Latest Artificial Intelligence (AI) Research From NVIDIA Shows How To Animate Portraits Using Speech And A Single Image

Artificial Intelligence (AI) has been a topic of increasing importance in recent years. Technological advances have made it possible to solve tasks that were once considered intractable. As a result, AI is increasingly being used to automate decision-making in a wide range of domains. One of these tasks is animating portraits, which involves the automatic generation of realistic animations from single portraits.
Given the complexity of the task, animating a portrait is an open problem in the field of computer vision. Recent works exploit speech signals to drive the animation process. These approaches try to learn how to map the input speech to facial representations. An ideal generated video should have good lip sync with the audio, natural facial expressions and head motions, and high frame quality.
State-of-the-art techniques in this field rely on end-to-end deep neural network architectures consisting of pre-processing networks, which are used to convert the input audio sequence into utilizable tokens, and a learned emotion embedding to map these tokens into the corresponding poses. Some works focus on animating 3D vertices of a face model. These methods, however, require special training data, such as 3D face models, which may not be available for many applications. Other approaches work on 2D faces and generate realistic lip motions according to the input audio signals. Despite the lip motion, their results lack realism when used with a single input image, as the remainder of the face remains stationary.
The goal of the presented method, termed SPACEx, is to use 2D single images in a clever way to overcome the limitations of the mentioned state-of-the-art approaches while obtaining realistic results.
The architecture of the proposed method is depicted in the figure below.
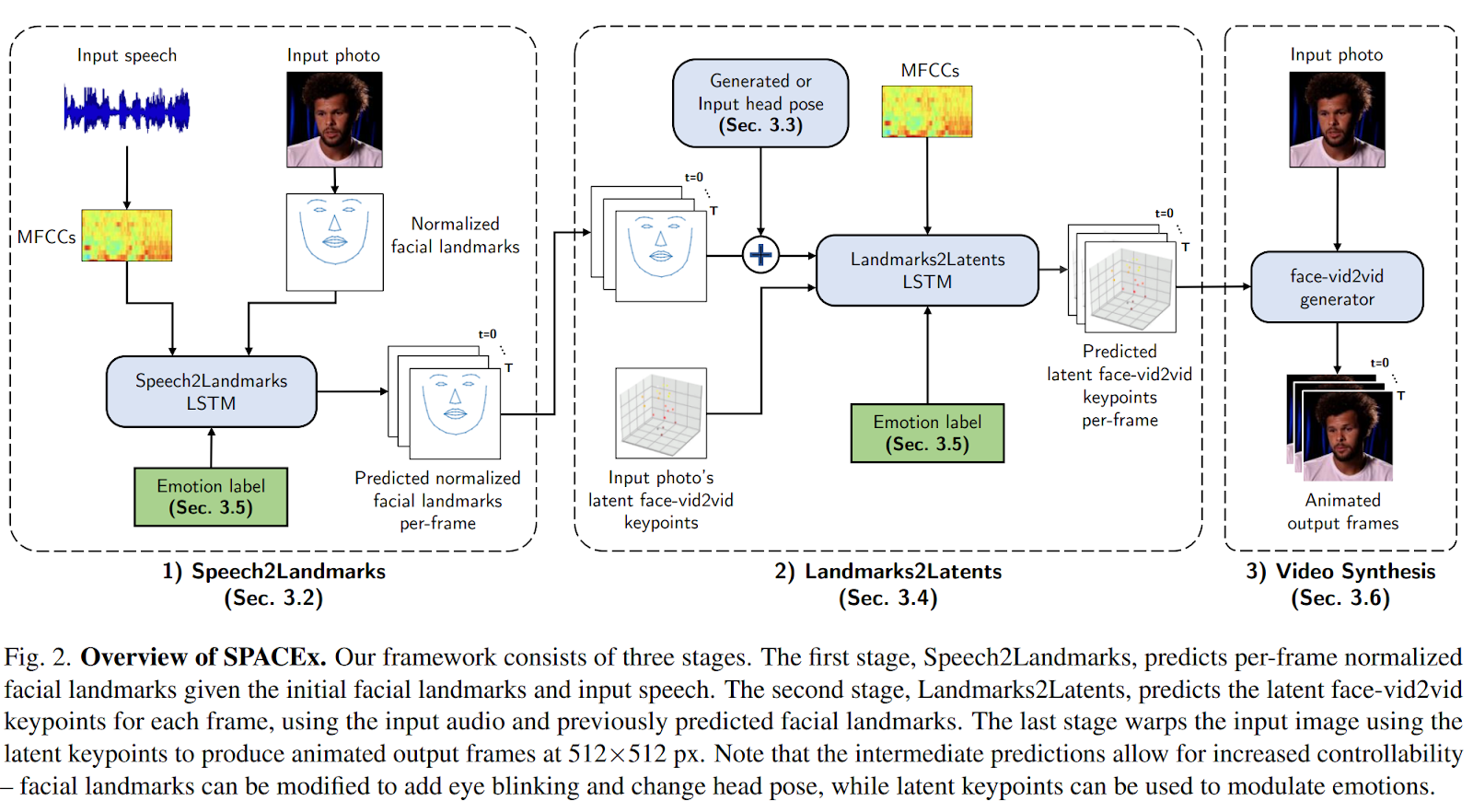
SPACEx takes an input speech clip and a face image (with an optional emotion label) and produces an output video. It combines the benefits of the related works by using a three-stage prediction framework.
First, given an input image, normalized facial landmarks are extracted (Speech2Landmarks in the figure above). The neural network uses the computed landmarks to predict their per-frame motions based on the input speech and emotion label. The input speech is not fed directly to the landmark predictor. 40 Mel-Frequency Cepstral Coefficients (MFCCs) are extracted from it using a 1024 sample FFT (Fast Fourier Transform) window size at 30 fps (to align the audio features with the video frames).
Second, the per-frame posed facial landmarks are converted into latent keypoints (Landmarks2Latents in the figure above).
Last, given the input image and the per-frame latent keypoints predicted in the previous step, face-vid2vid, a pretrained image-based facial animation model, outputs an animated video with frames at 512×512 px.
The proposed decomposition has multiple advantages. First, it allows for fine-grained control of the output facial expressions (like eye blinking or special head pose). Further, latent keypoints can be modulated with emotion labels to change the expression intensity or control the gaze direction. By leveraging a pretrained face generator, training costs are substantially reduced.
Moving to the experiments part, SPACEx has been trained on three different datasets (VoxCeleb2, RAVDESS, and MEAD) and compared to prior works on speech-driven animation. The metrics used for the comparison are (i) lip sync quality, (ii) landmark accuracy, (iii) photorealism (FID score), and (iv) human evaluation.
According to the paper’s results, SPACEx achieves the lowest FID and normalized landmark distance compared to the other approaches. These results imply that SPACEx produces the best image quality and obtains the highest accuracy in landmark estimation. Below are reported some of the outcomes.

Unlike SPACEx, previous methods suffer from degraded quality or fail for arbitrary poses. In addition, SPACEx is also able to generate missing details, such as teeth, while other methods either fail or introduce artifacts.
This was a summary of SPACEx, a novel end-to-end speech-driven method to animate portraits. You can find additional information in the links below if you want to learn more about it.
Check out the Paper and Project Page. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.