JPMorgan AI Research Introduces DocGraphLM: An Innovative AI Framework Merging Pre-Trained Language Models and Graph Semantics for Enhanced Document Representation in Information Extraction and QA
There is a growing need to develop methods capable of efficiently processing and interpreting data from various document formats. This challenge is particularly pronounced in handling visually rich documents (VrDs), such as business forms, receipts, and invoices. These documents, often in PDF or image formats, present a complex interplay of text, layout, and visual elements, necessitating innovative approaches for accurate information extraction.
Traditionally, approaches to tackle this issue have leaned on two architectural types: transformer-based models inspired by Large Language Models (LLMs) and Graph Neural Networks (GNNs). These methodologies have been instrumental in encoding text, layout, and image features to improve document interpretation. However, they often need help representing spatially distant semantics essential for understanding complex document layouts. This challenge stems from the difficulty in capturing the relationships between elements like table cells and their headers or text across line breaks.
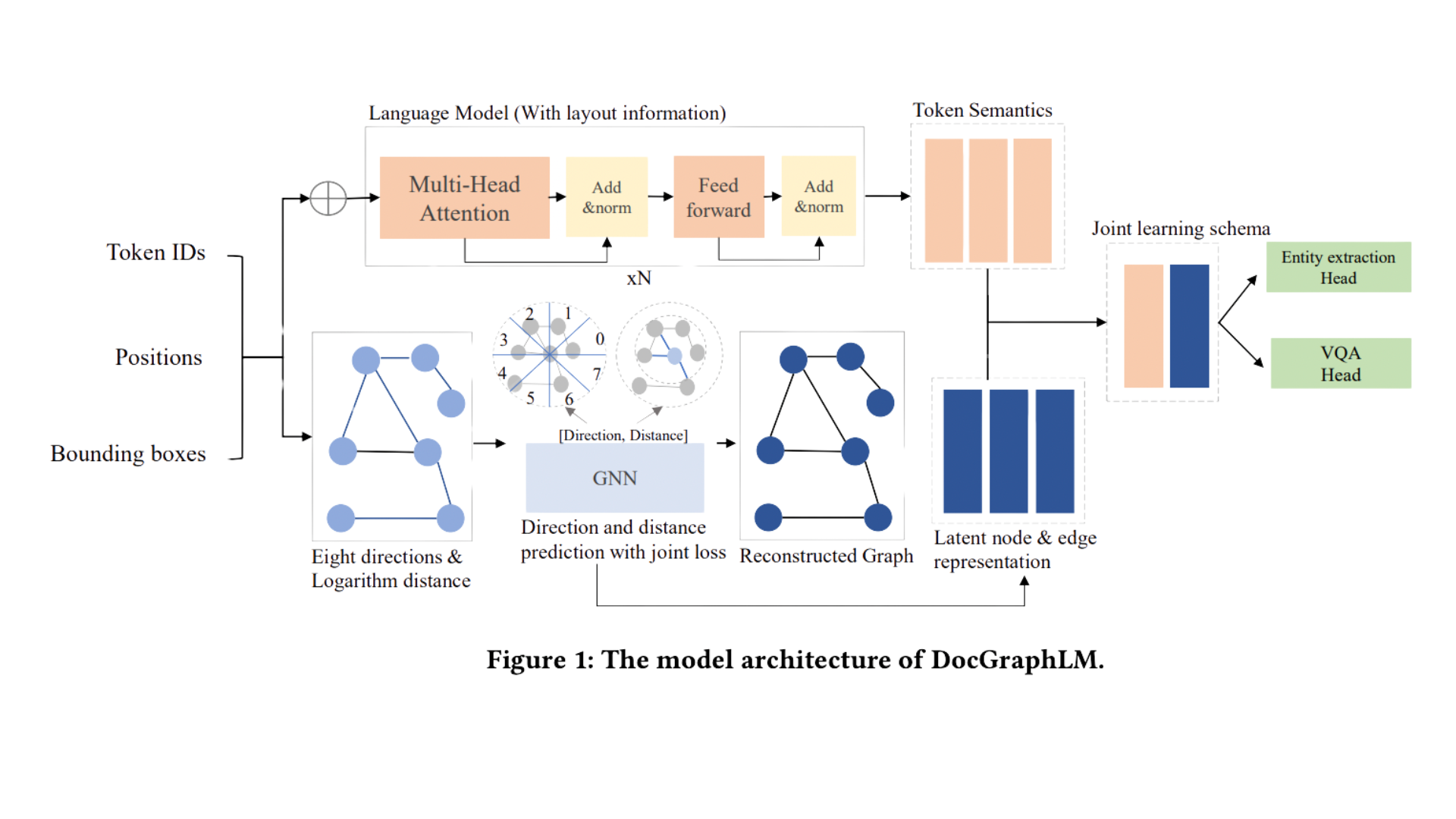
Researchers at JPMorgan AI Research and the Dartmouth College Hanover have innovated a novel framework named ‘DocGraphLM’ to bridge this gap. This framework synergizes graph semantics with pre-trained language models to overcome the limitations of current methods. The essence of DocGraphLM lies in its ability to integrate the strengths of language models with the structural insights provided by GNNs, thus offering a more robust document representation. This integration is crucial for accurately modeling visually rich documents’ intricate relationships and structures.
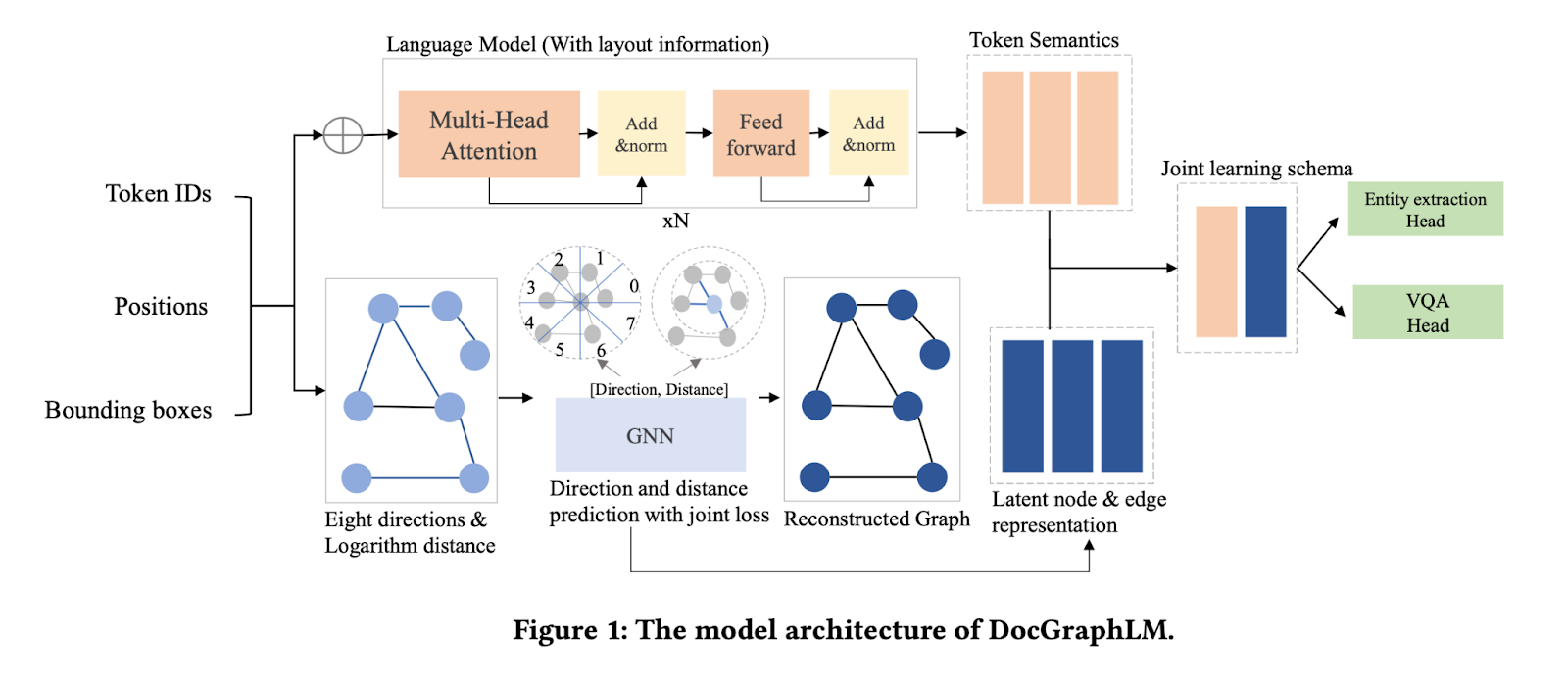
Delving deeper into the methodology, DocGraphLM introduces a joint encoder architecture for document representation coupled with an innovative link prediction approach for reconstructing document graphs. This model stands out for its ability to predict the direction and distance between nodes in a document graph. It employs a novel joint loss function that balances classification and regression loss. This function emphasizes restoring close neighborhood relationships while reducing the focus on distant nodes. The model applies a logarithmic transformation to normalize distances, treating nodes separated by specific order-of-magnitude distances as semantically equidistant. This approach effectively captures the complex layouts of VrDs, addressing the challenges posed by the spatial distribution of elements.
The performance and results of DocGraphLM are noteworthy. The model consistently improved information extraction and question-answering tasks when tested on standard datasets like FUNSD, CORD, and DocVQA. This performance gain was evident over existing models that either relied solely on language model features or graph features. Interestingly, the integration of graph features enhanced the model’s accuracy and expedited the learning process during training. This acceleration in learning suggests that the model can more effectively focus on relevant document features, leading to faster and more accurate information extraction.
DocGraphLM represents a significant leap forward in document understanding. Its innovative approach of combining graph semantics with pre-trained language models addresses the complex challenge of extracting information from visually rich documents. This framework improves accuracy and enhances learning efficiency, marking a substantial advancement in digital information processing. Its ability to understand and interpret complex document layouts opens new horizons for efficient data extraction and analysis, which is essential in today’s digital age.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.