In The Latest Research, Apple ML Researchers Explain How They Developed Apple Neural Scene Analyzer (ANSA), A Unified Backbone To Build And Maintain Scene Analysis Workflows In Production
This Article is written as a summay by Marktechpost Staff based on the research article 'A Multi-Task Neural Architecture for On-Device Scene Analysis'. All Credit For This Research Goes To Apple Researchers on This Project. Please Don't Forget To Join Our ML Subreddit
The Apple ecosystem relies heavily on scene analysis, a fundamental component of many features and experiences. The outputs (or “signals”) generated by scene analysis are crucial to how people interact with the photographs on their devices, from visual content search to powerful recollections marking special times in one’s life. Since numerous models can share resources, deploying separate models for each attribute is inefficient. Apple Neural Scene Analyzer (ANSA) provides a single backbone for building and maintaining production scene analysis workflows.
In addition to the Photos app, other notable ANSA users include:.
- Camera, Spotlight search, and Accessibility options
- Notes and Final Cut Pro are two of the most popular Apple programs
- Visualization API-based applications from third-party developers
New operating systems (iOS 16 and Mac OS Ventura) use a single backbone that enables numerous processes totally on-device and executes all tasks in tens of milliseconds. An advanced algorithmic workflow runs entirely on the client to provide the best possible user experience. ANSA must operate under tight power and performance limits while guaranteeing that varied user experiences receive high-quality signals from ANSA.
The model’s deployment on the device was influenced by the following factors:
- The backbone must be shared to run several activities simultaneously, and the compute and network parameters amortized.
- The latency targets must be less than tens of milliseconds for interactive use cases.
There is a wide range of deployment options for neural architectures. However, all of the supported devices have slightly varied hardware and computing capabilities, but all must be used to run ANSA. Therefore, ANSA was developed to run efficiently on all hardware configurations that could be used to run the software. This technology is promising, but it uses convolutional layer-based designs to make it available to devices without a Neural Engine.

The figure above depicts the structure of the human visual system.
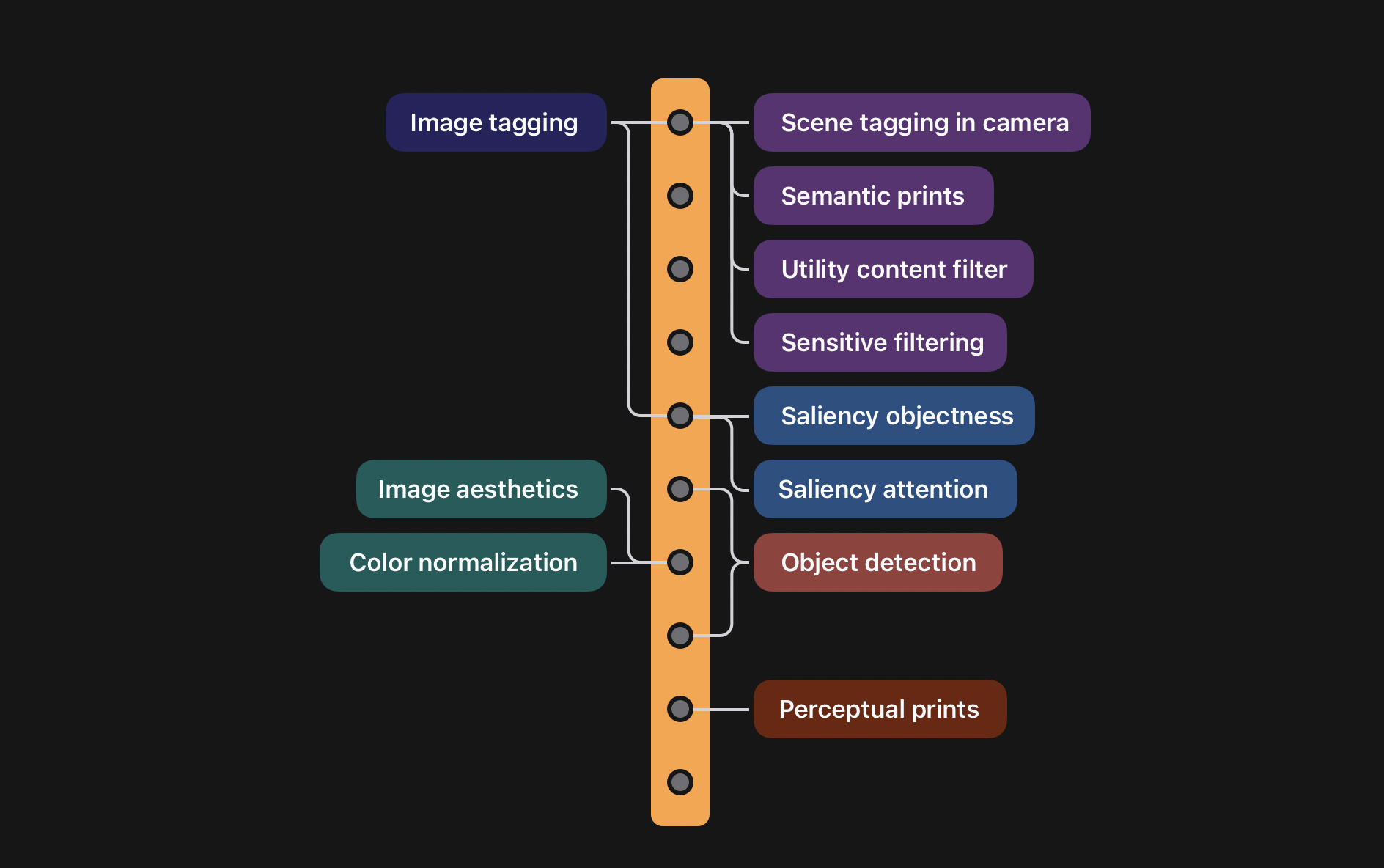
There are several downstream tasks supported by the visual backbone. As a result of the backbone being used by multiple applications, the device’s overall footprint can be kept small. The image section of the image-language backbone, illustrated in orange, was trained with a contrastive objective. The image above does not depict the linguistic area of the backbone. Lower-level tasks in the orange tower rely on features closer to the picture, whereas higher-level tasks rely on parts closer to the ultimate embedding layer. In this diagram, jobs that branch at the same depth share the same hue.
The aim is to train an image backbone with excellent quality that can power a wide range of user experiences. ANSA was built around a frozen backbone with a multilabel classification target before iOS 16 and macOS Ventura. This selection produces a robust and ubiquitous image representation for further downstream activities.
This classifier was initially trained on a small number of millions of photographs, some of which were stock images. Recent research has shown that large-scale, weakly supervised data sets can be used to achieve the best results in many downstream tasks. A contrastive objective is used to train these models to embed photos with their natural-language descriptions using no task-specific annotations. They also acquire meaningful representations that can be utilized for transfer learning on various downstream tasks while conducting zero-shot transfer for image tagging competitively with fully-supervised models. After being trained on many hundred million image-text pairs, the more recent backbone has adopted the integrated image-language paradigm.
For big datasets, parallel training on several GPUs was required, and techniques like gradient checkpointing and mixed-precision training were used to maximize the local batch size on each GPU. As a result, the data set was shared among GPU workers, stored with photos reduced to a resolution closer to what the model needs for training, enabling higher training throughput (about 10 times quicker than the base approach).
It is possible to transfer learning from one job to another with this new image-language pre-trained backbone. The classification was formerly employed as the primary pre-training target for the backbone. Still, a small head is deployed on top of the image-language backbone to help the classification task. A 10.5% increase was noticed in mean average precision when utilizing a MobileNetv3 backbone trained with an image-language objective instead of the initial classification pre-trained backbone. From a superficial linear layer on top of the pre-trained image embedding to a more complicated convolutional network coupled to multiple layers in the backbone, heads can be employed in various ways (like the one used for object detection). The object detection head only consumes 1 MB of storage space on the backbone.
Because ANSA relies entirely on local computing resources, the cloud and other remote resources were not an option. The inference must be fast, memory- and power-efficient, and take up as little space on the disc as possible. Ultimately, a version of MobileNetv3 was chosen that better suited the A11 Bionic, M1, and later CPUs that speed machine learning. The final architecture of ANSA has 16 million parameters, executes all of its heads in under 9.7 milliseconds, uses just 24.6 MB of memory on the Apple Neural Engine (ANE), and occupies only 16.4 MB of disc space. Optimizations such as quantization and trimming were used to attain this result.
Credit: Source link
Comments are closed.