Latest Computer Vision Research Proposes A Novel Plug-And-Play Module For Vision Transformer Architectures That Augments Its Ability To Handle Higher Resolution Input Images With insignificant Computational Cost
Herbarium sheets offer a singular perspective on the botanical world’s diversity and history. They are, therefore, a crucial source of information for botanical study. With the increased digitization of herbaria worldwide and the advances in fine-grained classification, the automatic identification of herbarium specimens became easier. Indeed, computer vision methods have been widely studied to realize this task.
Several recent works have focused on classifying plants from herbarium sheets. Most early-stage approaches followed two steps, feature extraction, and classification. In fact, the descriptors are used to extract information such as the length and width of sepals and petals. However, the most recent methods have exploited deep learning networks thanks to the appearance of new large-scale databases. Among these methods, convolutional neural networks (CNN) and vision transformers (ViT) are the most widely used techniques, although the latter has been more successful recently. Unfortunately, this technique becomes very resource intensive when the size of the images is large, which is the case with the images used in the classification task studied in this article. To handle higher dimensional images, a french research team presented, Conviformer, a new method to perform the fine-grained categorization of plants from herbarium sheets using vision transformers.
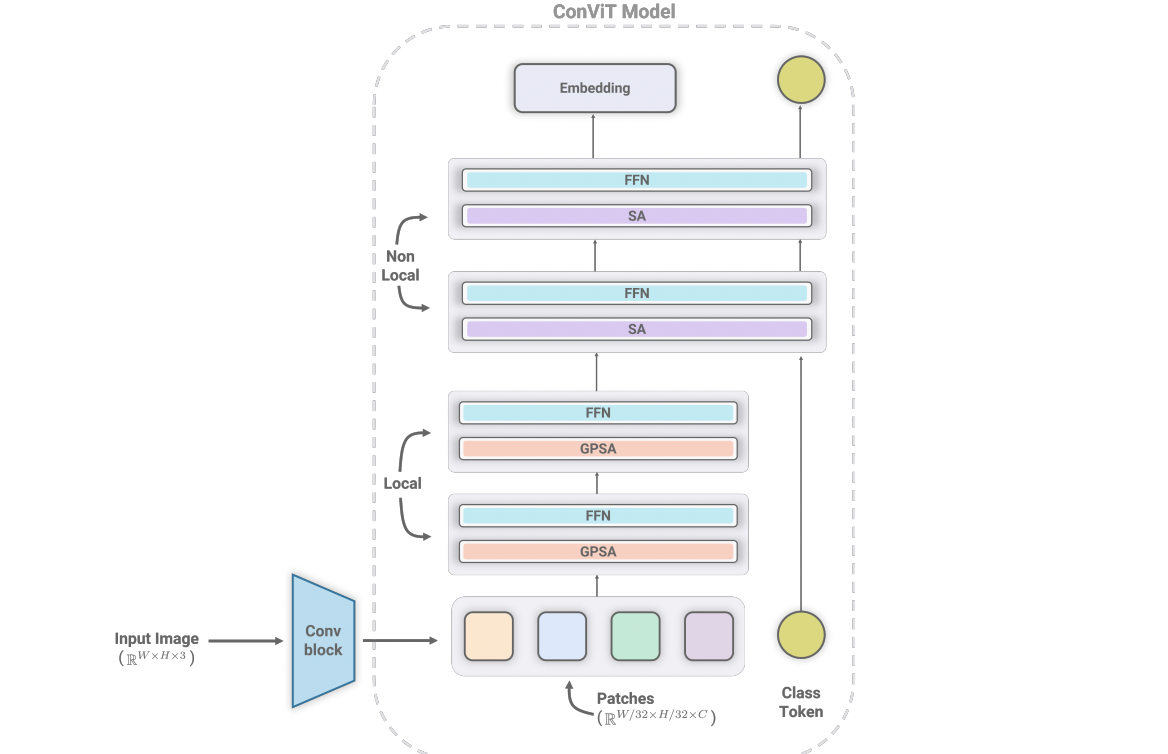
The suggested Conviformer is a new convolutional transformer architecture that can handle images of higher resolution without drastically increasing memory and computing costs. It is based on ConViT, which tries to maximize the potential of both transformers and convolutions. ConVit is formed by a soft convolutional inductive bias, gated positional self-attention layers (GPSA), self-attention layers, and Feed-Forwards network layers. The authors propose to add a convolutional block on top of the ConViT network to make it suitable for images with larger dimensions. The novel convolutional block downscales the input image (x) of size h×w×3 and then converts it to h′×w′×64. The obtained feature map is then fed to the ConVit network. Following this strategy, the new architecture can work with high-resolution images without increasing the number of patches provided to ConViT.
In addition, this article presents a new preprocessing technique, PreSizer, introduced specially to solve a problem related to the Herbarium 2022 dataset, which contains images with different resolutions where the longest side is always 1000 pixels, making the use of such images computationally expensive. The proposed PreSizer keeps the aspect ratio of the images in the dataset while making their resolution symmetrical. First, to make all images the same size, reflection is applied. First, to make all images the same size, reflection is applied. The edges of the images are smoothed to avoid discontinuity by removing artifacts. The distinct labels in this dataset are encoded using the Scikit-Learn preprocessing module.
An experimental study has shown that using a better resolution results in better performance. The results show that going from a 224-dimensional image to 448, a gain of 8.7% in accuracy is observed for the iNaturalist 2019 dataset. Moreover, a comparison with three other state-of-the-art architectures proved that Conviformer gives the best result according to F1 score for the dataset Herbarium 2021. Regarding the Herbarium 2022 database, an ablation study confirmed the usefulness of using the PreSizer preprocessing technique.
This paper put forward a method helpful for fine-grained classification challenges of plants from herbarium sheets. The suggested solution considered the input image’s resolution and aspect ratio. PreSizer a preprocessing technique, is proposed to resize the dataset without changing its aspect ratio. In addition, the authors proposed Conviformer, which aims to make the use of higher dimensional images with transformer-based architectures possible. The novel architecture is a plug-and-play convolutional module suitable for any transformer-based architecture.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'CONVIFORMERS: CONVOLUTIONALLY GUIDED VISION TRANSFORMER'. All Credit For This Research Goes To Researchers on This Project. Check out the paper. Please Don't Forget To Join Our ML Subreddit
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.