Latest CMU Research Improves Reinforcement Learning With Lookahead Policy: Learning Off-Policy with Online Planning
Reinforcement learning (RL) is a technique that allows artificial agents to learn new tasks by interacting with their surroundings. Because of their capacity to use previously acquired data and incorporate input from several sources, off-policy approaches have lately seen a lot of success in RL for effectively learning behaviors in applications like robotics.
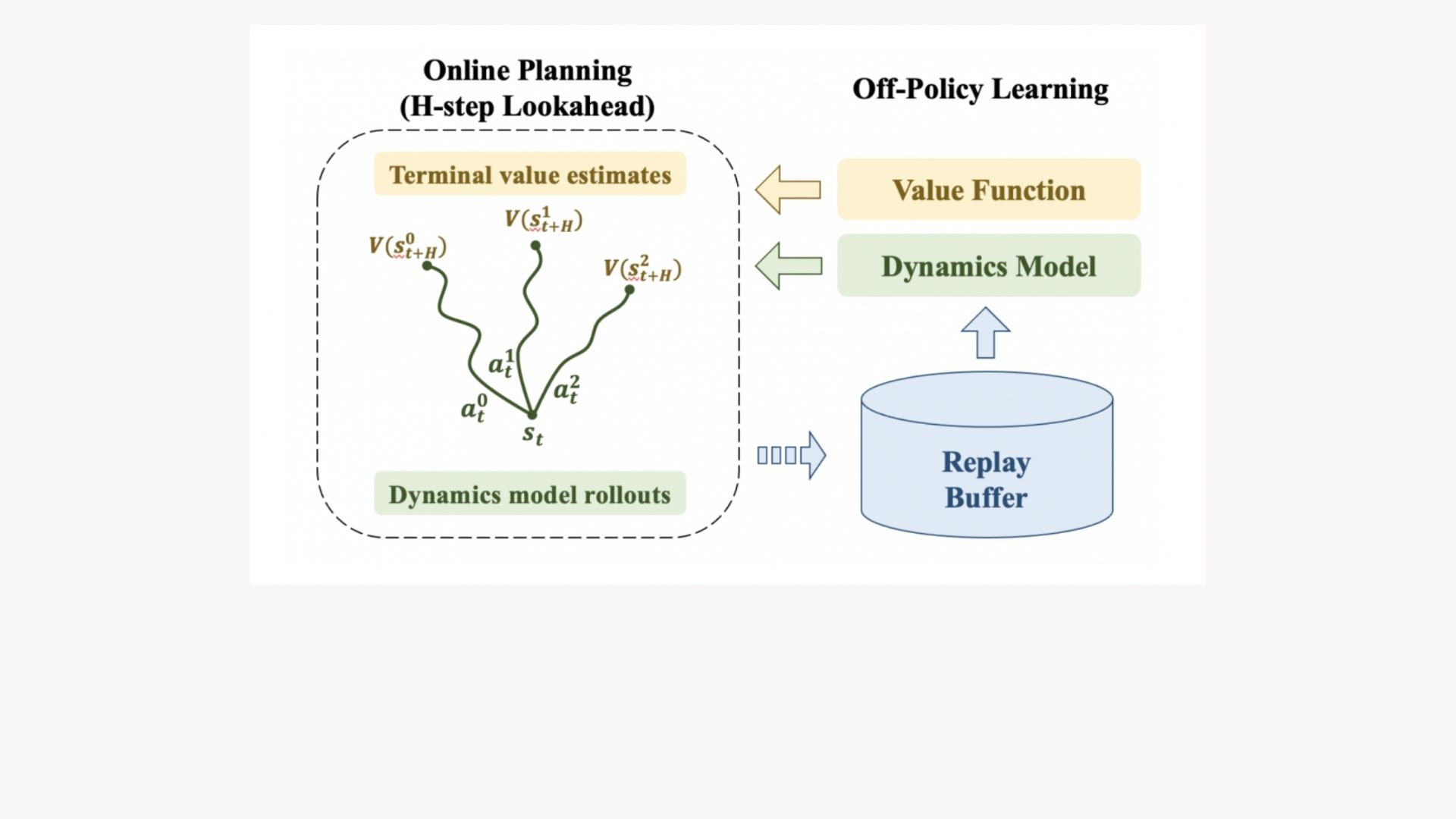
What is the mechanism of off-policy reinforcement learning? A parameterized actor and a value function are generally used in a model-free off-policy reinforcement learning approach (see Figure 2). The transitions are recorded in the replay buffer as the actor interacts with the environment. The value function is updated by maximizing the action values at the stages visited in the replay buffer. The actor is trained using the transitions from the replay buffer to forecast the cumulative return of the actor.
The researchers propose employing a policy that uses a trained model to discover the optimum action sequence in the future. This lookahead policy is easier to understand than the parametric actor, allowing us to add restrictions. Then they offer LOOP, a computationally efficient learning system based on the lookahead strategy. They also explain how LOOP may be used in offline and safe RL settings in addition to the online RL context.
The H-step Lookahead Policy allows planning ahead of time.
Researchers employ online planning (“H-step lookahead”) with a terminal value function to improve performance, safety, and interpretability. Researchers use a learned dynamics model in the H-step lookahead to roll out action sequences for H-horizon into the future and calculate the cumulative reward. They connect a value function to reason about the future reward beyond H steps at the end of the rollout. The aim is to choose the action sequence that will lead to the best cumulative return on rollout.
H-step lookahead has several advantages:
- Using model rollouts, H-step lookahead decreases reliance on value function errors, allowing it to tradeoff value errors with model errors.
- H-step lookahead provides a level of interpretability not seen in completely parametric techniques.
- H-step lookahead allows users to include non-stationary restrictions and behavior priors during deployment.
Researchers may also offer theoretical assurances that show that utilizing an H-step lookahead instead of a parametric actor (1-step greedy actor) can significantly minimize value error dependency while raising model error dependency. Despite the increased model mistakes, they believe the H-step lookahead is beneficial since value errors can occur for various causes, as stated in the preceding section. Value mistakes might arise from compounding sampling errors in the low data regime, but the model should have fewer errors if trained with denser supervision using supervised learning. Researchers believe that the tradeoff of value mistakes with model errors is helpful due to the multiple sources of errors in value learning. They observe empirical support for this in our studies.
LOOP: Online Planning for Off-Policy Learning
As stated above, the H-step lookahead policy applies a terminal value function after the H steps. However, assessing the H-step lookahead policy is time-consuming (Lowrey et al.) since the lookahead policy necessitates simulating H-step dynamics, which is computationally expensive. The problem is that they have to evaluate the H-step lookahead strategy from various stages while learning a value function. How can they figure out this H-step lookahead policy’s value function?
Instead, researchers suggest teaching a parameterized actor to learn the terminal value function more efficiently; instead of evaluating the H-step lookahead policy, they may determine the actor (which is fast) to understand the value function (which is slow). This method is known as LOOP: Learning off-policy with online planning. However, there may be a discrepancy between the H-step lookahead policy and the parametric actor, which is a flaw in this technique (see Figure 3). The disparity in these policies might lead to insecure learning, which they call “actor divergence.”
Researchers propose actor regularised control (ARC) based on the following goal. The H-step lookahead policy based on the KL-divergence is constrained to a prior, where the primary is based on the parametric actor, as our solution to actor divergence. This limited optimization ensures that the H-step lookahead policy stays close to the parametric actor, resulting in more regular training.
LOOP for Safe and Offline RL
Researchers saw how ARC optimizes for expected return in the previous section in the online RL environment. LOOP may be used in two other domains: 1. Offline RL: Using a fixed dataset of gathered data to learn. 2. Safe RL: Learning to maximize rewards while keeping constraint violations below a certain level.

Offline RL: Using D4RL datasets, we combine LOOP with two offline RL methods: Critic Regularized Regression (CRR) and Policy in Latent Action Space (PLAS). On the D4RL locomotion datasets, LOOP outperforms CRR and PLAS by an average of 15.91 percent and 29.49 percent, respectively. This shows that H-step lookahead outperforms a pre-trained value function (obtained offline RL) by lowering reliance on value mistakes.

Safe RL: Researchers experiment on the OpenAI safety gym scenarios to assess LOOP’s safety performance. In both the CarGoal and PointGoal scenarios, the agent must maneuver to a goal while avoiding obstacles.
Future Steps
This framework disentangles the exploitation policy (parametrized actor) from the exploration strategy (H-step lookahead) to some extent. The flexibility to add non-stationary exploration priors is one advantage of employing H-step lookahead for deployment. An intriguing next option is to investigate how more principled exploration strategies might enable data collecting that leads to improved policy development.
Paper: https://arxiv.org/pdf/2008.10066.pdf
Project: https://hari-sikchi.github.io/loop/
Github: https://github.com/hari-sikchi/LOOP
Reference: https://blog.ml.cmu.edu/2022/01/07/loop/
Suggested

Credit: Source link
Comments are closed.