Latest Computer Vision Research Proposes ‘NeRFPlayer,’ A Streamable Dynamic Scene Representation with Decomposed Neural Radiance Fields

Using Neural Radiance Fields (NeRF) to represent scenes has made strides in 3D reconstruction and analysis. After a brief training period, high-fidelity real-time depiction of real-world locations is possible. The rendering engine can accurately model situations as small as a cell and as large as a metropolis or even a black hole using just a few real-world RGB photos. NeRF has succeeded in static scenarios, but expanding it to handle dynamic scenes is still challenging. NeRF’s 5D representation, which consists of 3D location x, y, and z and 2D viewing direction, is non-trivial because of the following two factors. First, the supervisory signal for a spatiotemporal point (x, y, z, t) is sparser compared to a fixed point.
Moving the camera around makes accessing several views of static scenes simple. Still, additional views of dynamic scenarios necessitate using a second recording camera, resulting in a supply of input perspectives. Second, the scene’s appearance and geometry frequently vary throughout its spatial and temporal axes. An incorrect frequency modeling causes poor temporal interpolation performance for the time t dimension. When traveling from one area to another, the content typically changes significantly, but the background scene is rare to shift entirely from one timestamp to another. To address the two difficulties above, significant progress has been made.
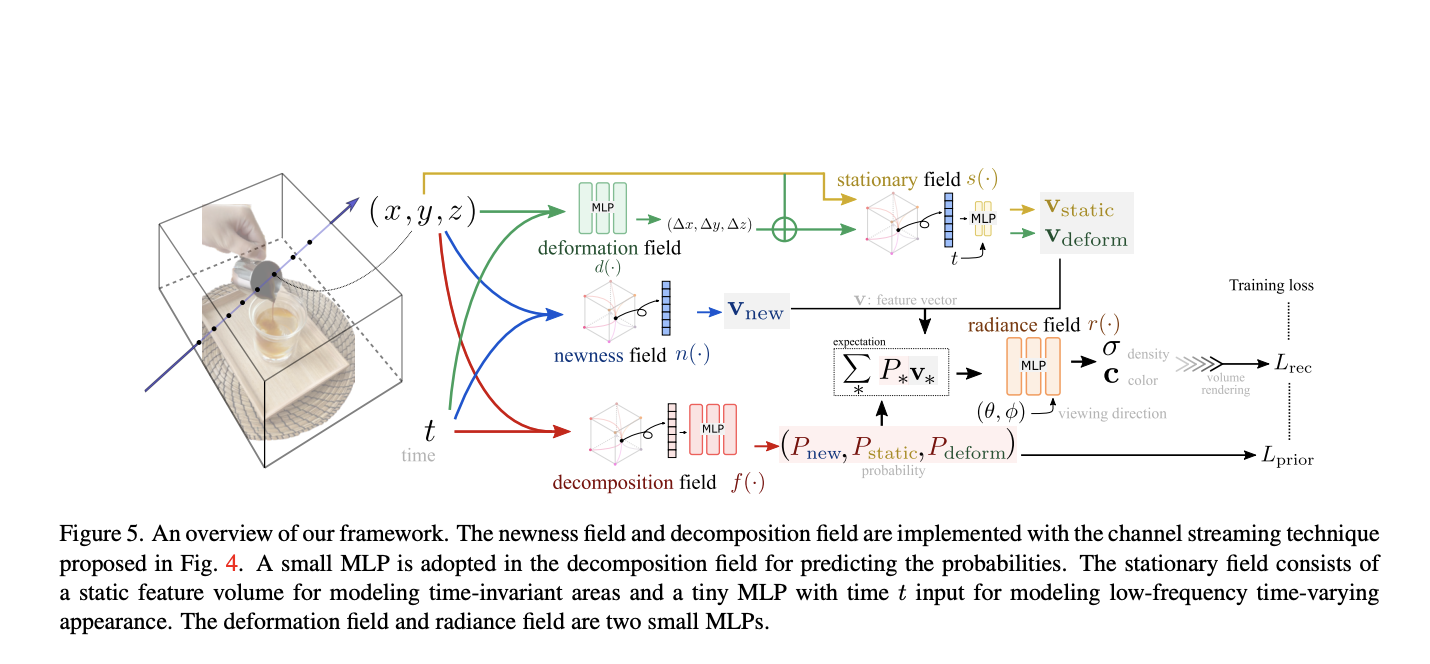
They assume three kinds of temporal patterns in an emotional location, as shown in the figure below: static, deforming, and new areas. Unlike existing works, they are motivated by the observation that other spatial areas have different temporal characteristics in dynamic scenes. They thus propose to decompose the dynamic scene into these categories, which is achieved by a decomposition field that predicts the point-wise probabilities of being static, deforming, and new. Existing solutions include adopting motion models for matching the points and leveraging data-driven priors like depth and optical flow.

The suggested breakdown can solve both of the difficulties mentioned above. Using a manually chosen global parsimony regularisation, the decomposition field is self-supervised and regularised (e.g., suppressing the global probabilities of being new). Several temporal regularizations are first incorporated for each decomposed area, removing any uncertainty in reconstruction from sparse observations. For instance, the dynamic modeling problem is made simpler by the static area reduction to a static scene modeling problem. Due to the deforming zones, the foreground item must be consistent in the dynamic scene. Second, the scene is divided into various regions based on its temporal properties, resulting in a frequency in the time dimension constant throughout all regions.

Deforming, new, and static areas are the three divisions into which they divide the locations in a dynamic scene. Visualization of the self-supervised decomposition produced by their framework in the second row. Estimated high and low probabilities of a category are shown in red and blue areas, respectively.
They further dissociate spatial and temporal dimensions based on the recently created hybrid representations in response to spatial and temporal frequency differences. Hybrid representations maintain a grid of (x, y, z) feature volumes for quick rendering. They treat the channels of (x, y, z) feature volumes as temporally dependent rather than building a grid of (x, y, z, t) feature volumes. They suggest a sliding window method on the feature channels to incorporate t into the representation to provide streamable dynamic scene representation.
By utilizing the overlapped channels in adjacent frames, sliding windows implicitly promote the representation to be condensed while simultaneously supporting the streaming of the feature volumes. Their thorough ablation investigations support their suggested approach in three ways: they ran tests on datasets taken in single-camera and multi-camera configurations for validation.
- Modeling all three areas on datasets from a single camera.
- Decomposing static areas on datasets from multiple cameras.
- Deforming decomposition on inputs with significant frame-wise motion even for datasets from multiple cameras.
In summary, the following is what they have contributed:
- They suggest breaking down the dynamic scene into various components based on its temporal properties. A decomposition field that accepts all (x, y, z, and t) points as inputs and produces probabilities falling into three categories: static, deforming, and new, achieves the decomposition.
- Using a global parsimony loss, they create a self-supervised technique for regularising and maximizing the decomposition field.
- For effectively simulating spatiotemporal fields, they offer a sliding window approach based on recently created hybrid representations.
- On datasets from single-camera and multiple-camera systems, they describe in-depth investigations and real-time rendering demonstrations. Their ablation studies support the inferred regularizations underlying the three temporal patterns presented.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'NeRFPlayer: A Streamable Dynamic Scene Representation with Decomposed Neural Radiance Fields'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and project page.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.