Latest Machine Learning Research at UC Berkeley Proposes a Way to Design a Learned Optimizer Using Generative Models of Neural Network Checkpoints
Deep learning methods have been a game-changer in lots of applications. They have been the core components of field advancements in the last decades, from computer vision to language processing.
Training a deep neural network on a specific task requires constructing a dataset with many samples. DNN model can then go over the training data to gradually optimize its neurons’ weights to achieve the minimal loss based on the predefined loss function.
This training process is named gradient-based optimization. It is the clavis aurea of deep learning. Gradient-based optimization methods such as stochastic gradient descent (SGD) or Adam are straightforward to implement, and they usually achieve impressive results in high-dimensional non-convex loss spaces of neural networks.
Although they achieved significant advancements in deep neural networks, these manual optimization methods have a crucial limitation. They cannot improve on previous experience. They cannot learn how to optimize the network and will always start from the same point.
Imagine you train the same network with the same parameters using the same initialization strategy, and let’s say we use Adam as the optimizer. Also, we decided to train the network 100 times. There will not be any difference in terms of optimization steps between the first time and the 100th time. Adam will always follow the same optimization pattern, and it will not converge any quicker.
An optimizer learning to optimize can leverage its previous experiences to overcome this barrier and accelerate future development in deep learning. This is the scope of this paper.
The concept of learning improved optimizer is not new. It dates back to the 1980s. However, it gained attention in recent years. These methods learn through layered meta-optimization, in which the inner loop optimizes the task-level goal, and the outer loop learns the optimizer. They can outperform manual optimizers in some instances. However, their dependency on unrolled optimization and reinforcement learning makes them challenging to train in reality.
Tackling the learning to learn problem via deep learning has a simple formula. Collect large data samples and let the network learn how to learn using these samples. But what would be the data to train a network on how to learn learning?
The answer is the checkpoints that were used during training deep neural networks in any other problem. There are millions of checkpoints available thanks to the massive number of trained networks for a variety of problems. They contain rich and diverse information. From a checkpoint used to train a robot how to move using a reinforcement learning approach to a checkpoint belonging to a computer vision model trained on classifying objects in the image, these checkpoints are gold mines of rich and diverse information.
This is how the training dataset is constructed in this paper. 23 million checkpoints from over 100,000 training runs are collected. These checkpoints are collected from diverse training runs, such as supervised learning tasks (e.g., CIFAR10 classification) and reinforcement learning tasks (e.g., Cartpole). Moreover, they contain checkpoints belonging to diverse neural networks (e.g., MLPs, CNNs, etc.). Finally, loss values and classification errors belonging to each checkpoint are also collected.
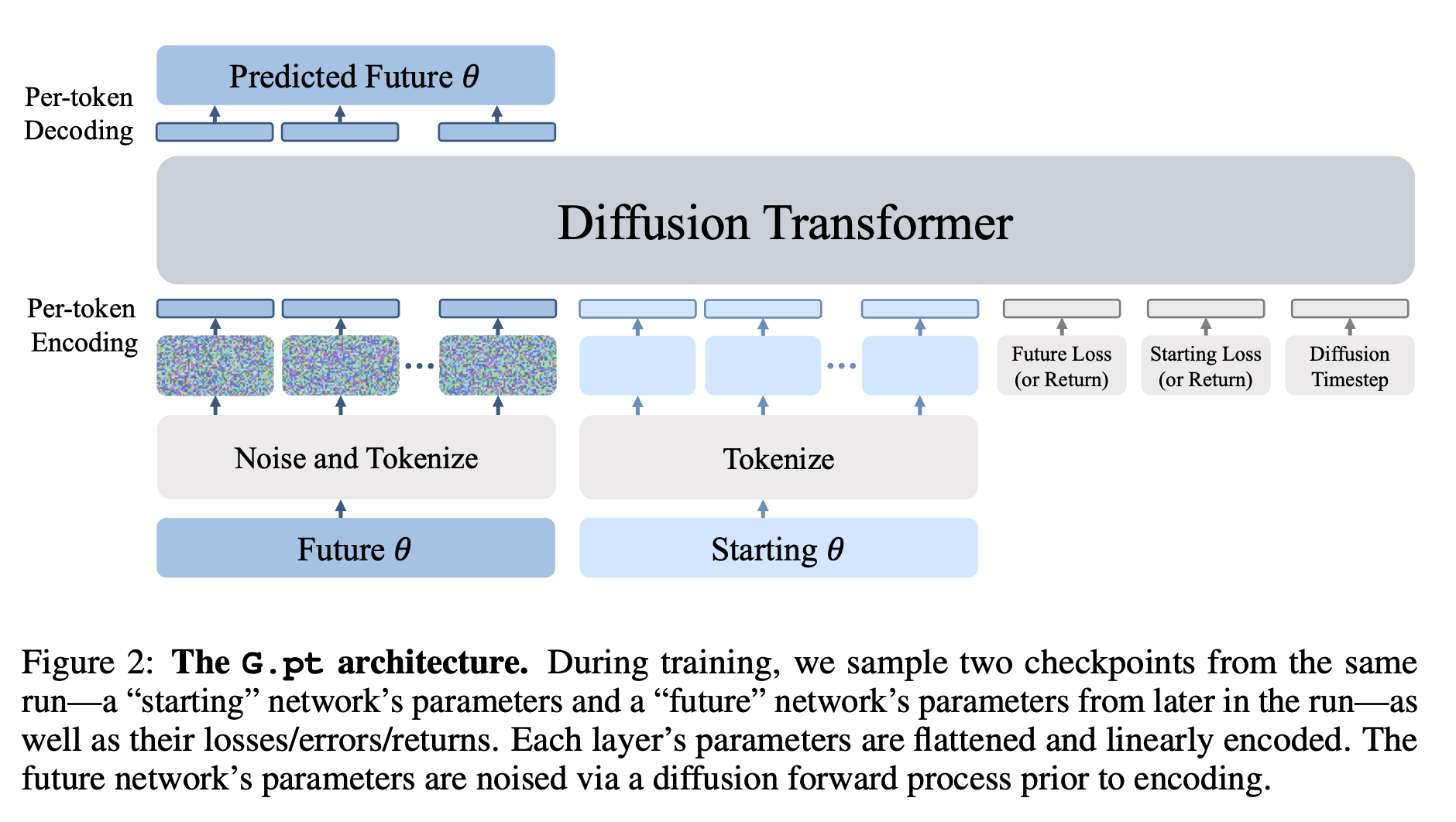
They have the dataset, but what kind of a neural network learns to learn? The answer is a generative model. A transformer-based diffusion model is trained in this study. These models are trained to predict the distribution of updated parameter vectors for a single network architecture that achieves the target metric given an initial input parameter vector and a target loss, error, or return.
The proposed approach, G.pt., has several extremely useful properties. First, it can swiftly train neural networks from previously unknown initializations with only one parameter update. Second, it can produce parameters that result in a wide range of prompted losses, errors, and returns. Third, it is capable of generalizing to out-of-distribution weight initialization algorithms. Fourth, as a generative model, it may sample diverse solutions. Finally, it can improve non-differentiable objectives like RL returns or classification errors.
This was a brief summary of the paper “Learning to Learn with Generative Models of Neural Network Checkpoints.” You can follow the links below if you want to learn more about it.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'LEARNING TO LEARN WITH GENERATIVE MODELS OF NEURAL NETWORK CHECKPOINTS'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and code.
Please Don't Forget To Join Our ML Subreddit
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.