In The Latest Research, Google Researchers Explain Deep Learning With The Multi-Stage Label Differential Privacy
This Article is written as a summay by Marktechpost Staff based on the Research Paper 'Deep Learning with Label Differential Privacy'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper and github. Please Don't Forget To Join Our ML Subreddit
In a recent research article from Google AI, the research team raised concerns regarding the privacy of individuals whose data is used in model training. Differential privacy (DP) has been a prominent privacy concept that has been used in industry and the United States Census Bureau.
The underlying assumption of DP is that modifying a single user’s contribution to an algorithm should have no meaningful impact on the distribution of the algorithm’s output.
A model is trained in the conventional supervised learning environment to predict the label for each input given a training set of sample pairs [input1,label1],…, [inputn, labeln]. Previous work in deep learning introduced the DP-SGD training framework, which was included in TensorFlow and PyTorch. By introducing noise to the stochastic gradient descent (SGD) training process, DP-SGD secures the privacy of each sample pair [input, label]. Despite these efforts, the accuracy of models trained with DP-SGD is still much lower than that of non-private models in most scenarios.
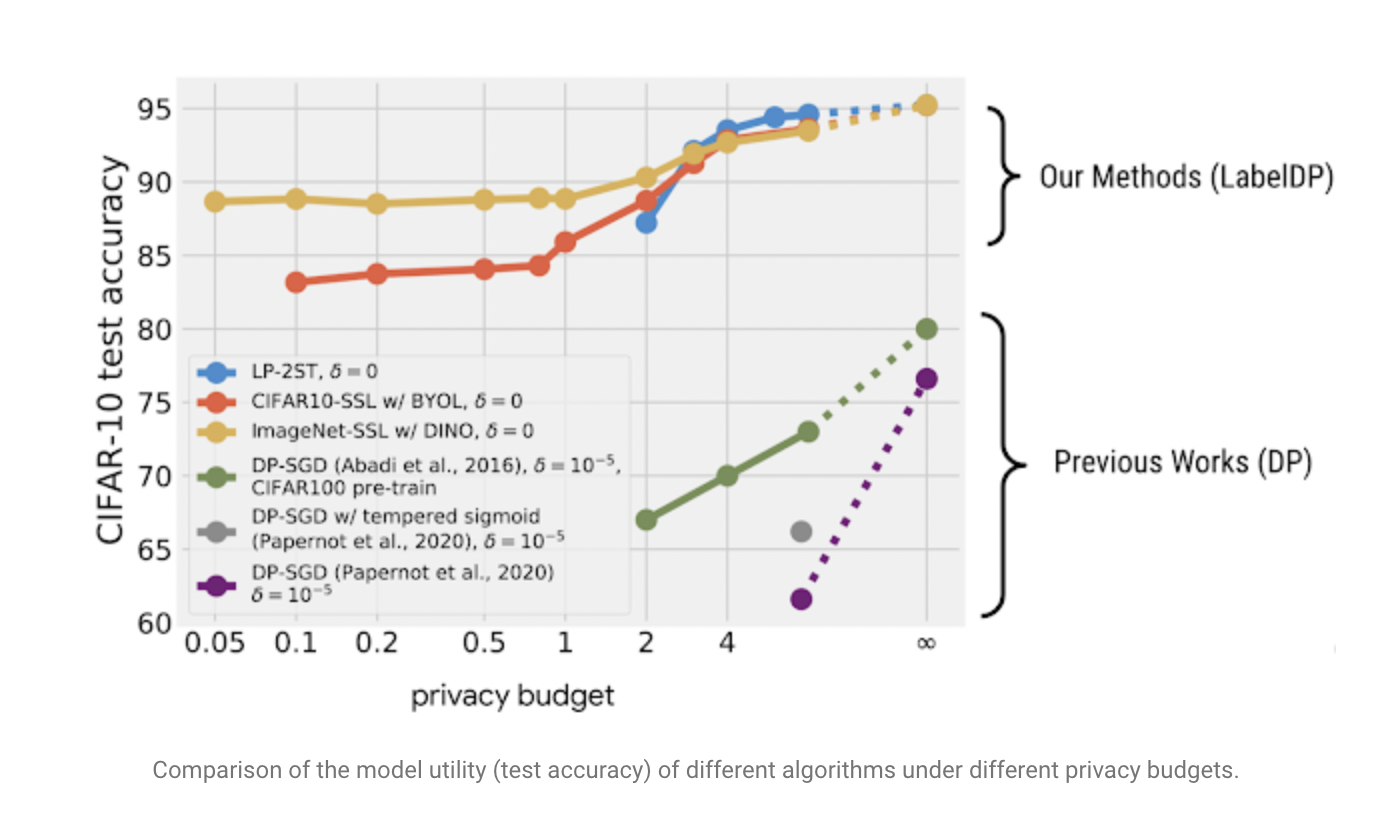
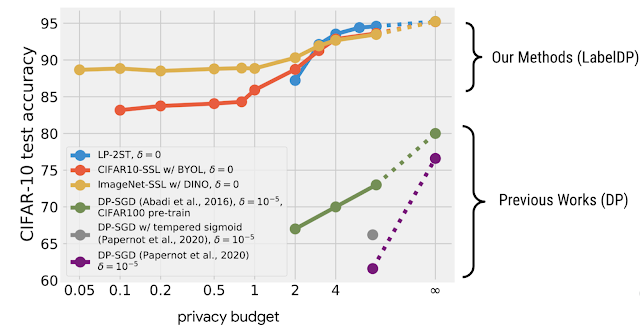
A privacy budget, ε, is included in DP algorithms, which calculates the worst-case privacy loss for each user. Specifically, ε represents how much the likelihood of any given DP algorithm output can change if any example in the training set is replaced with an arbitrarily different one. As a result, a smaller one equates to higher privacy, as the algorithm is less sensitive to changes in a single sample. However, in deep learning applications, it is not unusual to consider up to 8 because smaller tends to impair model utility more. Notably, the best-reported accuracy (without pre-training) for DP models with a = 3 is 69.3 percent for the widely used multi-class image classification dataset, CIFAR-10, which relies on handcrafted visual characteristics. Non-private scenarios (=) with learned features, on the other hand, have been proven to attain >95 percent accuracy using recent neural network designs. Many real-world applications can still not utilize DP due to the performance disparity. Furthermore, despite recent developments, DP-SGD frequently has higher computation and memory costs due to slower convergence and the necessity to compute the per-example gradient’s norm.
Google AI team considers a more simple but particularly essential case called label differential privacy (LabelDP) in “Deep Learning with LabelDP”, presented at NeurIPS 2021, where they assume the inputs (input1,…, inputn) are public. They can construct unique methods that use a prior understanding of the labels to improve the model utility with this simple promise. On the CIFAR-10 dataset, we show that LabelDP achieves a 20% greater accuracy than DP-SGD. Their findings across various tasks show that LabelDP can dramatically reduce the performance difference between private and non-private models, alleviating problems in real-world applications. With LabelDP, we also provide a multi-stage technique for training deep neural networks. Finally, the code for this multi-stage training technique has been released.
The concept of LabelDP has been investigated in the Probably Approximately Correct (PAC) learning context, and it encompasses a variety of real-world settings. Examples include
- Computational advertising, in which the advertiser is aware of impressions and thus considers them non-sensitive, but conversions disclose user interest and are thus considered private;
- User surveys and analytics, where demographic information (e.g., age, gender) is non-sensitive but income is liable; and
- Recommendation systems, where a streaming service provider knows the choices but the user ratings are considered sensitive.
In this instance, the research team makes a few significant observations-
- When only the labels must be protected, significantly simpler data pretreatment algorithms can be used to accomplish LabelDP without requiring any changes to the existing deep learning training pipeline.
- They can compute a prior probability distribution based on the (public) input, which offers an initial belief on the likelihood of the class labels for the given information. They may use prior knowledge to reduce label noise while keeping the same privacy guarantee as classical RR with a new variation of RR called RR-with-prior.
The following below diagram shows how RR-with-prior works. Assume you’ve constructed a model to divide an input image into ten categories. Consider the label “airplane” as an example of training. Classic RR returns a random label sampled according to a predefined distribution to ensure LabelDP (see the top-right panel of the figure below). The higher the probability of sampling an inaccurate title, the smaller the desired privacy budget ε. Assume that we have a prior possibility that the supplied input is “likely a flying object” (lower left panel). RR-with-prior will remove all labels with a small previous and just sample from the remaining brands when using the prior. By removing these improbable labels, the likelihood of receiving the correct title increases dramatically while retaining the same privacy budget (lower right panel).
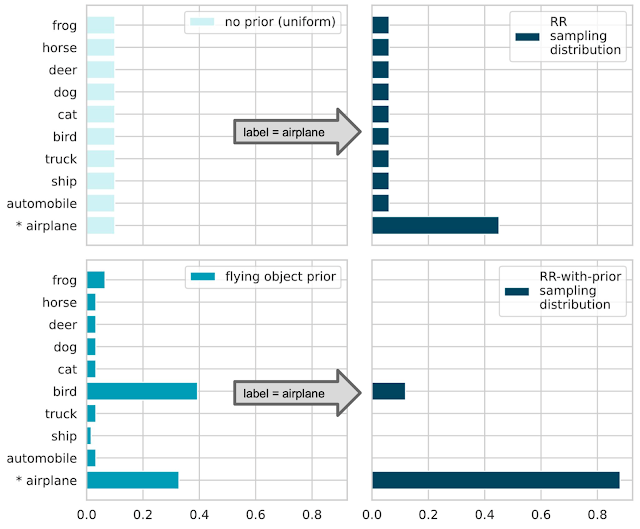
If no previous information is provided (top-left), all classes are randomly picked with equal probability. If the privacy budget is more significant, the likelihood of sampling the proper type (P[airplane] 0.5) is higher (top-right). RR-with-prior: Unlikely classes are “suppressed” from the sampling distribution if a previous distribution is assumed (bottom-left) (bottom-right). As a result, for the same privacy budget, the chance of sampling the actual class (P[airplane] 0.9) is increased.
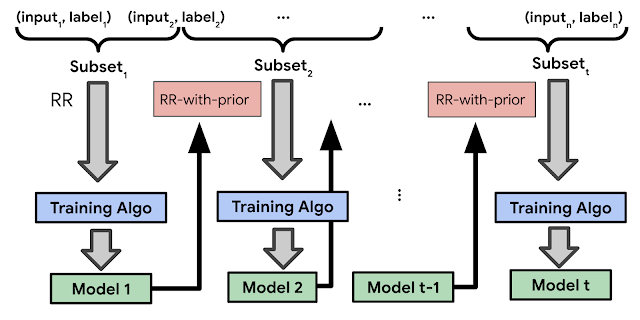
Google AI researchers introduce a multi-stage approach for training deep neural networks with LabelDP based on RR-with-prior observations. First, the training set is divided into various subgroups at random. The first subset is then used to train an initial model using classical RR. Finally, the method separates the data into multiple parts, with one component being utilized for preparing the model at each stage. The labels are generated with RR-with-prior, and the priors are based on the model’s prediction.
The Google Al team tested the empirical performance of the multi-stage training algorithm on a variety of datasets, domains, and architectures. The multi-stage training technique (blue in the figure below) guarantees LabelDP delivers 20% greater accuracy than DP-SGD on the CIFAR-10 multi-class classification challenge for the same privacy expenditure.
Conclusion
Based on practical and theoretical results, the researchers showed that LabelDP is a good relaxation of the full DP guarantee. LabelDP could close the performance gap between a private model and a non-private baseline in applications where the inputs’ privacy isn’t a concern. Google AI researchers intend to improve LabelDP algorithms for tasks other than multi-class classification. They anticipate that the availability of the multi-stage training algorithm code will be a beneficial resource for researchers working on DP.
Credit: Source link
Comments are closed.