Latest Machine Learning Research From CMU Introduces ‘DASH,’ a Differentiable NAS Algorithm that Computes the Mixture of Operations Using the Fourier Diagonalization of Convolution, Achieving an up-to-10x Search Time Speedup in Practice
The ground-breaking research conducted in the last ten years is mainly responsible for the remarkable achievements gained in machine learning. Machine learning applications are now necessary to address a wide range of real-world issues, including facial recognition, fraudulent transactions, machine translation, and illness detection and protein sequence prediction in the medical profession. However, advancement in these fields has required arduous manual labor in task-specific neural network design and training, which utilizes a considerable amount of human and computational resources that most practitioners do not have access to. Contrary to this task-specific approach, general-purpose models, such DeepMind’s Perceiver IO, Gato, and Google’s Pathway, have been designed to solve multiple tasks simultaneously. Practitioners, however, cannot even determine whether fine-tuning one of these models would be effective on their target task because these private pretrained models are not publicly accessible. Moreover, a general-purpose model cannot be independently created from scratch because of the enormous computing power and training data needed.
The domain of automated machine learning (AutoML), which strives to produce high-quality models for various tasks with the least amount of human labor and computer resources, offers a more approachable option. To automate the neural network designs for various learning tasks, Neural Architecture Search (NAS) can be employed. Although NAS has made it possible for AutoML to be used in several well-researched domains, its use for applications outside of computer vision is still not well understood. Working towards this front, a team of academics from Carnegie Mellon University aimed to design a method to strike a good balance between expressivity and efficiency in NAS, as AutoML is thought to have the most significant impact in less-studied domains.
The team introduced DASH, a NAS technique that uses task-specific convolutional neural networks (CNNs) to achieve excellent prediction accuracy. The efficiency of convolutions as feature extractors is well known, and recent work demonstrates the efficacy of contemporary CNNs on various tasks. Using this, the team worked on extending the generalization capabilities of CNNs, like the state-of-the-art performance of the ConvNeXt model that incorporates many techniques used by Transformers. The central premise of their research is that optimizing a basic CNN topology with the correct kernel sizes and dilation rates can produce models that are competitive with those created by experts.
Most NAS approaches for creating task-specific models have two main components, a search space that defines all possible networks and a search algorithm that peruses the search space until a final model is produced. If and only if the search space for the job is expressive enough, a model will prove effective. It is therefore assumed that there is enough time to investigate all the potential architectural configurations in the space. In NAS research, this conflict between the search space’s expressivity and the search algorithms’ effectiveness has been prominent. Existing methods either take into account very expressive search spaces with insurmountable search algorithms or are meant to examine a variety of architectures in small search spaces swiftly.
DASH fills this gap by using CNN as the foundation and looks for the best kernel configurations. The assumption is that attention-based architectures can compete with contemporary convolutional models like ConvNeXt and Conv-Mixer, and that varied kernel sizes and dilations can further enhance the feature extraction process for various tasks. For example, small kernels are frequently more efficient for modeling long-range dependencies in sequence tasks than large filters are for visual tasks that typically require small filters to detect low-level characteristics like edges and corners.
The researchers had to consider many kernels with various kernel sizes and dilation rates, which led to a combinatorial explosion of potential configurations, which was one of their biggest hurdles. To tackle this issue, they presented three methods that take advantage of fast matrix multiplication on GPUs and the mathematical features of convolution. DASH was tested on ten distinct tasks, including input dimensions (1D and 2D), prediction types (point and dense), and several domains, including music, genomics, ECG, vision, and audio.
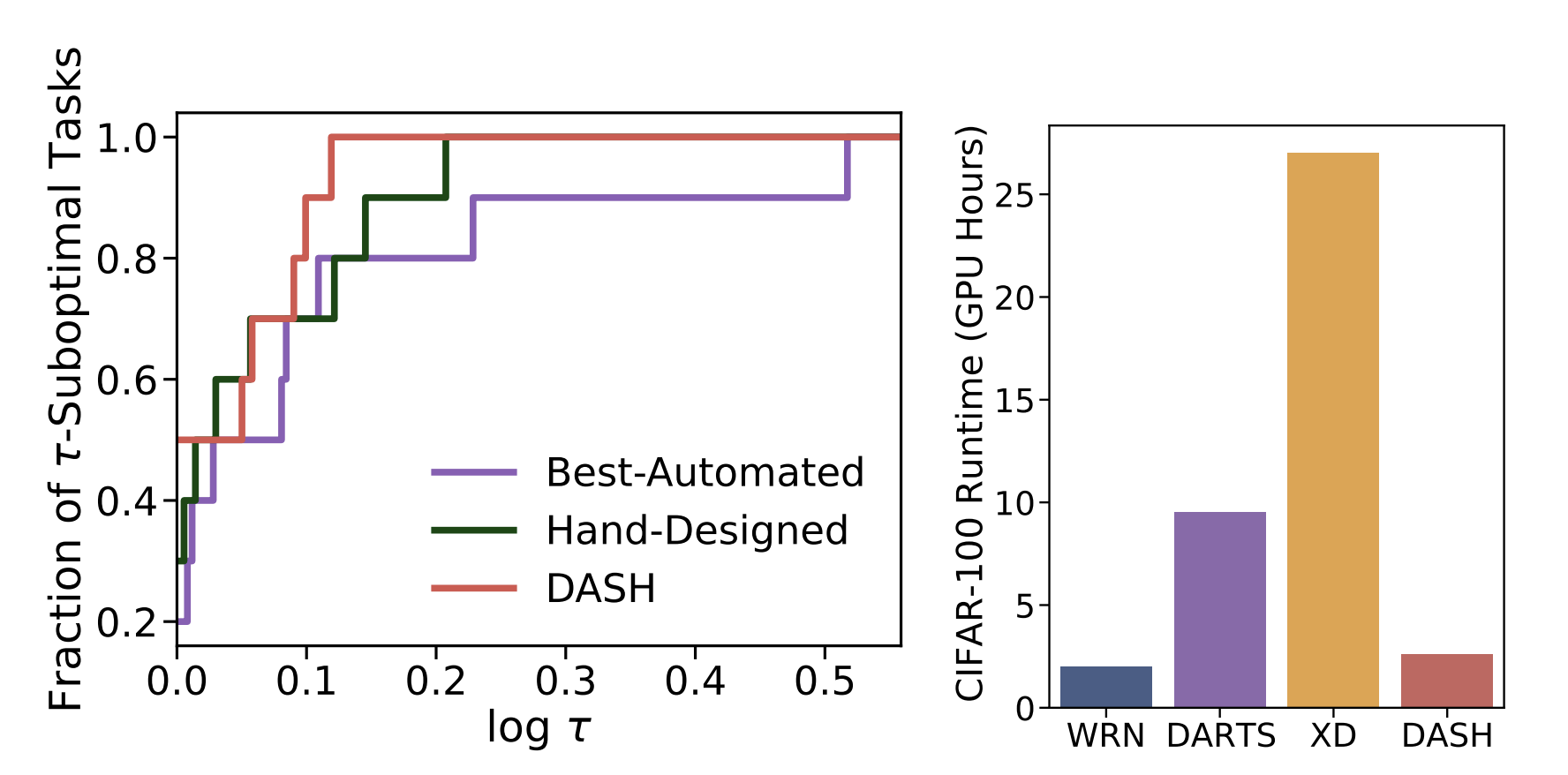
The researchers conducted many experimental tests to validate that DASH strikes a balance between expressivity and efficiency. With the Wide ResNet backbone, its performance was assessed on ten different NAS-Bench-360 workloads. Among other noteworthy findings, DASH surpasses DARTS on 7 out of 10 tasks, ranks first among all NAS baselines, and searches up to 10 times faster than existing NAS techniques. Additionally, it outperforms classic non-DL methods like Auto-Sklearn and all-purpose models like Perceiver IO.
On 7 out of 10 tests, DASH outperforms manually created expert models. The sophistication of expert networks varies from task to task, but DASH’s performance on tasks like Darcy Flow demonstrates that it can hold its own against highly specialized networks. This suggests that a promising strategy for developing models in new areas is to outfit backbone networks with task-specific kernels. DASH consistently outperforms DARTS in terms of speed, and its search procedure is frequently only a fraction of the time required to train the backbone. In conclusion, DASH is faster and more productive than most NAS techniques.
CMU created DASH with the vision to extend AutoML to find effective models for resolving various real-world issues. DASH finds a balance between expressivity and efficiency in NAS, which helps it produce high-quality models. However, the researchers think this is still only the first step in the enormous challenge of AutoML for various jobs. The group is anticipating the contributions of other researchers as they work to create more automated and valuable approaches for handling various jobs in the future.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Efficient Architecture Search for Diverse Tasks'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link.
Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.