Latest Computer Vision Research Present a Novel Audio-Visual Framework, ‘ECLIPSE,’ for Long-Range Video Retrieval
Video has become the primary way of sharing information online. Around 80% of the entire Internet traffic consists of video content, and the growth is likely to continue in upcoming years. Therefore, there is a massive amount of video data available nowadays.
We all use Google to retrieve information online. If we search for a text about a specific topic, we write the keyword, and we are greeted by the sheer amount of posts written about the very same topic. The same goes for image searching; just write the keywords, and you will see the image you are searching for. But how about the video? How can we retrieve a video by just describing it via text? This is the problem that text-to-video retrieval is trying to solve.
Traditional video retrieval methods are mostly designed to work with short videos (e.g., 5-15 seconds), and this limitation usually falls short when retrieving complex actions.
Imagine a video about making burgers from scratch. This can take an hour or even more. First, prepare the dough for the bread, let it rest, grind the meat, prepare the burger paddies, prepare the buns, bake them, grill the paddies, assemble the burger, etc. If you want to extract step-by-step instructions from the very same video, it would be helpful to retrieve a relevant couple of minutes of long video segments for each step. However, this cannot be done by traditional video retrieval methods as they fail to analyze long video content.

So we know we need a better video retrieval system if we want to eliminate the limitation of short video length. One can adapt the traditional methods for longer videos by increasing the number of input frames. Still, it would be impractical due to high computational costs as processing dense frames would be extremely time and resource-consuming.
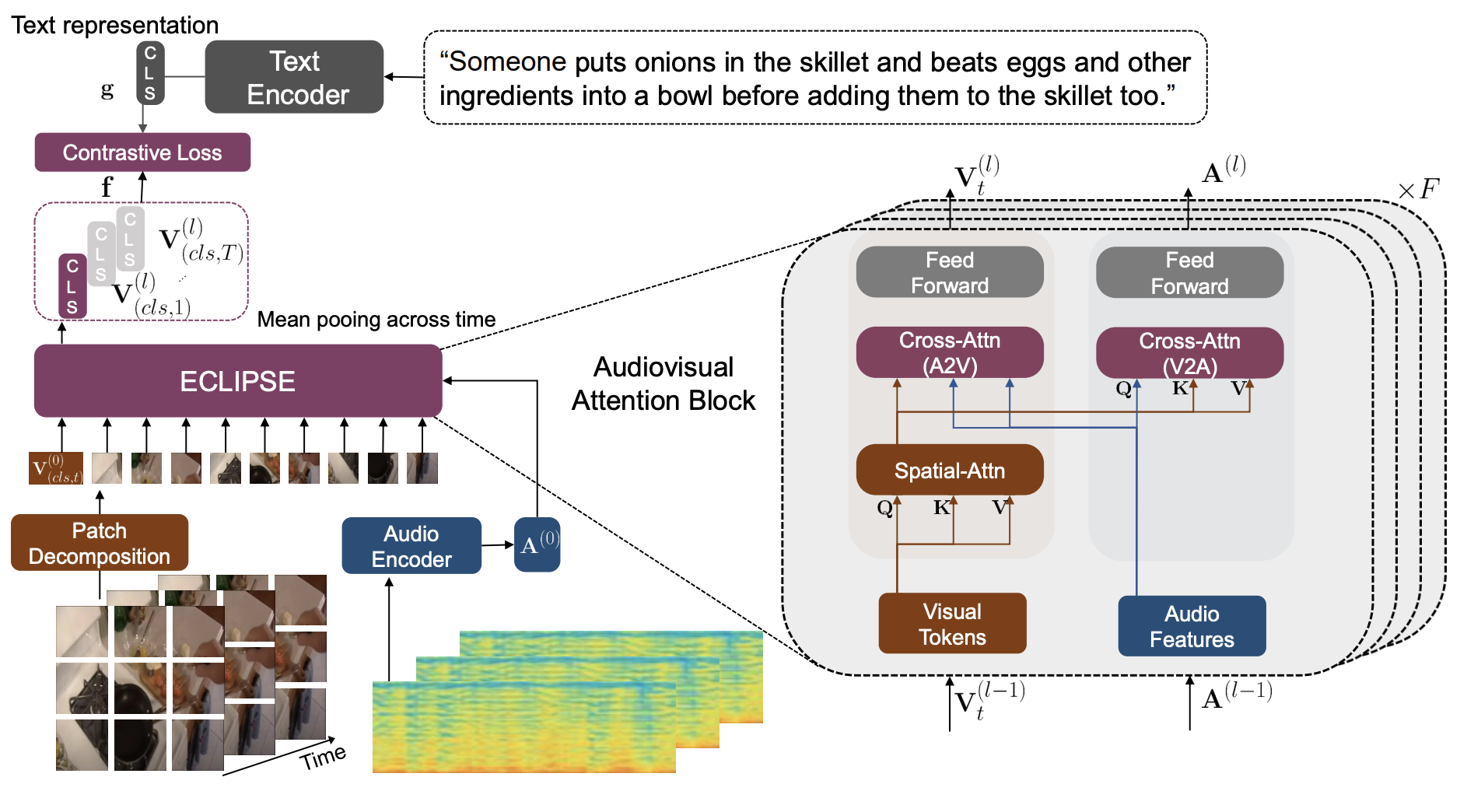
This is where ECLIPSE comes into play. Instead of purely relying on video frames which are expensive to process, it uses rich auditory cues and sparsely sampled video frames, which are easier to process. ECLIPSE is not only more effective than conventional video-only techniques, but it also delivers greater text-to-video retrieval accuracy.
While the video modality has a lot of information to store, it also has a lot of information redundancy, meaning that the video material frequently doesn’t vary much between frames. In comparison, audio can more efficiently record details about people, things, settings, and other complicated occurrences. It is also less expensive to produce than raw film.
If we go back to our burger example, the visual clues, such as dough, burger buns, and paddies, can be captured in several frames, and they will stay the same for the majority of the video. The audio, however, can indicate better clues, such as the sound of grilling the paddies, etc.
ECLIPSE uses CLIP, a state-of-the-art vision-and-language method, as the backbone of the method. ECLIPSE uses a dual pathway audiovisual attention block in every tier of the transformer backbone to adapt CLIP to long-distance videos. Thanks to this cross-modal attention mechanism, long-range temporal cues from the audio stream can be included in the visual representation. Conversely, rich visual characteristics from the video modality can be injected into the audio representation to increase the expressivity of audio features.
This was a brief summary of the ECLIPSE paper. ECLIPSE replaces the costly visual clues of video with cheap-to-process audio clues and achieves better performance than video-only methods. It is flexible, fast, memory-efficient, and achieves state-of-the-art performance in video retrieval tasks. You can find relative links below if you want to learn more about ECLIPSE.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'ECLIPSE: Efficient Long-range Video Retrieval using Sight and Sound'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.