In the Latest AI Research Google Explains How It Taps the Full Potential of Datacenter Machine Learning Accelerators with Platform Aware Neural Architecture Search (NAS)

Datacenter accelerators are pieces of hardware that are specifically built to process visual data. It’s a physical device or software program that boosts a computer’s overall performance. Continuous advancements in creating and delivering data center (DC) machine learning (ML) accelerators, such as TPUs and GPUs, have proven crucial for scaling up contemporary ML models and applications. These upgraded accelerators’ ultimate performance (e.g., FLOPs) is orders of magnitude higher than that of standard computing systems.
However, there is a rapidly widening gap between the potential peak performance supplied by state-of-the-art hardware and the actual achievable performance when ML models run on these kinds of hardware.
Designing hardware-specific ML techniques that optimize efficiency (e.g., throughput and latencies) and model integrity is one way to bridge this gap. A platform-aware multi-objective method with a hardware performance objective has been used in recent approaches of neural architecture search (NAS), a new paradigm for automating the construction of ML model architectures.
While this strategy has improved model performance in practice, the model is unaware of the intricacies of the underpinning hardware architecture. As a result, there is unrealized potential for developing full-featured hardware-friendly ML model structures for powerful DC ML accelerators, complete with hardware-specific optimizations.
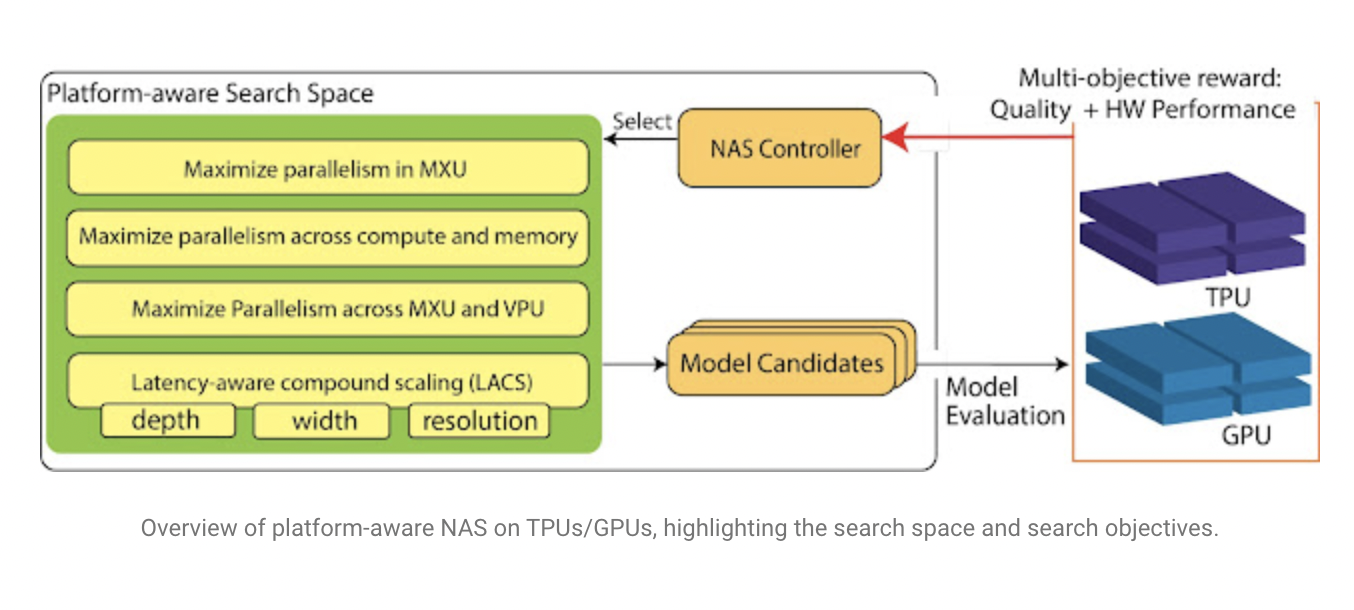
Researchers from Google AI have advanced the state-of-the-art hardware-aware NAS by tailoring model architectures to the hardware on which they will be executed. The proposed method identifies optimized model families for which extra hardware performance gains are not possible without sacrificing model quality. Pareto Optimization is the name given to this concept. To do so, the team incorporated a comprehensive understanding of hardware design into the layout of the NAS search space, which allows for the discovery of single models and model families.
The goal is to offer a quantitative examination of the quality gap across hardware and standard model architectures and show the benefits of adopting genuine hardware performance as the performance tuning goal rather than a performance proxy (FLOPs).
Platform Aware NAS:
ML models must adapt to modern ML accelerators to attain high performance. Platform-aware NAS incorporates hardware accelerator properties into each of the three pillars of NAS:
- Search objectives
- Search space
- Search algorithm
Techniques to improve parallelism for ML model execution:
- It employs unique tensor reshaping techniques to maximize parallelism in the MXUs / TensorCores.
- It constantly selects different activation functions based on matrix operations to ensure that vector and matrix/tensor processing overlap.
- It uses hybrid convolutions and a new fusion method to balance total compute and arithmetic intensity, ensuring concurrent computation and memory access while reducing VPU / CUDA core contention.
- Parallelism is ensured at all levels for the entire model family on the Pareto-front with latency-aware compound scaling (LACS), which utilizes hardware performance rather than FLOPs as the efficiency metric to search for model depth, width, and resolutions.
Efficient Net-X:
It’s a TPU and GPU-optimized computer vision model family. This family builds on the EfficientNet architecture, established by a typical multi-objective NAS without actual hardware awareness.
On TPUv3 and GPUv100, the EfficientNet-X model family achieves an average speedup of 1.5x–2x over EfficientNet, with equivalent accuracy.
Many people believe that FLOPs are a decent ML performance proxy (that is, FLOPs and performance are proportionate), although this is not the case. EfficientNet-X has revealed the non-proportionality among FLOPs and genuine versions, which isn’t only about faster speeds. While FLOPs are an excellent performance proxy for simple hardware like scalar machines, complex matrix/tensor machines can have a margin of error of up to 400 percent.
Performance of Self-driving ML Models:
In a way, the model’s “platform-awareness” is a “gene” that keeps information on maximizing throughput for a hardware series across generations without requiring the models to be redesigned. When upgrading from TPUv2 to TPUv4i, EfficientNet-X preserves its platform-aware features and achieves a 2.6x speedup, utilizing nearly all of the 3x peak performance improvement projected when transitioning between the two generations.
The road ahead:
Platform-aware NAS detected significant performance constraints on TPUv2-v4i architectures thanks to the model’s deep understanding of accelerator hardware architecture. This has enabled design modifications to future TPUs with significant potential performance uplift.
The research team’s following stages include increasing platform-aware NAS’s capabilities to include ML hardware and model design in addition to computer vision.
Paper: https://openaccess.thecvf.com/content/CVPR2021/papers/Li_Searching_for_Fast_Model_Families_on_Datacenter_Accelerators_CVPR_2021_paper.pdf
Reference: https://ai.googleblog.com/2022/02/unlocking-full-potential-of-datacenter.html
Suggested

Credit: Source link
Comments are closed.