Latest Machine Learning Research from Microsoft Exhibit a Neural Network Architecture that, in Polynomial Time, Learns as well as any Efficient Learning Algorithm Describable by a Constant-Sized Learning Algorithm
In 1947, the genius mathematician and computer scientist Alan Turing anticipated the current state of machine learning research by stating that a machine should be able to learn from experience in the future, like a student who had gained a great deal from his teacher but had also significantly contributed on his own. Over time, neural networks (NNs) have shown tremendous learning capacity. However, the question of whether neural networks can be further developed to the point where they can surpass learning algorithms created by humans still has to be answered. Even though there are straightforward learning techniques for some problems, including parity difficulties, neural networks still have difficulty learning them well. It is crucial to respond to whether or not NNs can find learning algorithms on their own.
Recently, a research team from Harvard University and Microsoft showed for the first time that neural networks could autonomously discover concise learning algorithms in polynomial time. The group suggested an architecture that reduces parameter size from even trillions of nodes down to a constant by combining recurrent weight-sharing between layers with convolutional weight-sharing. Additionally, their research raises the possibility that RCNNs’ synergy may be more effective than either technique. The work has also been published in a research paper titled ‘Recurrent Convolutional Neural Networks Learn Succinct Learning Algorithms.’
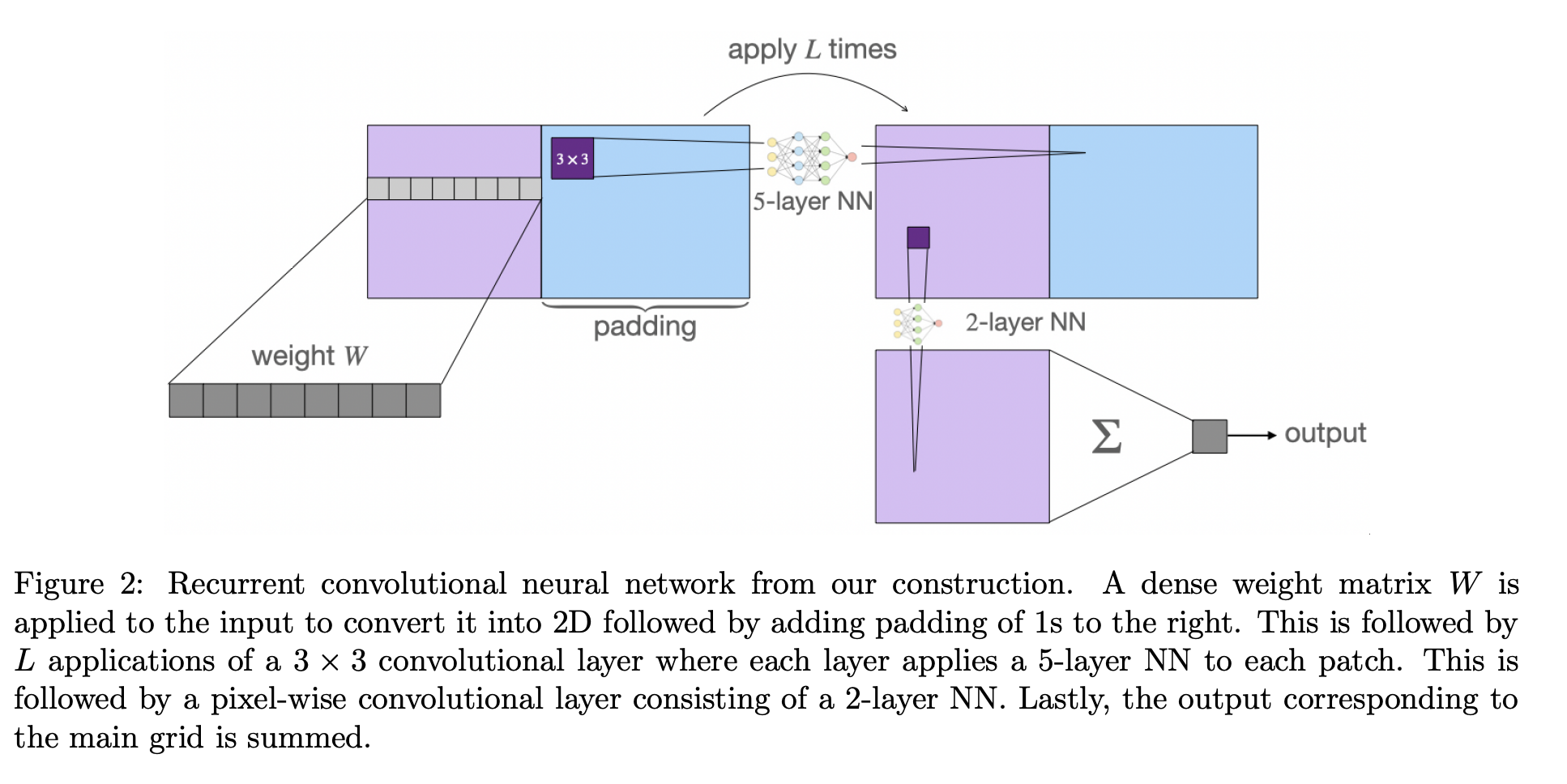
The neural network architecture that the team has presented consists of a dense first layer with a size linear in m, which refers to the number of samples) and d referring to the dimension of the input. The output of this layer is fed into an RCNN with convolutional weight-sharing across the width and recurrent weight-sharing across the depth, and the final outputs of the RCNN are then sent through a pixel-wise neural network added to obtain a scalar prediction. This simple recurrent convolutional architecture (RCNN) combines recurrent weight-sharing across layers and convolutional weight-sharing within each layer. This reduces the number of weights in the convolutional filter to a constant while maintaining the weight functions to determine activations for a broad and deep network, representing the team’s primary contribution.
In a nutshell, the study shows that any bounded learning algorithm and straightforward neural network topology can successfully reach Turing optimality, which is the state in which learning is optimal. According to the researchers, the best step is to use stochastic gradient descent (SGD) beyond memorization and reduce the size of the dense parameters to depend on the algorithm’s memory use rather than the training sample size. By doing this, they believe the architecture might become more apparent and organic. To better understand which architectures, initializations, and learning rates are Turing-optimal, the team intends to investigate further combinations in the future.

This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Recurrent Convolutional Neural Networks Learn Succinct Learning Algorithms'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.