LAION AI Introduces Video2Dataset: An Open-Source Tool Designed To Curate Video And Audio Datasets Efficiently And At Scale
Big foundational models like CLIP, Stable Diffusion, and Flamingo have radically improved multimodal deep learning over the past few years. Joint text-image modeling has gone from being a niche application to one of the (if not the) most relevant issues in today’s artificial intelligence landscape due to the outstanding capabilities of such models to generate spectacular, high-resolution imagery or perform hard downstream problems. Surprisingly, despite tackling vastly different tasks and having vastly different designs, all these models have three fundamental properties in common that contribute to their strong performance: a simple and stable objective function during (pre-)training, a well-investigated scalable model architecture, and – perhaps most importantly – a large, diverse dataset.
Multimodal deep learning, as of 2023, is still primarily concerned with text-image modeling, with only limited attention paid to additional modalities like video (and audio). Considering that the techniques used to train the models are typically modality agnostic, one could wonder why there aren’t solid groundwork models for these other modalities. The simple explanation is the scarcity of high-quality, large-scale annotated datasets. This lack of clean data impedes research and development of large multimodal models, especially in the video domain, in contrast to image modeling, where there exist established datasets for scaling like LAION-5B, DataComp, and COYO-700M and scalable tools like img2dataset.
Because it can pave the way for groundbreaking initiatives like high-quality video and audio creation, improved pre-trained models for robotics, movie AD for the blind community, and more, researchers suggest that resolving this data problem is a central aim of (open source) multimodal research.
Researchers present video2dataset, an open-source program for fast and extensive video and audio dataset curating. It has been successfully tested on several large video datasets, and it is adaptable, extensible, and provides a huge number of transformations. You can find these case studies and detailed instructions on replicating our method in the repository.
By downloading individual video datasets, merging them, and reshaping them into more manageable shapes with new features and significantly more samples, researchers have utilized video2dataset to build upon existing video datasets. Please refer to the examples section for a more in-depth description of this chain processing. The outcomes they achieved by training different models on the datasets supplied by video2dataset demonstrate the tool’s efficacy. Our forthcoming study will extensively discuss the new data set and associated findings.
To begin, let’s define video2dataset.
Since webdataset is an acceptable input_format, video2dataset can be used in a chain to reprocess previously downloaded data. You can use the WebVid data you downloaded in the previous example to execute this script, which will calculate the optical flow for each movie and store it in metadata shards (shards that only have the optical flow metadata in them).
Architecture
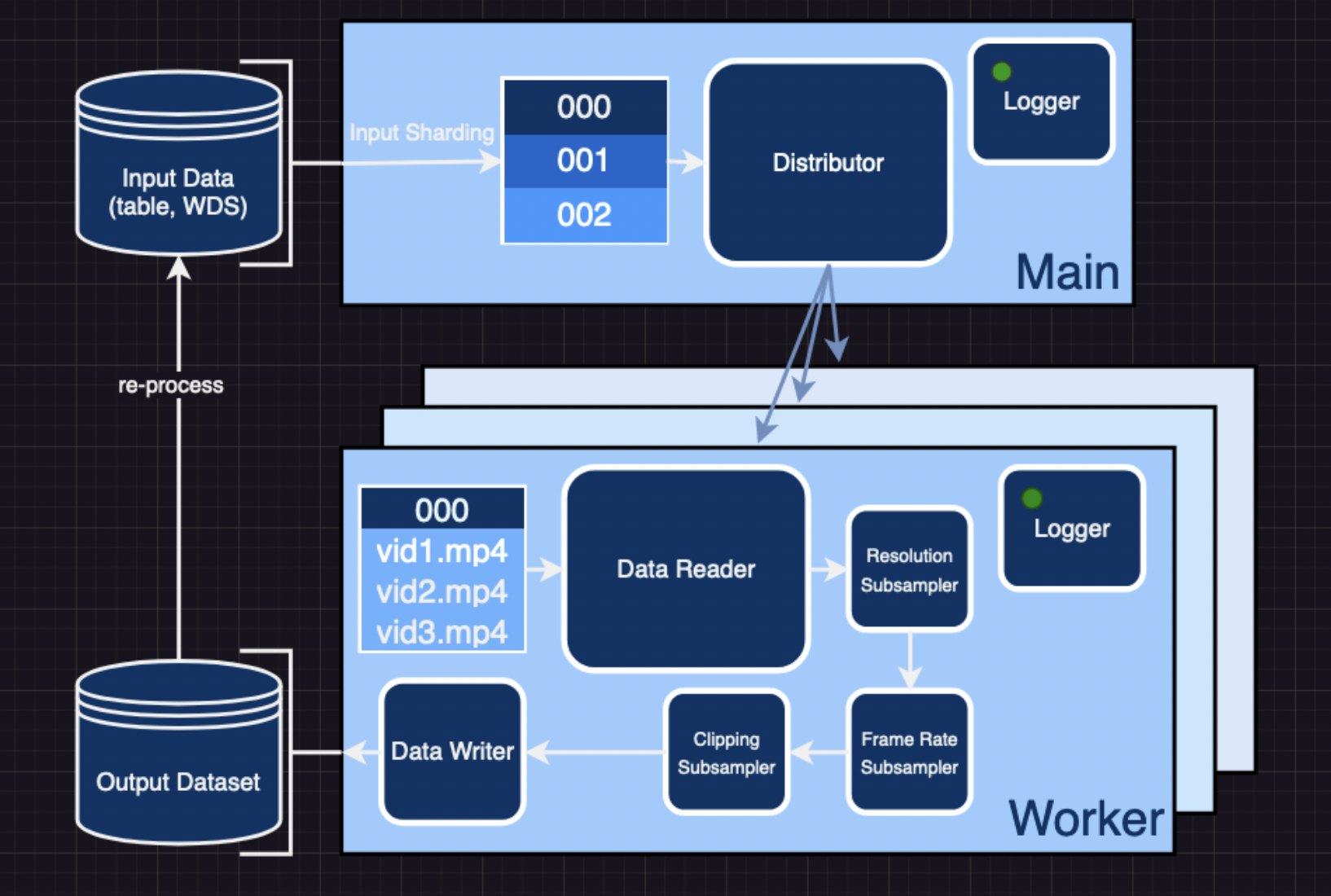
Based on img2dataset, video2dataset takes a list of URLs and associated metadata and converts it into a WebDataset that can be loaded with a single command. In addition, the WebDataset can be reprocessed for additional changes with the same shard contents preserved. How does video2dataset work? I’ll explain.
Exchanging Ideas
The first step is to partition the input data so that it may be distributed evenly among the workers. These input shards are cached temporarily, and the one-to-one mapping between them and their corresponding output shards guarantees fault-free recovery. If a dataset processing run terminates unexpectedly, one can save time by skipping the input shards for which researchers already have the corresponding output shard.
Communication and Study
Workers then take turns reading and processing the samples contained within the shards. Researchers offer three different distribution modes: multiprocessing, pyspark, and slurm. The former is ideal for single-machine applications, while the latter is useful for scaling across several machines. The format of the incoming dataset determines the reading strategy. If the data is a table of URLs, video2dataset will fetch the video from the internet and add it to the dataset. video2dataset works with many different video platforms because it uses yt-dlp to request videos it can’t find. However, if the video samples come from an existing Web dataset, the data loader for that dataset can read the tensor format of the bytes or frames.
Subsampling
After the video has been read and the worker has the video bytes, the bytes are sent through a pipeline of subsamplers according to the job configuration. In this stage, the video may be optionally downsampled in terms of both frame rate and resolution; clipped; scenes may be identified; and so on. On the other hand, there are subsamplers whose sole purpose is to extract and add metadata, such as resolution/compression information, synthetic captions, optical flow, and so on, from the input modalities. Defining a new subsampler or modifying an existing one is all it takes to add a new transformation to video2dataset if it isn’t already there. This is a huge help and can be implemented with a few changes elsewhere in the repository.
Logging
Video2dataset keeps meticulous logs at multiple points in the process. Each shard’s completion results in its associated “ID” _stats.json file. Information such as the total number of samples handled, the percentage of those handled successfully, and the occurrence and nature of any errors are recorded here. Weights & Biases (wand) is an additional tool that can be used with video2dataset. With just one argument, you can turn on this integration and access detailed performance reporting and metrics for successes and failures. Such capabilities are helpful for benchmarking and cost-estimating tasks connected to whole jobs.
Writing
Finally, video2dataset stores the modified information in output shards at user-specified places to use in subsequent training or reprocessing operations. The dataset can be downloaded in several formats, all consisting of shards with N samples each. These formats include folders, tar files, records, and parquet files. The most important ones are the directories format for smaller datasets for debugging and tar files utilized by the WebDataset format for loading.
Reprocessing
video2dataset can reprocess earlier output datasets by reading the output shards and passing the samples through new transformations. This functionality is particularly advantageous for video datasets, considering their often hefty size and awkward nature. It allows us to carefully downsample the data to avoid numerous downloads of large datasets. Researchers dig into a practical example of this in the next section.
Code and details can be found in GitHub https://github.com/iejMac/video2dataset
Future Plans
- Study of a massive dataset built with the software described in this blog article, followed by public dissemination of the results of that study.
- It improved synthetic captioning. There is a lot of room for innovation in synthetic captioning for videos. Soon in video2dataset, researchers will have more interesting methods to produce captions for videos that use image captioning models and LLMs.
- Whisper’s ability to extract numerous text tokens from the video has been the subject of much discussion since its release. Using video2dataset, they are currently transcribing a sizable collection of podcasts to make the resulting text dataset (targeting 50B tokens) publicly available.
- Many exciting modeling ideas. Hopefully, with improved dataset curation tooling, more people will attempt to push the SOTA in the video and audio modality.
video2dataset is a fully open-source project, and researchers are committed to developing it in the open. This means all the relevant TODOs and future directions can be found in the issues tab of the repository. Contributions are welcomed; the best way to do that is to pick out a problem, address it, and submit a pull request.
Check out the Blog and Github Link. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.