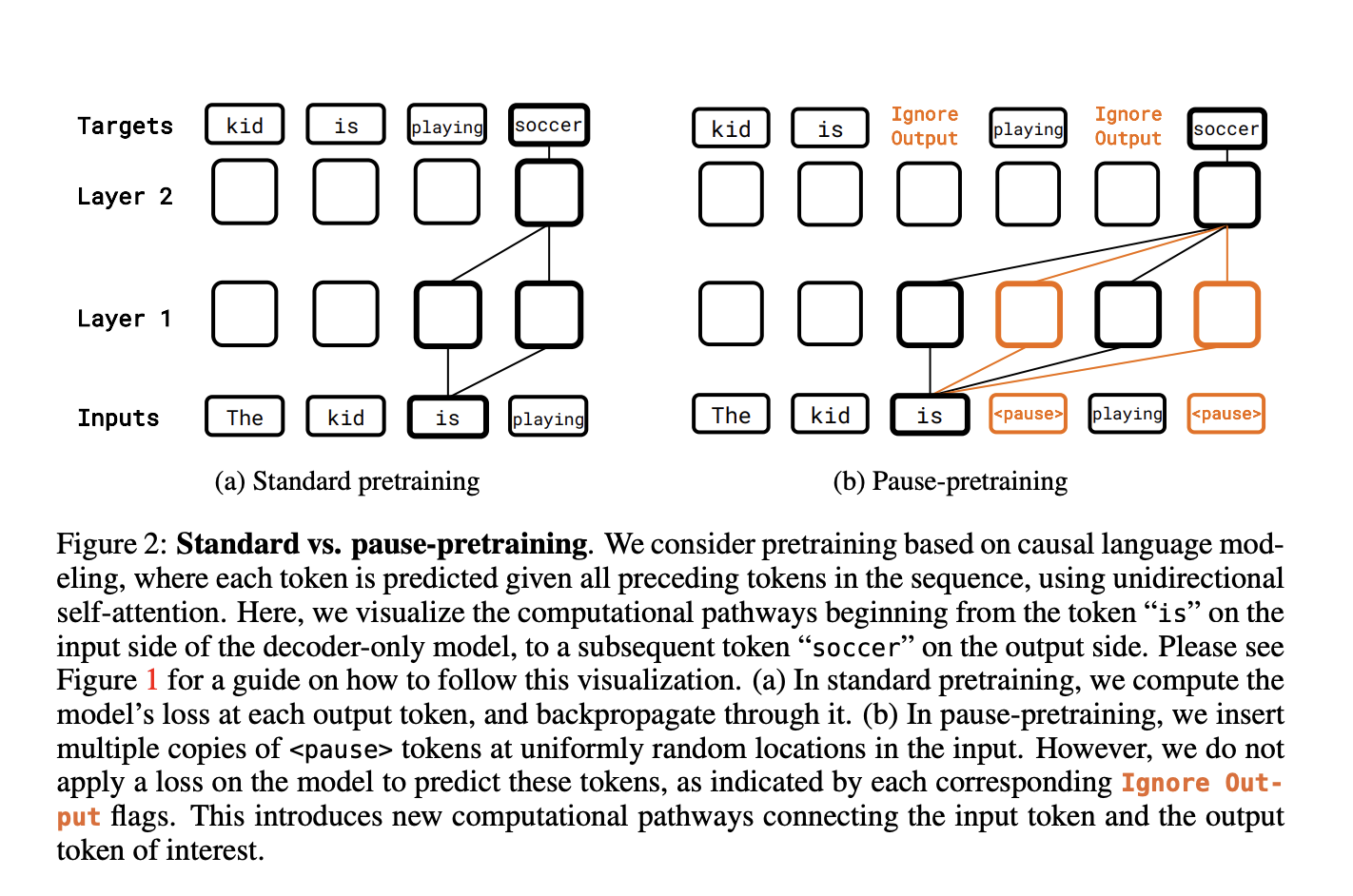
A recent study by Carnegie Mellon University and Google investigated the strategy of adding fake tokens to the input of a decoder-only model to postpone its output. In this work, they decided to pick a (learnable) pause token and append it to the input in a sequence of one or more times. To obtain the model’s answer after the last token has been seen, they simply ignore the matching outputs until then.
Importantly, the researchers think about inserting such delays at inference and during downstream fine-tuning and pretraining. What effect this seemingly little adjustment might have in the real world cannot be known now. The delay creates a potentially “wider” computational channel, which the Transformer may use to its advantage. A simpler result could be that the model ignores the tokens’ ability to cause delays and continues running. After all, neither the tokens themselves nor the small number of new parameters introduced by embedding a single token are adequate to encode any additional information from the training data. These meaningless tokens may obscure useful signals and weaken the model.
The team undertook an empirical assessment to understand the outcome of introducing (appended) delays in all training and inference phases. They examine pause training on a 1B and 130M parameter decoder-only model initially trained on C4 (Raffel et al., 2019) and then fine-tuned on nine downstream tasks covering extractive question response, reasoning, general understanding, and fact recall. Most significantly, this method raises the 1B model’s exact match score by 18% on the SQuAD extractive question-answering task. Similarly, they observed an 8% increase in the general understanding task of CommonSense QA and a 1% accuracy gain on the reasoning task of GSM8k over the standard model’s accuracy of 7.5%.
On the other hand, when tokens are introduced only during the final fine-tuning stage (using the baseline pretrained model), improvements are seen in just a small fraction of cases. The team also conducted a series of key ablations, including:
- Discovering that appending tokens is generally superior to prepending them.
- Discovering that there is an optimal number of tokens for any downstream task.
- Discovering that decreasing the number of inference-time tokens results in a graceful performance degradation.
The team believes that the essential next step would be developing ways to directly make delays helpful on a normal pretrained model. They envision several new theoretical and applied research directions opening up thanks to their work expanding the paradigm of delayed next-token prediction.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.