Latest Computer Vision Research Proposes SLaK (Sparse Large Kernel Network), a Pure Convolutional Neural Network (CNN) Architecture based on Dynamic Sparsity Equipped with an Unprecedented Kernel Size of 51×51

Since their introduction in the ImageNet competition with AlexNet, Convolutional Neural Networks (CNNs) have always been the most used architecture in vision. However, in the past few years, Transformers, formerly introduced for NLP, has started to challenge the performance of CNN in many tasks. Starting from Vision Transformer (ViT), many subsequent implementations, such as Swin-Transformer, have demonstrated strong performances in classification, segmentation, and object detection, to name a few. Among the many hypotheses on their apparent superpowers, one of the most accredited theories is their ability to capture a larger receptive field compared to CNNs. Indeed, CNNs usually rely on a small sliding window (e.g., 3×3 and 5×5) with local attention.
Inspired by this idea, some recent works such as ConvNeXt and RepLKNet tried to enlarge the receptive field of CNNs, managing to enlarge the kernel size to 31×31 and obtaining comparable results with the best transformer-based architectures. However, large kernels are difficult to train, and the performance of these networks starts to saturate when the kernel surpasses the size of 31×31.
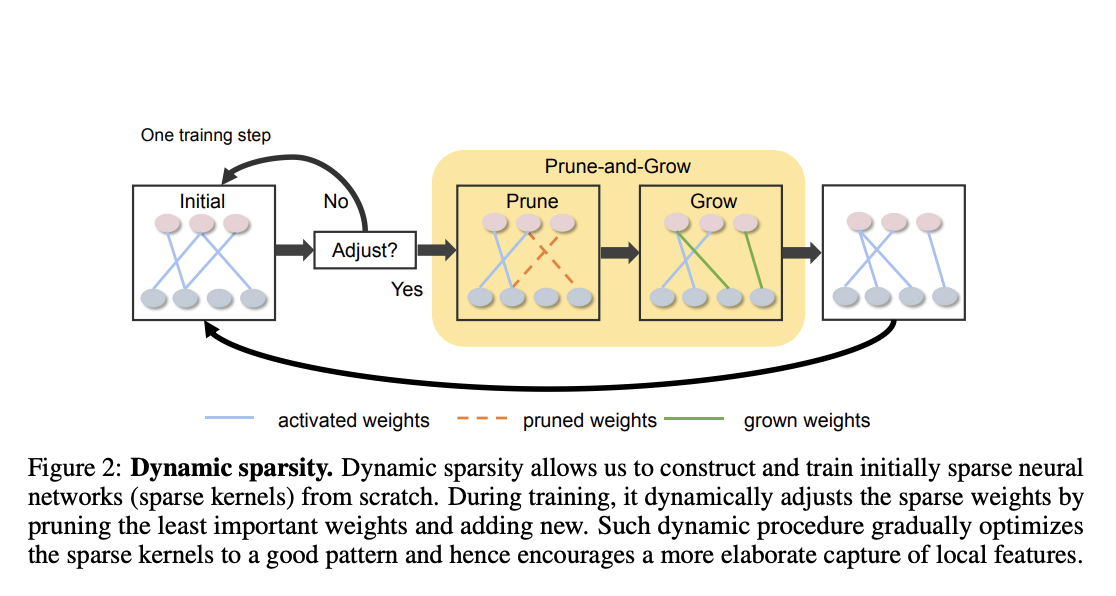
Trying to overcome this limit, a research group from Eindhoven University and the University of Texas proposed SLaK (Sparse Large Kernel Network), a pure CNN architecture based on dynamic sparsity equipped with an unprecedented kernel size of 51×51. Dynamic sparsity is a recently developed study area that aims to train intrinsically sparse neural networks from scratch utilizing a minimal amount of parameters and FLOPs. It dynamically modifies the sparse weights during training by removing the least significant weights and adding new ones. Such a dynamic process supports a more intricate capture of local features by gradually optimizing the sparse kernels to a desirable pattern (figure below).

Observations
First of all, the authors conducted a study on the performances of a recently developed CNN, ConvNeXt, when the kernel size surpasses 31×31, to obtain a recipe for working with large kernels. The first thing they noticed is that the existing architectures are unable to scale convolution beyond 31×31, as, after this size, the performance starts to decrease. But, afterward, they also demonstrated that decomposing a square large kernel into two rectangular, parallel kernels, can scale the size up to 61×61. For example, an MxM kernel can be substituted by two parallel MxN and NxM kernels. In addition, following the idea from RepLKNet, the authors kept a 5×5 layer parallel to the large kernels and summed up their outputs. Finally, they showed how training using dynamic sparsity, where the sparse weights are dynamically adjusted during training by removing the weights with the lowest magnitude and randomly increasing the remaining weights, leads to superior local features. The basic block, compared to the one from ConvNeXt and RepLKNet, is shown in the figure below.
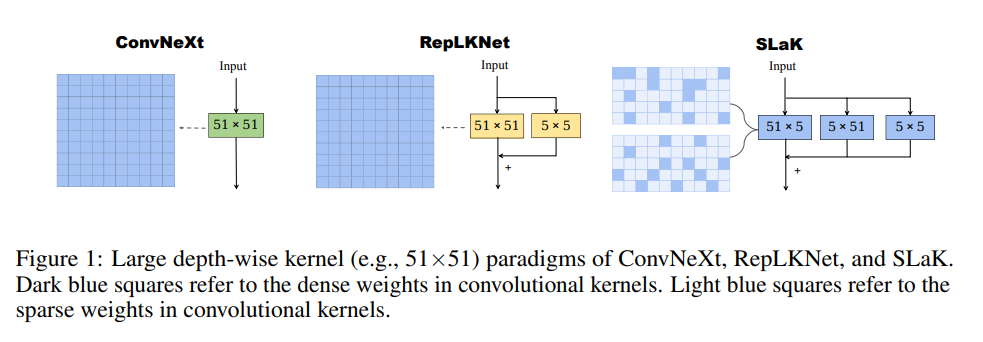
Given this basic block derived from the previous three observations, SLaK is built based on the architecture of ConvNeXt. This means that the number of blocks in each stage is [3, 3, 9, 3] for SLaK-T and [3, 3, 27, 3] for SLaK-S/B, replacing each M×M kernel with a combination of M×5 and 5×M.
Results
SLaK has been tested for classification, segmentation, and object detection with ImageNet-1K, ADE20K and PASCAL VOC 2007, respectively. In all the vision tasks, with similar model sizes and FLOPs, SLaK outperforms the existing convolutional models and achieves an appealing higher accuracy than the state-of-the-art transformers.Finally, they also visualized the Effective Receptive Field (ERF), which shows the area of effectiveness in the input image, of SLaK, and compared it with the ones from ConvNeXt and RepLKNet. The results showing the larger ERF of SLaK can be seen in the figure below.

This Article is written as a research summary article by Marktechpost Staff based on the research preprint-paper 'MORE CONVNETS IN THE 2020S: SCALING UP KERNELS BEYOND 51 × 51 USING SPARSITY'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Leonardo Tanzi is currently a Ph.D. Student at the Polytechnic University of Turin, Italy. His current research focuses on human-machine methodologies for smart support during complex interventions in the medical domain, using Deep Learning and Augmented Reality for 3D assistance.
Credit: Source link
Comments are closed.