Latest Computer Vision Research From China Proposes ‘MapTR’; An Advanced Framework for Creating HD Vectorized Map of the Cityscape to Bolster Autonomous Driving Research

Constructing a high-definition map of street view is extremely useful and necessary for autonomous driving. An HD map of street view comprises all pedestrians or other objects crossing roads, lane detection, symbols, and many other detailed map reconstructions.
The progress started with the available frameworks being mostly offline; that is, a map is pre-created based on the images and transferred to the user-end. This type of framework involves excessive costs to create and store offline maps. And most of those frameworks available are based on single-view camera elements, which miss lots of necessary information, and recovering or estimating them is not effective. So, there comes the need for an advanced map reconstruction framework to create HD maps online from a birds-eye view. Even after getting a birds-eye-view, it is not easy to efficiently use it to build a framework. For example, the bird-eye-view’s semantically segmented image is used as a map. This is effective but cannot capture significant information, like if there are specific symbols in the lane. This can be solved by doing some post-processing, but that’s very costly and time-consuming too. This issue has been further resolved by using a directed polyline for lane symbols. Here the challenge is how to direct a polygon for a pedestrian crossing a lane, or lane-divider etc. MapTR aims to solve this problem. We’ll discuss here how they have done it.
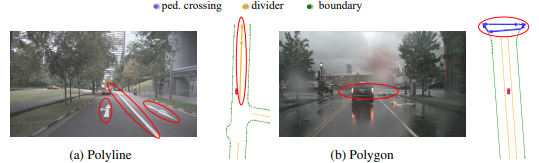
At first, each map element is classified as an open shape or closed shape. An open shape element is an element, which can have two starting points, and based on them, it can go to either forward or backward; an example is a lane divider. On the other hand, a closed shape element can have a starting point at any point inside the shape, and for each start point, the direction can be either forward or backward. So, to model this efficiently, they have represented each open shape element as a polyline and each closed shape element as a polygon. Basically, both of them is an ordered point set consisting of N points (say). Now to model open shape and closed shape elements, all N points in a polyline can be permuted in 2 ways only, and for a polygon, each point can be a starting point and have two directions, so for all N points, there can be a total of 2N permutations.
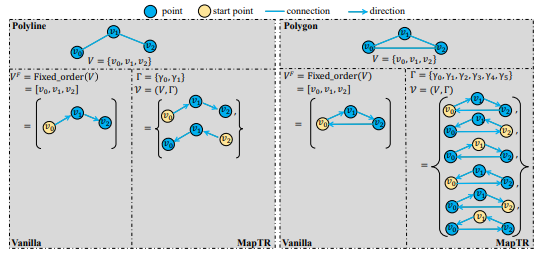
Now we’d discuss how the training procedure is done. The training data has the class label, ordered point set, and permutation of each element as the ground truth. Now for each forward pass, a set of map elements is predicted, along with their classification score and predicted ordered point set. At first, segmentation is done by instance-level-matching, which is basically which instances produce the least cost. There are two parts to this cost; the first part is Focal loss, which is basically the classification error; and the other part is the Positional cost, which is the error of predicting the ordered point set. After instance-level matching, the optimal permutation of the point set is to be found. This is done by point-level-matching, which is basically optimizing the error of the predicted point set for all possible permutations and selecting the permutation with the least error. And for accurately representing map elements, the cosine similarity of predicted edges are also optimized. An encoder is used to extract features, and a map decoder is used for prediction. In the decoder, each map element is represented by a set of hierarchical queries of instance-level queries and a set of point-level queries shared by all instances. The model is trained in an end-to-end fashion by summing all the losses, that’s, Focal loss and positional loss for instance-level-matching, point-to-point loss and edge direction loss for point-level-matching.
MapTR gave the best performance when a ResNet50 architecture is used as a backbone feature extractor and trained for more than 100 epochs. This high-quality work can be well-applied in the self-driving system and can be used for a lot of downstream tasks like motion prediction and planning of an autonomous car.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'MAPTR: STRUCTURED MODELING AND LEARNING FOR ONLINE VECTORIZED HD MAP CONSTRUCTION'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
I’m Arkaprava from Kolkata, India. I have completed my B.Tech. in Electronics and Communication Engineering in the year 2020 from Kalyani Government Engineering College, India. During my B.Tech. I’ve developed a keen interest in Signal Processing and its applications. Currently I’m pursuing MS degree from IIT Kanpur in Signal Processing, doing research on Audio Analysis using Deep Learning. Currently I’m working on unsupervised or semi-supervised learning frameworks for several tasks in audio.
Credit: Source link
Comments are closed.