Latest Meta AI Research Shares New Research And Datasets Around Measuring Fairness And Mitigating Bias In NLP Training Data
There is growing evidence that models might manifest social biases because they tend to repeat or amplify undesirable statistical relationships in their training data, such as preconceptions. With larger data sets, the possibility of models duplicating or aggravating negative biases may increase. The problem is more severe for historically oppressed groups, such as people of color and women. For example, models learned the stereotype that “women enjoy shopping” when they were trained on data in which most shoppers are female. They learned that “men do not enjoy shopping” when they were taught on data in which few or no consumers are male. Even worse, models frequently ignore the existence of some groups, such as nonbinary individuals. This exclusion and erasure is an obvious wrong that must be rectified. Developing accurate, large-scale approaches to measure fairness and mitigate prejudice gives AI researchers and practitioners benchmarks to test NLP (natural language processing) systems, advancing the objective of ensuring AI systems treat everyone equitably.
Gender, race, and ethnicity are three areas where the scientific community has made tremendous progress. Although this foundation is an important starting step toward addressing fairness along these dimensions, it falls short of identifying issues of fairness based on other significant communities or identities, such as religion, socioeconomic background, and queer identities. New techniques and benchmarks are needed, for example, to identify a broader range of demographic biases in a number of technologies and to build AI systems that represent a wider range of personal identities.
Many datasets and models have been released for responsible NLP to fill this void. The Meta research presents an innovative way to test NLP models for a wide range of biases beyond only race, gender, and ethnicity. Models have been taught to use a simple technique to understand and avoid social biases while creating answers to particular demographic phrases. In addition, an AI model is developed that can help break stereotypes in NLP data by minimizing demographic biases in text. This technique, known as a demographic text perturber, adds demographically diverse modifications to the original text otherwise identical to it. Using the example of “He likes his grandma,” it may construct alternates like “She likes her grandma” and “They enjoy their grandma” to add demographically adjusted versions to the dataset.
Large-scale text resources train the most advanced NLP systems, which are notoriously data-heavy. Research on justice in AI should benefit from these datasets. AI systems may unintentionally duplicate or even exacerbate undesired social biases present in the data they use. NLP data, for example, can contain or fail to convey prejudices and stereotypes regarding specific demographic groups.
Developing and implementing methods to assess and correct unfairness
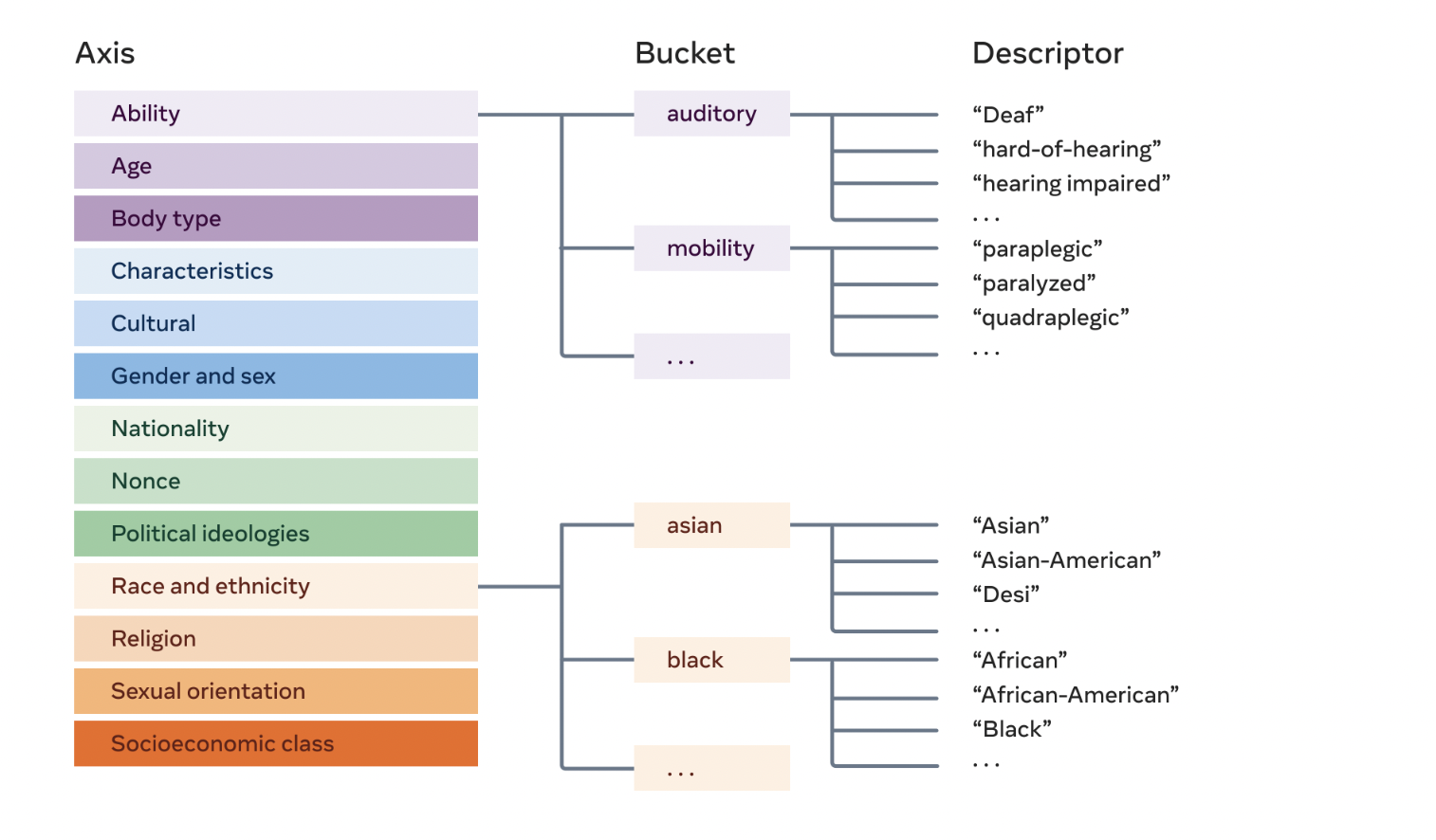
A rich vocabulary is needed that reflects a wide range of identities to identify demographic biases in AI correctly. More than 500 categories covering around a dozen demographic axes were developed using a combination of computational and participative procedures by us. More specifically, a set of sample phrases for each axis was created, and nearest neighbor algorithms were used to extend these terms automatically. As part of the participatory process, new term proposals were gathered and received input on existing terms from policy experts and domain experts, as well as people with lived experience relating to a wide range of identities (representing multiple ethnicities, religions, races, sexual orientations, genders, and disabilities).

Model biases can be effectively measured and mitigated using this comprehensive list of demographic terms. When it comes to measuring biases, the research has previously focused on broad terms such as “Asian,” which meant that if the models were prejudiced against Asian people, it wouldn’t be clear whether they were biased towards Japanese people. It’s easier to analyze the list because it’s generated with terms that groups of individuals use to identify themselves rather than just standard dictionary terms.
This problem was addressed by developing a simple method of controlling how models generate text and teaching models to understand and avoid social biases when causing replies to specific demographic phrases.

Many practical applications can benefit from data enriched by the models, such as evaluating the fairness of generative and classification models, enhancing minorities’ representation in certain sectors, and eventually training algorithms with reduced demographic bias. Meta AI has a more significant commitment to constructing artificial intelligence responsibly and inclusively, especially when addressing social prejudices and increasing the participation of marginalized groups.
A machine-learned sequence-to-sequence demographic perturber has been trained on a large dataset of the human-generated text rewrites to reduce demographic bias in text and develop a more comprehensive demographic term list for measuring fairness. NLP data can be augmented with demographically altered variations to help shatter stereotypes present in the data by altering demographic parameters such as gender, race/ethnicity, and age. “Women like to shop” would be supplemented with “Men like to shop” and “Nonbinary persons like to shop,” for example.”
To begin, the perturber must be fed with a piece of the source text. After that, the term that will cause a commotion in the sentence will be included: women. Once this is done, the intended audience can be specified for the output text, such as “gender: nonbinary/underspecified.” As soon as a person or group is mentioned, the perturber will immediately update the text to match the new demographic’s interests. Because more people of diverse genders enjoy shopping, models trained on demographically enhanced data are less likely to link women to shopping strongly.
Meta places a high value on the development of responsible AI in the future. Everyone should have equal access to information, services, and opportunities, and fairness is at the center of this goal. Everything takes time.
Researchers have free access to the perturber, human-generated rewrites, and the complete set of demographic terms. The perturber produces better-rewritten material for lengthier text sections with multiple demographic terms, according to the results. Nonbinary gender identities, for example, are better represented in the perturber than they were in prior efforts. This means that fewer incidents of unfairness go unmeasured.
The work has made clear progress toward more inclusive and respectful NLP models that everyone may use, regardless of their identity. When it comes to boosting AI robustness, the perturber and comprehensive set of demographic terms both use the same approach: slightly altering the text content, which is a tried-and-tested strategy.
Research at Meta AI focuses on implementing ethical research standards from the start of every project and refining methodologies for assessing the fairness of artificial intelligence systems. The foundation for this study is Meta AI’s recent work detecting gender-based errors in machine translation and the pioneering new dataset for evaluating the performance of computer vision models across a varied range of ages, genders, and skin tones. Meta AI’s other recent papers build on this foundation.
As much as these initiatives can benefit the broader AI community by refining methodologies for gauging fairness and social bias in various AI systems and technologies, more work remains to be done in this area.
This Article Is Based On The Research Article 'Introducing two new datasets to help measure fairness and mitigate AI bias'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper and codes. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.