Instant Cameras, Evolved: This Text-to-Image AI Model Can Be Personalized Quickly with Your Images
Text-to-image generation is a term we are all familiar with at this point. The era after the stable diffusion release has brought another meaning to image generation, and the advancements afterward made it so that it is really getting difficult to differentiate AI-generated images nowadays. With MidJourney constantly getting better and Stability AI releasing updated models, the effectiveness of text-to-image models has reached an extremely high level.
We have also seen attempts to make these models more personalized. People have worked on developing models that can be used to edit an image with the help of AI, like replacing an object, changing the background, etc., all with a given text prompt. This advanced capability of text-to-image models has also given birth to a cool startup where you can generate your own personalized AI avatars, and it became a hit very suddenly.
Personalized text-to-image generation has been a fascinating area of research, aiming to generate new scenes or styles of a given concept while maintaining the same identity. This challenging task involves learning from a set of images and then generating new images with different poses, backgrounds, object locations, dressing, lighting, and styles. While existing approaches have made significant progress, they often rely on test-time fine-tuning, which can be time-consuming and limit scalability.
Proposed approaches for personalized image synthesis have typically relied on pre-trained text-to-image models. These models are capable of generating images but require fine-tuning to learn each new concept, which necessitates storing model weights per concept.
What if we could have an alternative to this? What if we could have a personalized text-to-image generation model that does not rely on test-time fine-tuning so that we can scale it better and achieve personalization in a little time? Time to meet InstantBooth.
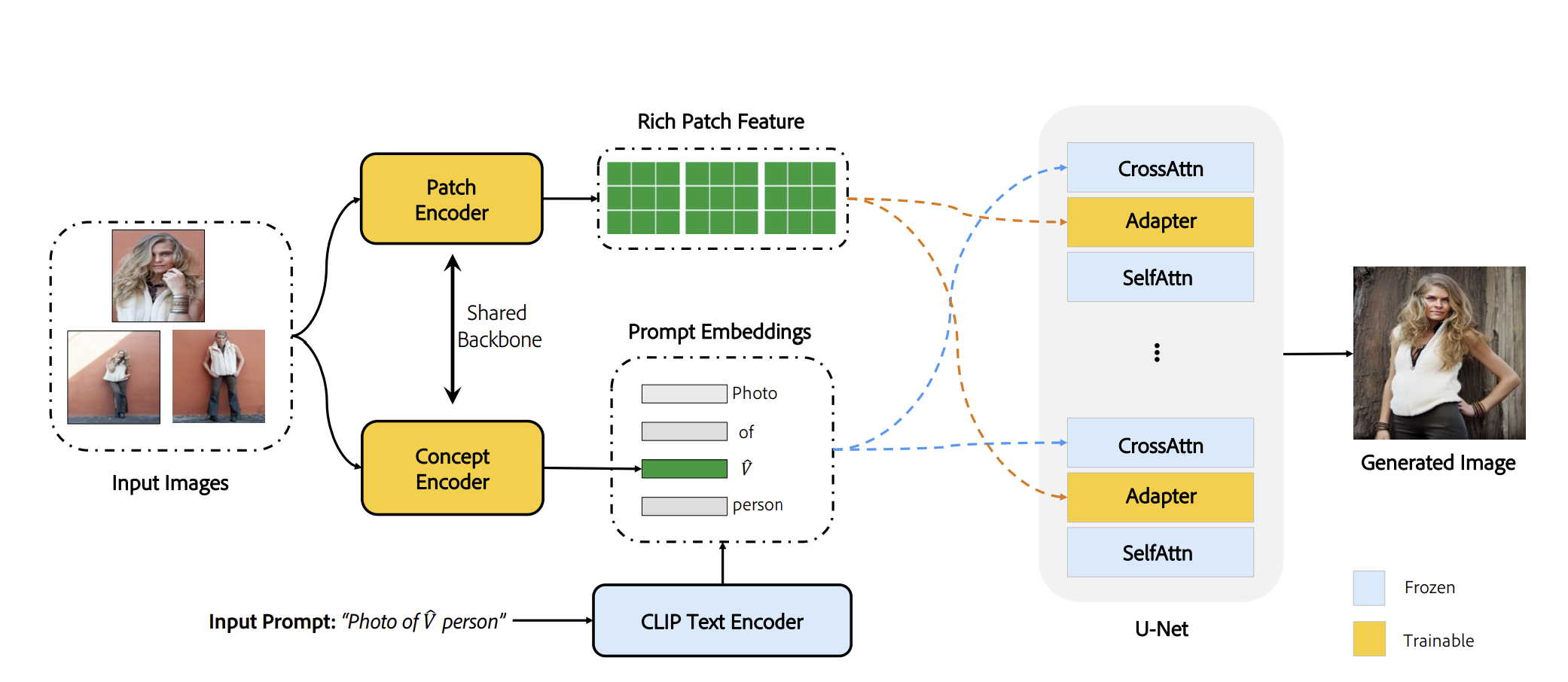
To address these limitations, InstantBooth proposes a novel architecture that learns the general concept from input images using an image encoder. It then maps these images to a compact textual embedding, ensuring generalizability to unseen concepts.

While compact embedding captures the general idea, it does not include the fine-grained identity details necessary to generate accurate images. To tackle this problem, InstantBooth introduces trainable adapter layers inspired by recent advances in language and vision model pre-training. These adapter layers extract rich identity information from the input images and inject it into the fixed backbone of the pre-trained model. This ingenious approach successfully preserves the identity details of the input concept while retaining the generation ability and language controllability of the pre-trained model.
Moreover, InstantBooth eliminates the need for paired training data, making it more practical and feasible. Instead, the model is trained on text-image pairs without relying on paired images of the same concept. This training strategy enables the model to generalize well to new concepts. When presented with images of a new concept, the model can generate objects with significant pose and location variations while ensuring satisfactory identity preservation and alignment between language and image.

Overall, InstantBooth has three key contributions to the personalized text-to-image generation problem. First, the test-time finetuning is no longer required. Second, DreamBooth enhances generalizability to unseen concepts by converting input images into textual embeddings. Moreover, by injecting a rich visual feature representation into the pre-trained model, it ensures identity preservation without sacrificing language controllability. Finally, InstantBooth achieves a remarkable speed improvement of x100 while preserving similar visual quality to existing approaches.
Check out the Paper and Project. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.