Latest AI Research at Amazon Improves Forecasting by Learning the Quantile Functions
This research summary is based on the papers 'Learning quantile functions without quantile crossing for distribution-free time series forecasting' and 'Multivariate quantile function forecaster' Please don't forget to join our ML Subreddit
‘The quantile function is a mathematical function that takes a quantile (a percentage of a distribution ranging from 0 to 1) as an input and returns the value of a variable as an output.’ It can answer queries such as, “How much inventory do I need to maintain on hand if I want to guarantee that 95 percent of my customers receive their orders within 24 hours?” As a result, the quantile function is frequently utilized in forecasting questions.
However, in practice, there is rarely a neat method for computing the quantile function. Statisticians commonly approximate it using regression analysis for a single quantile level at a time. That means that if you want to compute it for a different quantile, you’ll need to create a new regression model, which nowadays usually entails retraining a neural network.
Researchers at Amazon propose a method for learning an estimate of the full quantile function at once, rather than approximating it for each quantile level, in a pair of articles published lately.
This means that users can query the function at various points to improve performance trade-offs. For example, it’s possible that lowering the promise of 24-hour delivery from 95% to 94% allows for a significantly larger reduction in inventory, which could be a worthwhile trade-off. Alternatively, it’s possible that boosting the guarantee level — and thereby enhancing customer satisfaction — just necessitates a little increase in inventory.
The technique is unconcerned about the shape of the distribution that the quantile function is based on. The distribution could be Gaussian (also known as the bell curve or normal distribution), uniform, or anything else. Because the technique does not make any assumptions about distribution shape, it can follow the data wherever it leads, increasing the accuracy of the approximations.
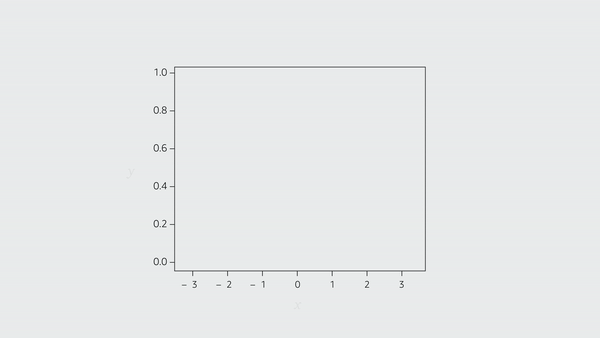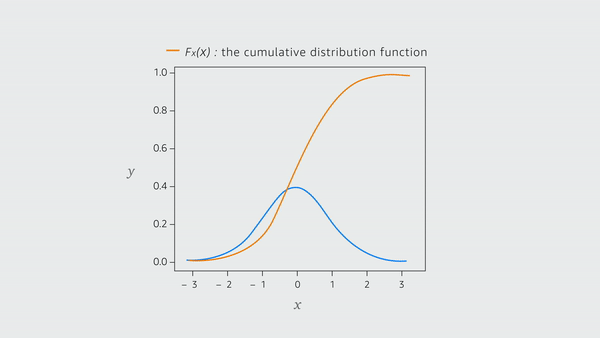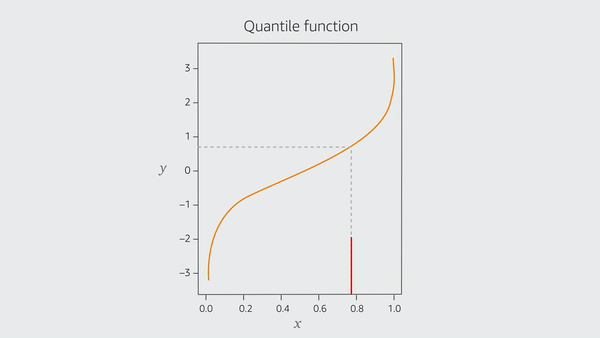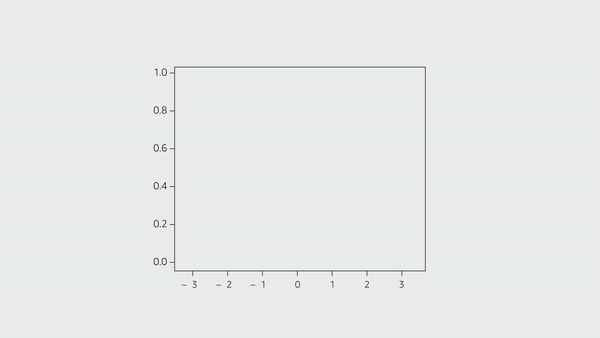
The cumulative distribution function (CDF) is a helpful related function that calculates the likelihood that a variable will take a value at or below a given value — for example, the percentage of the population that is 5’6″ or shorter. The CDF values range from 0 (no one is shorter than 0’0″) to 1 (everyone in the population is under 5’0″).
The CDF computes the area under the probability curve up to the target point since it is the integral of the Probability Distribution Function. The probability output by the CDF may be lower than the probability output by the PDF at low input values. The CDF, however, is monotonically non-decreasing because it is cumulative: the higher the input value, the higher the output value.

The quantile function is simply the inverse of the CDF if one exists. By flipping the CDF graph over — that is, turning it 180 degrees around a diagonal axis that runs from the lower left to the upper right of the graph — the quantile function graph can be created. The quantile function, like the CDF, is monotonically non-decreasing. The technique is based on this fundamental observation.
Quantile crossover is one of the downsides of the traditional way of approximating the quantile function – calculating it exclusively at specified places. Because each prediction is based on a distinct model, which has been trained on different local data, the predicted variable value for a given probability may be lower than the predicted value for a lower probability. The requirement that the quantile function is monotonically non-decreasing is broken in this case.
The method develops a predictive model for several separate input values — quantiles — at the same time, spread at regular intervals between 0 and 1 to avoid quantile crossing. The model is a neural network with each succeeding quantile’s prediction being an incremental increase over the previous quantile’s forecast.
Researchers can estimate the function using simple linear extrapolation between the anchor points (called “knots” in the literature) and nonlinear extrapolation to handle the tails of the function once the model has learned estimates for several anchor points that enforce the monotonicity of the quantile function.
When there is enough training data to allow for a higher density of anchor points (knots), linear extrapolation delivers a more accurate approximation. To demonstrate that they didn’t need to make any assumptions about distribution shape, the researchers used a toy distribution with three arbitrary peaks to test the strategy.
So far, we’ve only looked at the case where distribution is applied to a single variable. Researchers, on the other hand, seek to examine multivariate distributions in many practical forecasting use cases. For example, if a product utilizes a rare battery that isn’t included, a forecast of demand for that battery will very certainly be associated with the forecast of demand for that product.
The issue is that the concept of a multivariate quantile function is vague. When the CDF maps several variables to a single probability, which value do you map to when you reverse the process?
In the second study, the researchers resolve this issue. The main point is that the quantile function must be non-decreasing monotonically. As a result, the multivariate quantile function is defined as the derivative of a convex function by academics.
A convex function is one that tends to a single global minimum everywhere; it looks like a U-shaped curve in two dimensions. The slope of a convex function’s graph is computed by its derivative: in the two-dimensional instance, the slope is negative but flattens as it approaches the global minimum, zero at the lowest and more positive on the opposite side. As a result, the derivative is increasing monotonically.
This two-dimensional image can easily be extrapolated to greater dimensions. The team explains how to train a neural network to learn a quantile function, which is the derivative of a convex function, in the study. Convexity is enforced by the network’s architecture, and the model learns the convex function by using its derivative as a training signal.
Researchers use a dataset that follows a multivariate Gaussian distribution to test the technique on the challenge of simultaneous prediction across several time horizons, in addition to real-world datasets. Indeed, the technique captures the correlations between consecutive time ranges better than a univariate approach, according to the trials.
Paper 1: https://www.amazon.science/publications/learning-quantile-functions-without-quantile-crossing-for-distribution-free-time-series-forecasting
Paper 2: https://www.amazon.science/publications/multivariate-quantile-function-forecaster
References:
- https://www.amazon.science/blog/improving-forecasting-by-learning-quantile-functions
Suggested
Credit: Source link
Comments are closed.