Latest Computer Vision Research From China Proposes a Point-Track-Transformer (PTT) Module for Point Cloud-Based 3D Single Object Tracking Task
Single Object Tracking (Sot) With Lidar Points Has Many Applications In Robotics And Automatic Driving. For example, the autonomous pedestrian following robot should be able to monitor and adequately locate its master to provide adequate control in a crowd. Another example is the autonomous landing of uncrewed aerial vehicles, in which the drone must follow the target and determine the precise distance and posture of the target in order to land safely. However, most current 3D SOT approaches rely on visual or RGB-D cameras, which may fail in visually impaired or changing lighting conditions since they rely heavily on dense pictures for target tracking.
3D LiDAR and visual or RGB-D sensors are commonly utilized in object tracking jobs because they are less susceptible to light changes and can more precisely collect geometry and distance information. Unlike previous LiDAR-based Multi-object Tracking (MOT) approaches, LiDAR-based 3D SOT methods must model the similarity function. The similarity function between the target and search region is modeled in a way to locate the target item. Even though they both need similarity computation, MOT approaches compute object-level similarity to associate detection results with tracklets. In contrast, SOT methods compute intra-object-level similarity to pinpoint the target object.
As a result, 3D SOT presents unique issues compared to 3D MOT. SC3D is the first LiDAR-based 3D Siamese tracker that uses the shape completion network. However, the approach only processes the input point cloud with an encoder composed of three layers of one-dimensional convolutions, making it impossible to extract the robust point cloud feature representation. Furthermore, SC3D could not be operated in real-time and trained from start to finish. The researchers have also proposed a point-to-box (P2B) network to estimate the target bounding box from the raw point cloud. However, their technique frequently fails to track in sparse point cloud circumstances.
Meanwhile, P2B does not favor nonaccidental coincidences that contribute more to pinpointing the target center. Fang et al. recently merged a Siamese network with a LiDAR-based RPN network to handle 3D object tracking. Nonetheless, they utilize the classification scores directly to rank regression findings, ignoring the mismatch between localization and classification. It is worth noting that points in different geometric locations have varying degrees of value when depicting goals. These techniques, however, do not weigh point cloud features based on this attribute. Furthermore, due to the sparsity and occlusion of point clouds, the point cloud features recovered from the template and search region include less potential object information and more background noise.
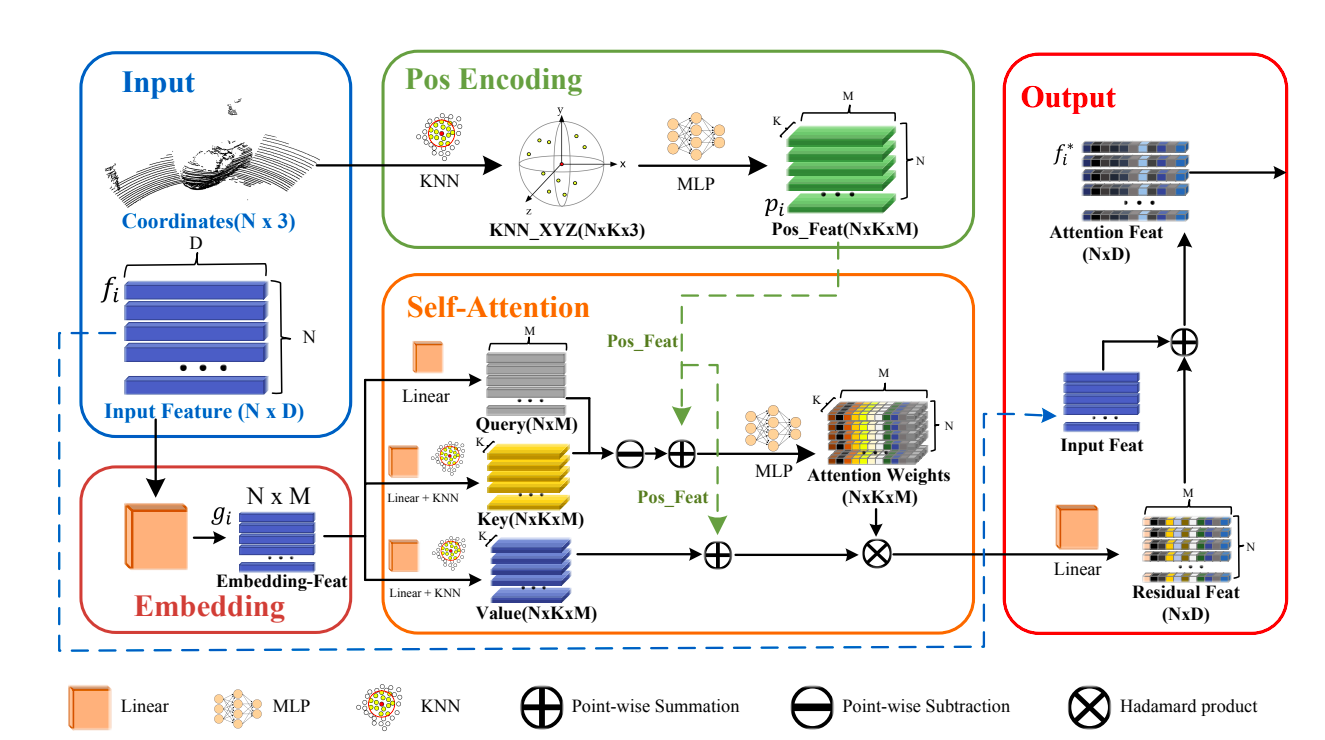
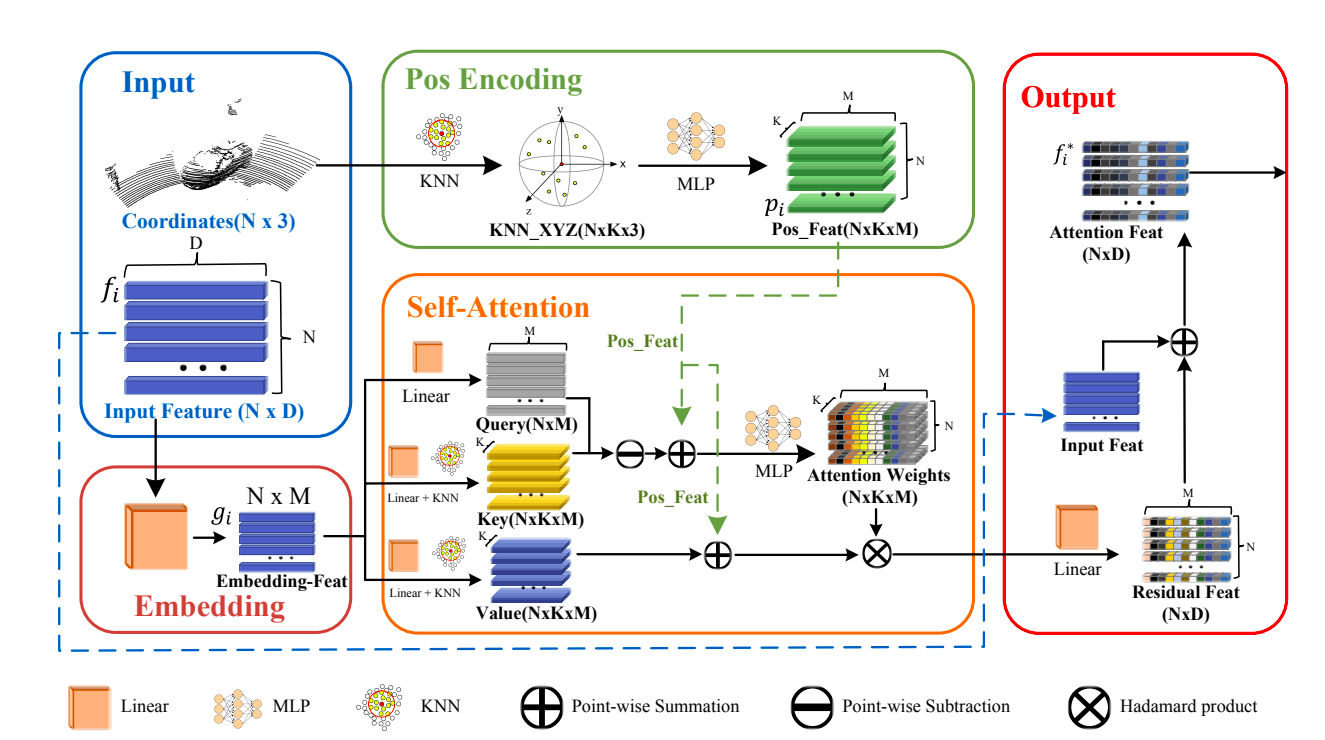
The PTT modules’ architecture is divided into three sections: feature embedding, location encoding, and self-attention. The input is the coordinates and their associated characteristics. The feature embedding module converts the supplied features to embedding space. The k-nearest neighbor is used in the position encoding module. After using a method to gather local location information, an MLP layer will learn the encoded position characteristics. The self-attention module is learned based on local context. The PTT module’s output features are the sum of the input and residual characteristics.
As a result, understanding how to pay attention to spatial cues is critical to improving the effectiveness of the 3D object tracker. The transformer has recently demonstrated exceptional performance in feature encoding thanks to its robust self-attention module. Transformers typically have three major modules: input (word) embedding, position encoding, and an attention module. Position encoding encodes point cloud coordinates into high dimension identifiable features. By computing attention weights, self-attention creates enhanced attention characteristics. Furthermore, to test the usefulness of their PTT module, they integrated it into the dominating P2B to create a revolutionary 3D SOT tracker called PTT-Net. PTT is now included in the voting and proposal creation stages of PTT-Net.
PTT incorporated in the voting stage might mimic interactions among point patches in different geometric placements, learning context-dependent characteristics and assisting the network in focusing on more representative object attributes. Meanwhile, PTT incorporated in the proposal generation step might gather contextual information between the item and the backdrop, assisting the network efficiently suppressing background noise. These changes can significantly enhance the performance of the 3D object tracker. The experimental findings of their PTT-Net on the KITTI tracking dataset show that their technique is superior (a 10% improvement over the baseline).
They further test their PTT-Net on the NuScenes dataset, and the findings demonstrate that their technique has the potential to attain new state-of-the-art performance. PTT-Net may also run in real-time at 40FPS on a single NVIDIA 1080Ti GPU.
The contributions can be summarised as:
• PTT module: TA Point-Track-Transformer (PTT) module for 3D single object tracking using raw point clouds, which may balance point cloud attributes to focus on deeper-level object indications during tracking.
• PTT-Net: A 3D single object tracking network embedded with PTT modules that can be taught from start to finish. To their knowledge, this is the first effort that uses a transformer to do 3D object tracking with point clouds.
• Open-source: Comprehensive testing on the KITTI and NuScenes datasets reveal that their technique beats state-of-the-art solutions by significant margins at 40 FPS. Furthermore, they make their open source approach available to the scholarly community.
PyTorch implementation of the PTT module can be freely found on GitHub.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Real-time 3D Single Object Tracking with Transformer'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Asif Razzaq is an AI Journalist and Cofounder of Marktechpost, LLC. He is a visionary, entrepreneur and engineer who aspires to use the power of Artificial Intelligence for good.
Asif’s latest venture is the development of an Artificial Intelligence Media Platform (Marktechpost) that will revolutionize how people can find relevant news related to Artificial Intelligence, Data Science and Machine Learning.
Asif was featured by Onalytica in it’s ‘Who’s Who in AI? (Influential Voices & Brands)’ as one of the ‘Influential Journalists in AI’ (https://onalytica.com/wp-content/uploads/2021/09/Whos-Who-In-AI.pdf). His interview was also featured by Onalytica (https://onalytica.com/blog/posts/interview-with-asif-razzaq/).
Credit: Source link
Comments are closed.