KAIST Researchers Propose DIGAN: An Implicit Neural Representation (INR)-based Generative Adversarial Network (GAN) for Video Generation Using Machine Learning

Deep generative models have produced realistic samples in a variety of domains, including image and audio. Video generation has recently emerged as the next issue for deep generative models, prompting a long line of research to learn video distribution.
Despite their efforts, there is still a big gap between large-scale real-world recordings and simulations. The intricacy of video signals, which are continuously coupled across spatiotemporal directions, contributes to the difficulty of video creation. Specifically, most previous works have modeled the video as a 3D grid of RGB values, i.e., a succession of 2D images, using discrete decoders such as convolutional or autoregressive networks. However, because of the cubic complexity, such discrete modeling limits the scalability of created movies and misses the intrinsic continuous temporal dynamics.
Meanwhile, a new paradigm for encoding continuous signals has emerged: implicit brain representations. INR (Implicit Neural Representations) converts a signal into a neural network that maps input coordinates to signal values, such as converting 2D image coordinates to RGB values. As a result, instead of discrete grid-wise signal values, INR amortizes the signal values of arbitrary coordinates into a compact neural representation, necessitating a large memory proportional to coordinate dimension and resolution. INRs have proven to be particularly effective at modeling complicated signals such as 3D scenes in this regard. INR also offers interesting qualities resulting from its compactness and consistency, such as reduced data memory and upsampling to arbitrary resolution.
INRs are used in several studies for generative modeling, which means that samples are generated using INRs. The generation performance of INR-based image generative adversarial networks, which generate images as INRs, is outstanding. They also praise INRs for their inherent inter-and extrapolation, any cost inference (controlling the quality-cost trade-off), and parallel computation, which requires a non-trivial adjustment to implement under other generative model designs.
Researchers at the Korea Advanced Institute of Science and Technology recently published a study that aims to create an INR-based (or implicit) video production model by reading videos as continuous signals. INRs compactly encode videos without 3D grids and intuitively model continuous Spatio-temporal dynamics, making this alternative viewpoint unexpectedly successful. While applying INRs to videos naively is already very effective, the team discovered that a sophisticated design of individually altering space and time improves video production greatly.
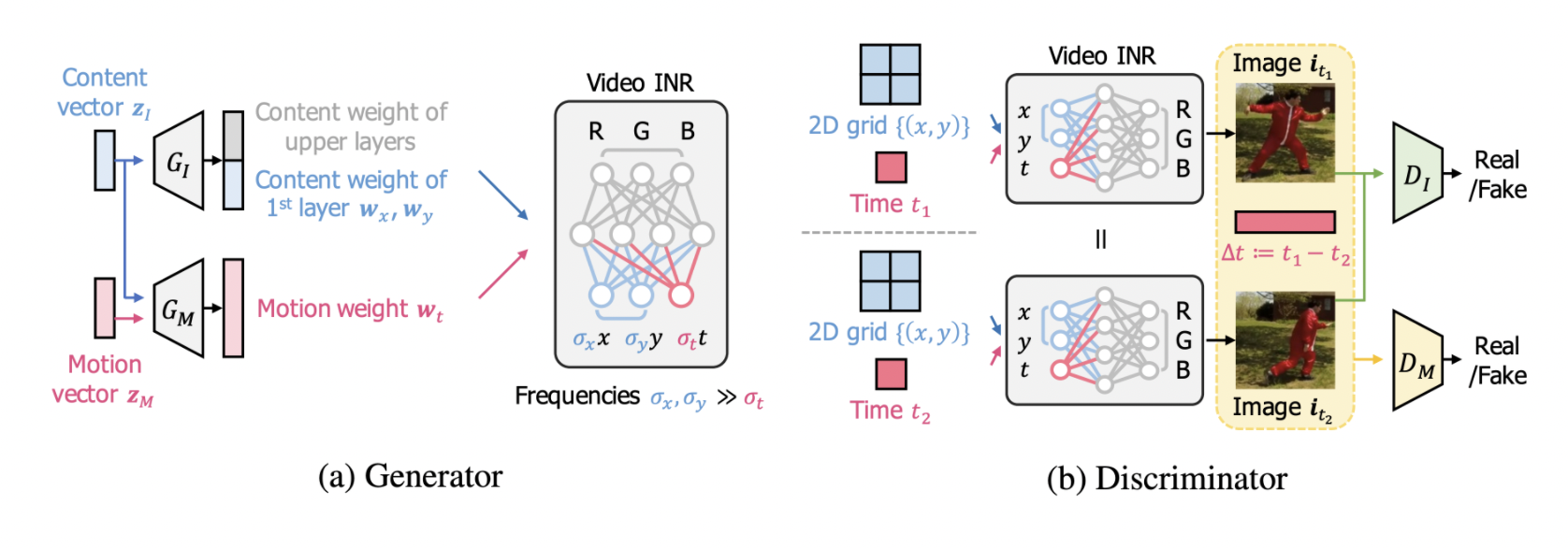
A unique INR-based GAN architecture for video creation, the dynamics-aware implicit generative adversarial network (DIGAN), is introduced. The concept is twofold:
Generator: The team offers a video generator based on INR that decomposes motion and content (image) data and includes temporal dynamics into motion features. To be more explicit, the generator promotes video temporal coherency by regulating motion feature variations with a lower temporal frequency and improving the expressive power of motions with an additional non-linear mapping. Furthermore, by conditioning a random motion vector to the content vector, the generator can make films with a variety of motions that all share the same initial frame.
Discriminator: Instead of a long sequence of images, the team presents a motion discriminator that efficiently detects abnormal motions from a pair of photographs (and their time difference). DIGAN’s motion discriminator is a 2D convolutional network, as opposed to previous research that used computationally intensive 3D convolutional networks to handle the full movie at once. Because INRs of videos can non-autoregressively synthesize strongly correlated frames at unpredictable periods, such an efficient discriminating approach is viable.
The main idea is to use implicit neural representations to directly model the films as continuous signals. The dynamics-aware implicit generative adversarial network (DIGAN) is an INR-based generative adversarial network for video production, according to the researchers. DIGAN expands implicit image GANs for video production by introducing temporal dynamics, inspired by the success of INR-based GANs for image synthesis.
The tests are carried out on datasets from UCF-101, Tai-ChiHD, Sky Time-lapse, and a meal class subset of Kinetics-600. Unless otherwise noted, all models are trained using 16 frame movies with a resolution of 128*128 pixels. To make motion more dynamic, researchers employ the consecutive 16 frames for UCF-101, Sky, and Kinetics-food, but stride 4 (i.e., skip three frames after the chosen frame) for TaiChi.
DIGAN can simulate unimodal and multimodal video distributions, such as Sky and TaiChi, as well as unimodal and multimodal videos like UCF-101 and Kinetics-food. DIGAN, in particular, is capable of producing complex multimodal videos. Furthermore, the results show that DIGAN outperforms previous work on all datasets, for example, improving the FVD of MoCoGAN-HD from 833 to 577 (+30.7 percent) on UCF-101. They point out that DIGAN’s Frechet inception distance, a statistic for image quality, is comparable to MoCoGAN-HD. As a result, DIGAN’s FVD benefits are due to improved dynamics modeling.
Conclusion
DIGAN is an implicit neural representation (INR)-based generative adversarial network (GAN) for video production that incorporates the temporal dynamics of videos, according to the researchers. Extensive testing confirmed DIGAN’s supremacy with a variety of fascinating features. The researchers believe their discovery will pave the way for future developments in video creation and INR research.
Paper: https://openreview.net/pdf?id=Czsdv-S4-w9
Github: https://github.com/sihyun-yu/digan
Project: https://sihyun-yu.github.io/digan/
Suggested
Credit: Source link
Comments are closed.