Latest Artificial Intelligence (AI) Research Brings a brand-New Method Called ‘ANGIE’ That Efficiently Records Reusable Co-Speech Gesture Patterns And Fine-Grained Rhythmic Movements

Humans typically use co-speech gestures to express their thoughts in addition to spoken channels throughout the everyday conversation. These nonverbal cues improve speech comprehension and establish the communicator’s credibility. As a result, teaching the social robot conversational abilities is an essential first step in enabling human-machine contact. To accomplish this, researchers work on co-speech gesture generation, synthesizing audio-coherent human gesture sequences as structural human representations. The target speaker’s appearance information, which is essential for human perception, is absent from such a representation. It has been shown that creating real-world subjects in the image domain is highly desirable in audio-driven talking head synthesis.

To do this, they investigate the issue of generating co-speech gesture videos that are audio-driven, i.e., using a unified framework to create speaker picture sequences that are driven by spoken audio (illustrated in Fig. 1). The speech-gesture pairings and connection rules must be defined beforehand in conventional approaches to providing coherent results. As deep learning has advanced, neural networks are being used to learn the data-driven mapping of recorded acoustic features to human skeletons. Notably, one group of methods uses small-scale MoCap datasets in a co-speech environment, which results in particular models with constrained capabilities and robustness. Another family of approaches creates a big training corpus by utilizing off-the-shelf pose estimators to label vast online movies as pseudo-ground truth to capture more generic speech-gesture correlations.
The resulting results, however, are unnatural because the erroneous pose annotations cause error accumulation in the training phase. In addition, the co-speech gesture video creation issue needs to be addressed in most earlier efforts. Only a few works use pose-to-image generators to train on target person’s photos when animating in the image domain as a separate post-processing step. How to create a unified framework to generate speaker picture sequences based on vocal recordings still needs to be determined. They highlight two findings from recent experiments that are crucial to understanding how to learn the mapping from audio to co-speech gesture video:
1) Articulated human body region information would be eliminated by manually created structural human priors such as 2D/3D skeletons. Similar to local affine transformation in image animation, such a zeroth-order motion representation cannot formulate first-order motion. Additionally, cross-modal audio-to-gesture learning needs to be improved for the inaccuracy in previous structural labeling.

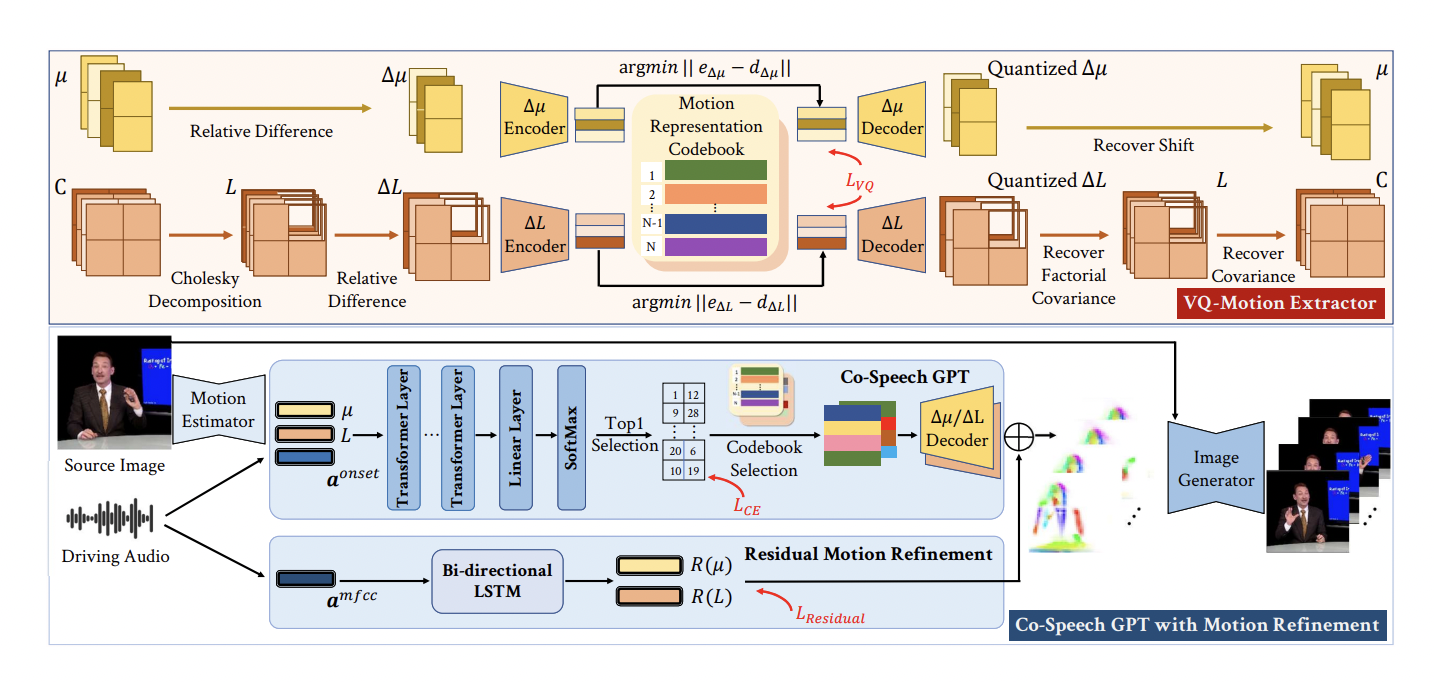
2) Co-speech gestures can be divided into common motion patterns and rhythmic dynamics, where the former corresponds to large-scale motion templates (e.g., periodically putting hands up and down), and the latter serves as a refinement to complement delicate prosodic motions and synchronize with spoken audio (e.g., finger flickers). They are motivated by the above observations and suggest a novel framework called Audio-driveN Gesture vIdeo gEneration (ANGIE) to produce co-speech gesture video.
Motion residuals can further refine delicate rhythmic details for fine-grained results. In particular, the VQ-Motion Extractor and Co-Speech GPT modules have been developed. They use an unsupervised motion representation in VQ-Motion Extractor to show the articulated human body and first-order motions. From unsupervised motion representation, the codebooks are created to quantize the reusable common co-speech gesture patterns. They provide a quantization approach based on Cholesky decomposition to ease the motion component constraint and ensure the validity of gesture patterns. The fundamental finding is that typical co-speech gesture patterns may be summarised from motion representation to quantized codebooks.
The position-irrelevant motion pattern is extracted as the final quantization target to represent the relative motion. As a result, the quantized codebooks automatically provide extensive information about popular gesture patterns. They have made three important contributions:
1) The difficult issue of audio-driven co-speech gesture video creation is explored. In Co-Spoken GPT, they employ a GPT-like structure to predict discrete motion patterns from speech audio using the quantized motion code sequence. A motion refinement network is required in addition to minor rhythmic elements to achieve fine-grained results. They are the first, as far as they are aware, to develop a co-speech gesture in the image domain using a unified framework without having previously used a human structural body.
2) They suggest the Co-Speech GPT enhances fine rhythmic movement details and the VQ-Motion Extractor to quantize the motion representation into common gesture patterns. Naturally, reusable motion pattern data is present in the codebooks.
3) Numerous tests show that the suggested framework, ANGIE, produces co-speech gesture video production outcomes that are vivid and lifelike. The code will be released soon.
Check out the Paper and Project. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.