Latest Artificial Intelligence (AI) Paper From Alibaba Proposes VQRF, A Novel Compression Framework Designed For Volumetric Radiance Fields Like DVGO And Plenoxels.

Due to its potential usage in several Virtual Reality and Augmented Reality applications, the subject is becoming increasingly important. When given a collection of photos taken from various viewpoints with known camera postures, novel view synthesis seeks to achieve photo-realistic depiction for a 3D scene at undiscovered perspectives. Neural radiance fields (NeRF) have successfully modeled and rendered 3D scenes using deep neural networks. These networks are trained to map each 3D position given a viewing direction to its associated view-dependent color and volume density using volumetric rendering techniques.
Due to the rendering process’ dependency on selecting a considerable number of points for sampling and running them through a complicated network, there is a sizable computing cost during training and inference. Voxel-based structures may considerably increase training and inference efficiency, as evidenced by recent improvements after the reconstruction of radiance fields. These volumetric radiance field methods often store features and retrieve sampling points (such as color features and volume densities) by effectively trilinear interpolating without neural networks. They have a little neural network installed.

DVGO and Plenoxels.
They replaced intricate networks. However, employing volumetric representations always entails large storage costs, such as the over 100 terabytes needed to represent the scene in Figure 1, which makes it impractical for use in real-world scenarios. Voxel grids have a storage issue that has to be solved while preserving rendering quality. To better comprehend the characteristics of grid models, the distribution of voxel importance scores was estimated. Only 10% of voxels contribute more than 99% of a grid model’s importance scores, which shows the model has a lot of redundancy.
The method they provide for compressing volumetric radiance fields allows for a 100 per cent storage decrease over the original grid models while maintaining comparable rendering quality. Figure 2 displays an illustration of the framework. The suggested framework is not specific to any architecture but extremely broad. The framework comprises three processes—voxel trimming, vector quantization, and post-processing. The least significant voxels that dominate model size while making a minimal contribution to the final rendering are removed via voxel pruning. Using a cumulative score rate measure, they present an adaptive pruning threshold selection technique, making the pruning strategy applicable to various scenes or base models.
By creating importance-aware vector quantization with an effective optimization strategy, they propose to encode significant voxel features into a compact codebook to reduce the model size further. A joint tuning mechanism encourages the compressed models to approach the rendering quality of the original models. Finally, they carry out a quick post-processing step to get a model with a low storage cost. As seen in Figure 1, for instance, a model with a storage cost of 104 MB and a PSNR of 32.66 may be compressed into a model with a cost of 1.05 MB and just a minimal loss in visual quality (PSNR of 32.65).
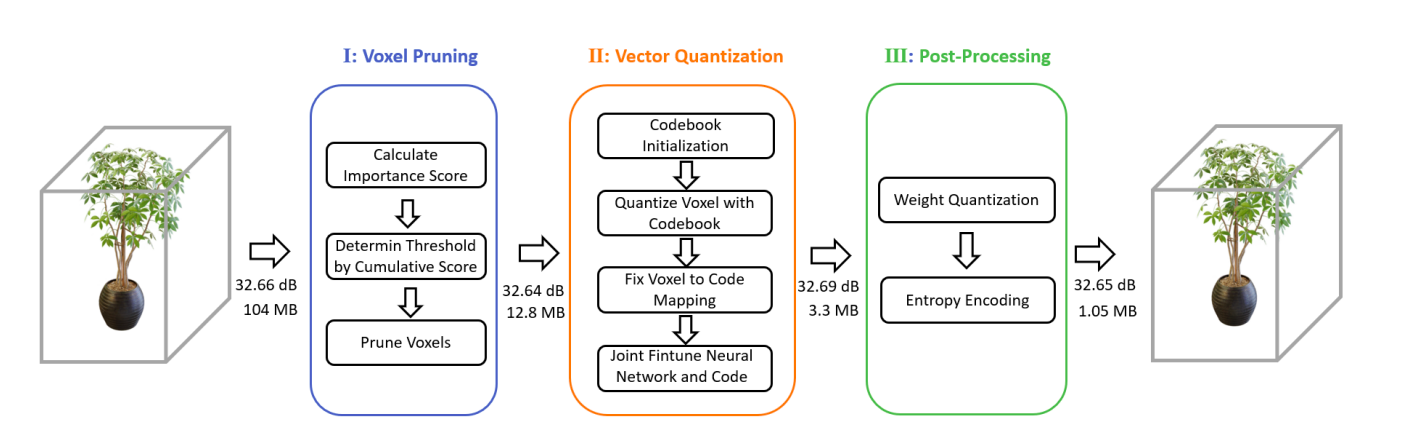
To validate the proposed compression framework, they undertake in-depth experiments and practical investigations that demonstrate the efficacy and generalizability of the proposed compression pipeline on a wide variety of volumetric approaches and different circumstances.
Check out the Paper and Github. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.