In Latest Machine Learning Research, A Group at CMU Release a Simple and Efficient Implementation of Recurrent Model-Free Reinforcement Learning (RL) for Future Work to Use as a Baseline for POMDP Algorithms
Most real-world situations involve noise and incomplete information, unlike decision-making algorithms, which often concentrate on simple problems where most information is already available. To solve such issues, complicated algorithms have been developed. However, a straightforward strategy also exists in theory that can be used in primary and complex situations. The canonical issue formulation for Reinforcement Learning (RL) as a Markov decision process often leaves out various uncertainties, can be complex, noisy, and include real-world decision-making tasks. In contrast, the uncertainty in the states, incentives, and dynamics can be captured by Partially Observable MDPs (POMDPs). These uncertainties appear in fields like robotics, medicine, natural language processing, and finance. Researchers from CMU and the University of Montreal have created a methodology that demonstrates the practical application of this straightforward strategy.
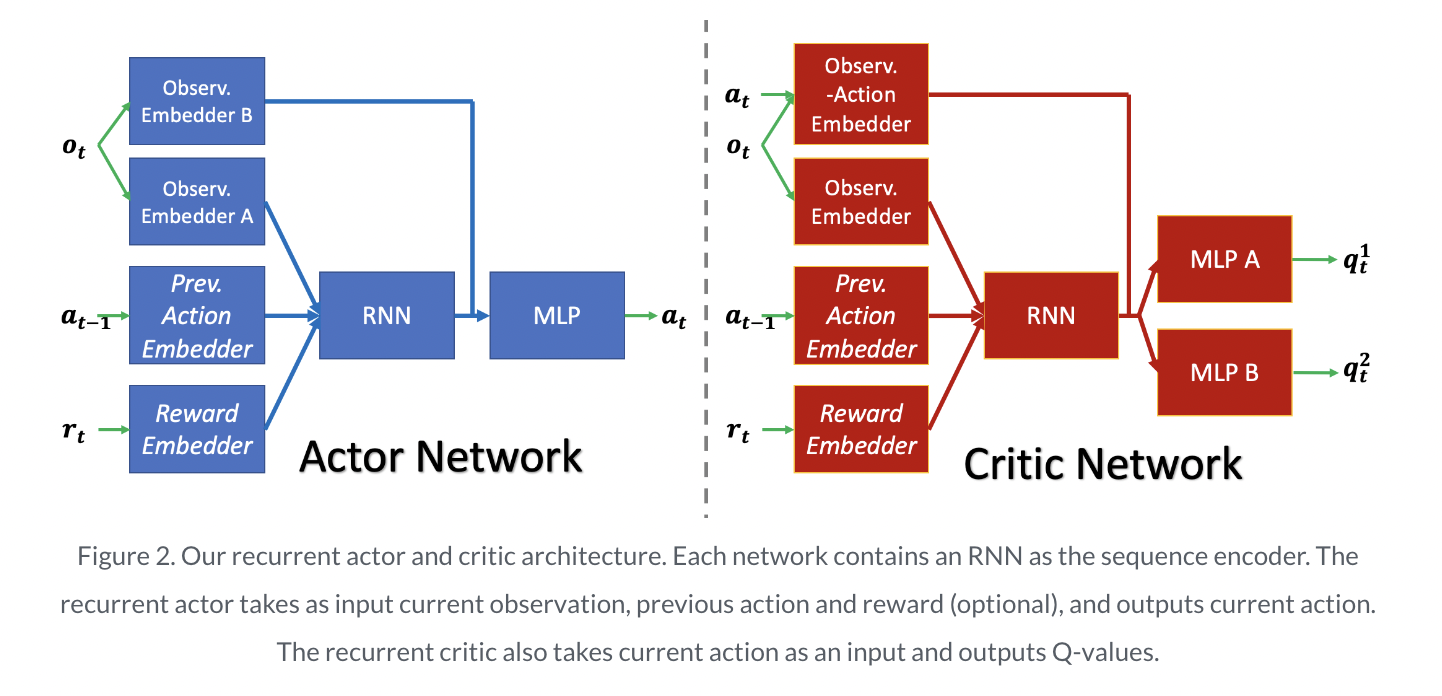
POMDPs can be used to model a variety of RL issues, including meta-RL, resilient RL, generalization in RL, and temporal credit assignment. It is theoretically possible to solve all types of POMDPs by merely supplementing model-free RL with memory-based architectures, such as recurrent neural networks (RNNs). Prior research has also supported that such recurrent model-free RL approaches frequently outperform more specialized algorithms created for particular kinds of POMDPs. The team’s research included reviewing this assertion. Due to the agent’s requirement to simultaneously learn the tasks of inference and control, solving POMDPs is challenging. The goal of inference is to infer the posterior over the current states given the past. Control aims to run RL and planning algorithms on the inferred state space. Deep learning gives us a generic and straightforward baseline: mix an off-the-shelf RL algorithm with a recurrent neural network and GRU. Previous methods often decouple the two jobs using distinct models.
RNNs can analyze histories in POMDPs and learn implicit inference on the control state space thanks to backpropagation. Initially, recurrent model-free RL appears to have several advantages. They are simple to implement and theoretically straightforward. RNNs have also been demonstrated to be universal function approximators, allowing them to describe any memory-based policies. There is a ton of existing literature on various RL algorithms and RNN architectures of recurrent model-free RL because of its expressivity and simplicity. Prior research has demonstrated that it frequently fails in practice with subpar or unstable performance. The poor performance of this fundamental baseline was the driving force for earlier research that suggested more advanced techniques. Others incorporate the presumptions employed in the POMDP subarea as an inductive bias, while others introduce model-based objectives that explicitly teach inference. Although the model-based methods may have some staleness difficulties and the specialized methods require more assumptions than recurrent model-free RL, both produce good results in various applications.
The team found that recurrent model-Free RL only requires a different implementation and is not fatally flawed. Two significant changes are separating the RNNs in actor and critic networks and adjusting the RNN context duration. It was also noted that utilizing an off-policy RL algorithm can increase sampling efficiency. With the implementation of these modifications, the team’s recurrent model-free RL is competitive with earlier techniques, particularly for the tasks for which those earlier techniques were intended. Recurrent model-free RL applies to all POMDP kinds, in contrast to past techniques primarily developed to address specific POMDP scenarios. The team’s technique can frequently outperform existing methods in meta-RL challenges when compared to prototypical methods and off-policy variBAD. The present recurrent model-free technique outperforms all other approaches in the robust RL setting, which is often addressed by algorithms that explicitly maximize the worst returns.
According to the researchers, the findings might be understood as supporting the rationale behind deep learning: to achieve superior outcomes by condensing a method into a single differentiable architecture that is end-to-end optimized for a single loss. This is intriguing since RL systems sometimes consist of interconnected components trained for various goals. If end-to-end techniques have sufficiently expressive structures, they might displace these in the near future. In order to promote reproducibility and aid in improving POMDP algorithms in the future, the team has also made its code publicly available. Additionally, in 2022, they presented their results at the ICML conference.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Recurrent Model-Free RL Can Be a Strong Baseline for Many POMDPs'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, github link, project and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.