Latest Machine Learning Research at Amazon Proposes DAEMON, a Novel Graph Neural Network based Framework for Related Product Recommendation
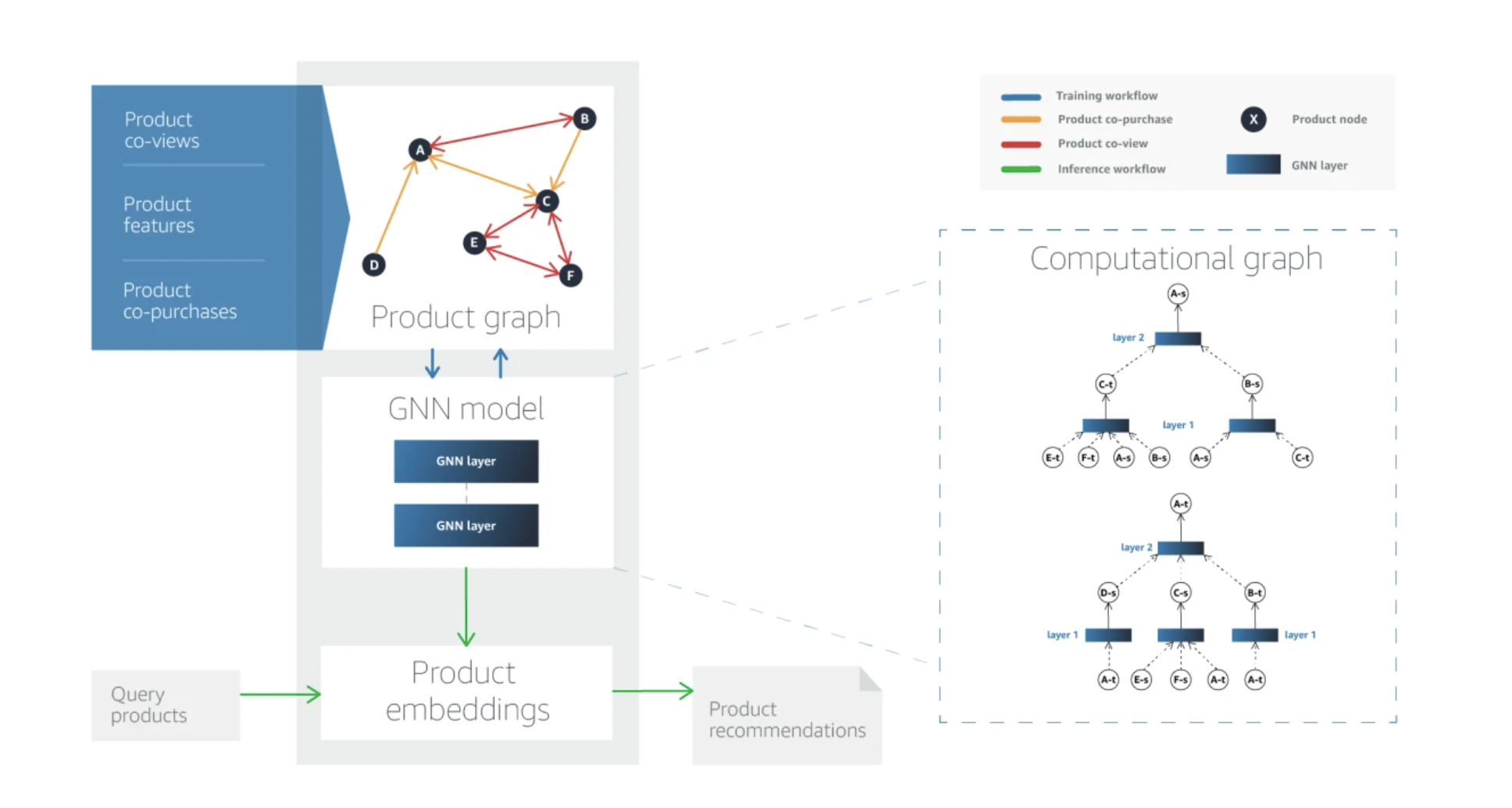
One primary machine learning application today is recommendation systems for e-commerce stores like Amazon. Customers can save time and have more fulfilling buying experiences when businesses can suggest related products depending on their purchase, for example, a phone case to match a customer’s recently purchased phone. Recently, some Amazon researchers created a novel method for suggesting related products utilizing directed graphs and graph neural networks. The team started deploying this model in production after the study was presented at this year’s European Conference on Machine Learning (ECML). On comparing model predictions to real customer co-purchases using two performance metrics, HitRate and mean reciprocal rank, the team showed that their method surpassed state-of-the-art baselines by 30% to 160%.
The fundamental difficulty with employing graph neural networks (GNNs) for related-product recommendation is that there exist asymmetric relationships between the items. In the actual world, it makes more sense to suggest a phone case to someone purchasing a new phone than it does to suggest a phone to someone purchasing a case. A directed edge in a graph can be used to depict this kind of relation. However, it is difficult for vector representations created by GNNs to reflect this directedness fully.
The team tackled this issue by creating two embeddings for each network node: one that describes its function as the target of a related-product suggestion and one that describes its function as the producer of a related-product recommendation. In addition, they introduce a brand-new loss function that motivates related-product recommendation (RPR) models to choose items along outbound graph edges and dissuades them from recommending products along inbound edges. The GNN addresses the cold start issue, or how to account for products that have just been added to the catalog, as it accepts product metadata and the graph structure as inputs. Last but not least, the researchers provided a data augmentation technique that aids in overcoming the issue of selection bias, which results from differences in how data is presented.
Elaborating more on the graph construction, the researchers clarified that in their product graph, the nodes stand in for individual products, and the node data is made up of information about those products, such as name, type, and description. The graph’s directional edges were added using co-purchase data or information regarding which products are frequently bought together. These edges could be unidirectional, as in the case of two products being accessories for one another, or bidirectional, as in the case of two products being co-purchased, but neither is dependent on the other.

However, this strategy raises the possibility of modeling selection bias. When clients choose one product over another because they have had more exposure to it, selection bias arises. This network also has bidirectional edges that come from co-view data or information on which products are frequently viewed jointly under a single product query to reduce that risk. Thus, the product graph has two different sorts of edges: edges signifying similarity and edges signifying co-purchases. In essence, the co-view data aids in the identification of products that are comparable to one another.
Creating separate source and target embeddings is the model’s fundamental component. The GNN creates an embedding for each node in the product graph that includes details about that node’s immediate surroundings. It has utilized two-hop embeddings, which take into account data on both a node’s close neighbors and the neighbors of those neighbors. A node’s similarity relationships are taken into account by the source embedding, not just its outbound co-purchase linkages, whereas the target embedding only considers the inbound co-purchase associations. The GNN has multiple layers, and each layer outputs new node representations after consuming the node representations created by the layer below. The source and target embeddings are identical at the first layer because the representations are only the product metadata. However, the source and target embeddings start to diverge at the second layer. Each node’s target embedding considers both the target embeddings of similar nodes and the source embeddings of the nodes with which it has inbound co-purchase relationships.
The researchers trained the GNN in a self-supervised manner using contrastive learning, which pushes apart the embedding of a given node and a randomly chosen, unconnected node while pulling the embedding of a given node and those that share edges with it apart. A term of the loss function further enforces the source and target embeddings’ asymmetry. After the GNN has been trained, the k nodes in the embedding space closest to the source node are found to choose the k best-related goods to propose. The researchers used hit rate and mean reciprocal rank for the top 5, 10, and 20 suggestions on two separate datasets for 12 tests to compare their approach to its two best-performing predecessors. The team concluded that their approach consistently surpassed the benchmarks, frequently by a wide margin.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Recommending Related Products Using Graph Neural Networks in Directed Graphs'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.