Latest Amazon Artificial Intelligence (AI) Research Proposes a Novel Human-in-the-Loop Framework for Generating Semantic-Segmentation Annotations for Full Videos
Compared to unsupervised learning, supervised learning produces more accurate results in computer vision (CV). Supervised learning makes use of annotated datasets to develop algorithms for classification or prediction. However, the data annotation process is laborious, time-consuming, and requires much human effort. This operation becomes considerably more expensive when using semantic segmentation, as it involves annotating every pixel in an image. However, accurate per-pixel semantic annotation is necessary for training and assessing semantic segmentation algorithms when dealing with video datasets. However, when it comes to videos as opposed to images, the expense of annotation becomes even more prohibitive, which is why annotations are frequently restricted to a small fraction of the video content.
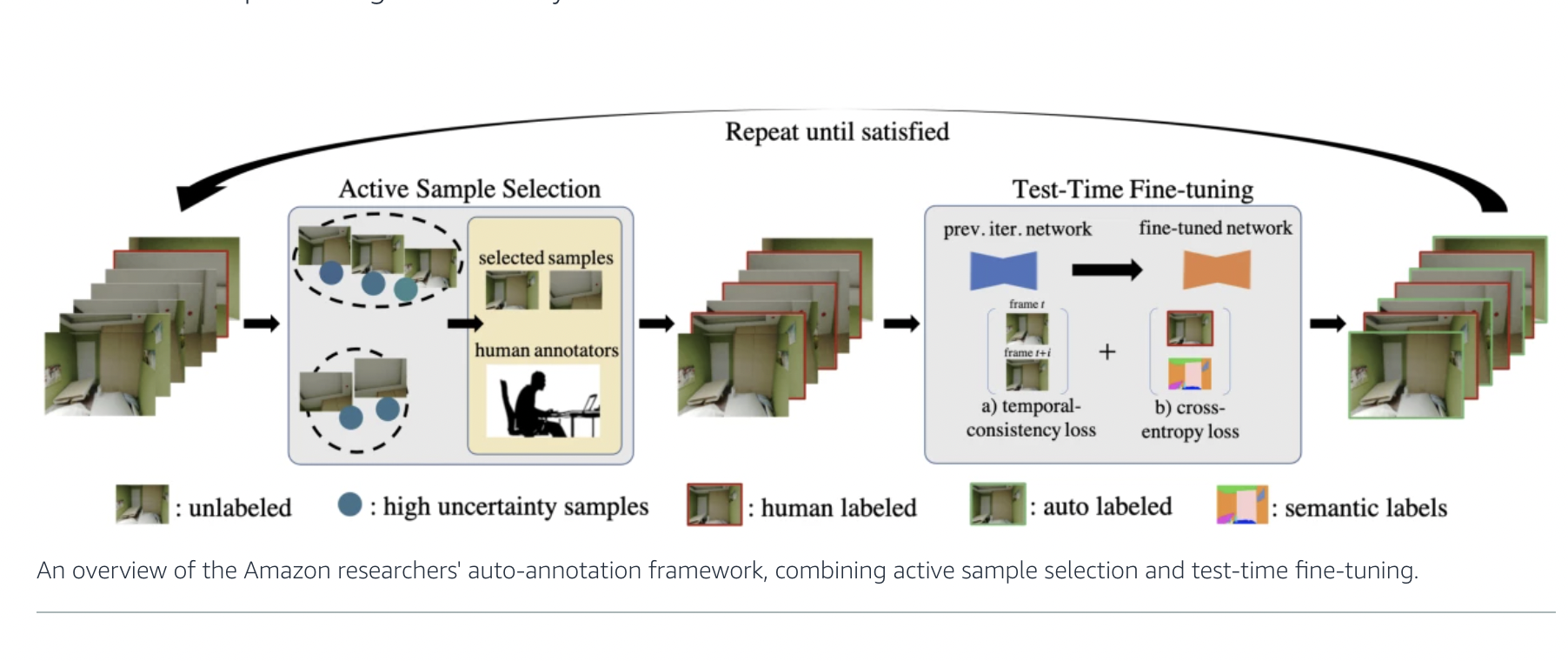
To address this problem, a team of researchers at Amazon developed Human-in-the-loop Video Semantic segmentation Auto-annotation (HVSA). This cutting-edge framework is capable of providing semantic segmentation annotations for a full video quickly and more effectively. HVSA continually switches between active sample selection and test-time fine-tuning until annotation quality is assured. While test-time fine-tuning propagates the manual annotations of selected samples to the entire video, active sample selection sets the most crucial examples for manual annotation. The researchers’ work will also be presented at the prestigious Winter Conference on Applications of Computer Vision (WACV).
The team employs a pre-trained network to perform semantic segmentation on videos. Their method entails tailoring the pretrained model to a specific input video so that it can be configured to assist in annotating the video with extremely high accuracy. This method was inspired by how human annotators handle video annotation tasks. To identify the appropriate object categories, adjacent frames are examined. Moreover, existing annotations from the same video are also taken into consideration. This is how their approach makes use of test-time fine-tuning. The researchers added a new loss function that considers these two data sources to modify the pretrained network to the input video. While the second component of the loss is in charge of penalizing predictions inconsistent with existing data, the first part penalizes unreliable semantic prediction between successive frames.
HVSA uses active learning to fine-tune the model by utilizing samples that are actively chosen by the algorithm and labeled by annotators in each iteration. Uncertainty sampling is the primary essence behind active learning. In simple terms, a sample should be chosen for manual annotation if a network predicts its label with insufficient confidence. Uncertainty sampling is inadequate on its own, though. The researchers also looked at diversity sampling to ensure that the samples were distinct. Such kinds of samples were generated using clustering-based sampling. The overall strategy can be summarised as initially performing an active selection of the annotation samples that provide the most information during each iteration. Once these chosen samples receive manual annotations, the team’s method uses semantic knowledge and temporal limitations to refine the video-specific semantic segmentation model. The entire video can be annotated using this model.
It was discovered through experimental evaluations on two datasets that Amazon’s HVSA achieves impressive accuracy (over 95%) and nearly flawless semantic segmentation annotations. The fact that it accomplishes these objectives with the least amount of annotation time and expense strikes it as a differentiating factor. HVSA only requires a few dozen minutes for each iteration. The researchers are further looking into optimizing this using multi-task parallelization.
Check out the Paper and Blog Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.