Latest Paper From Amazon AI Research Analyzes And Explains The Challenges And Developments in The Field Of Federated Learning

This article summary is based on the research paper from Amazon: 'Federated learning challenges and opportunities: An outlook' All credits for this research goes to the authors of this paper. 👏 👏 👏 👏 Please don't forget to join our ML Subreddit Need help in creating ML Research content for your lab/startup? Talk to us [email protected]
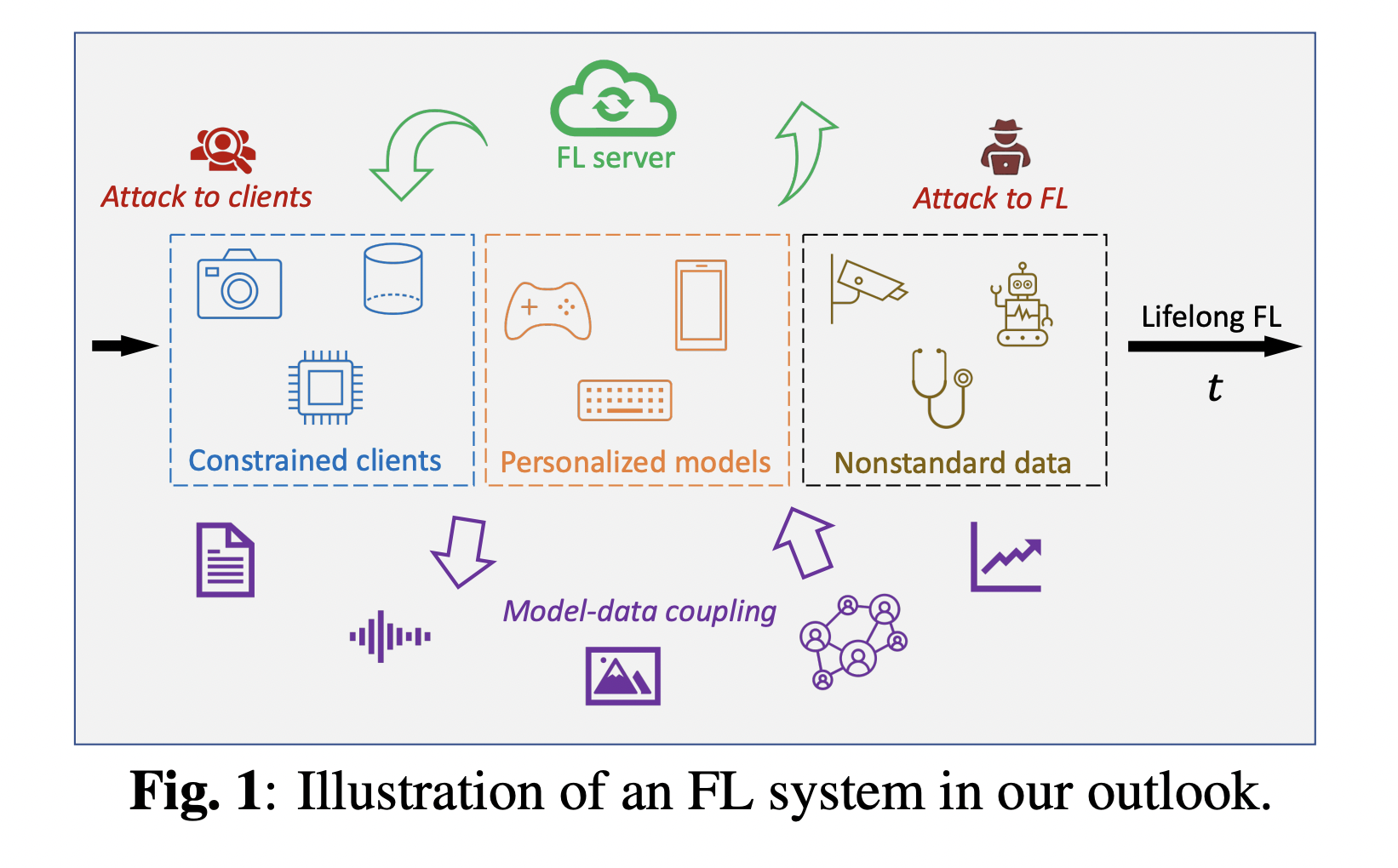
A recent research paper from Amazon researchers explains the Challenges And Developments in The Field Of Federated Learning. Federated learning is a distributed learning framework gaining immense popularity. It learns a joint model throughout various rounds of communication between various edge devices storing data locally. Clients conduct several local changes in each round after receiving a model from a server, and the server aggregates models from a subset of clients. Practical FL models have a highly sophisticated architecture since they incorporate a large number of devices, unknown heterogeneity from many clients, limited capacity, and partially labeled data.
Prediction and Detection are the two main goals of any supervised learning algorithm. Prediction- and detection-oriented modeling has been a topic of various studies in centralized settings, but little is known about it in the context of FL. A hot question is whether an FL model of good prediction performance will inevitably sacrifice detection power.
According to statistical data, the conventional FL can converge to a suitable model over a sufficient number of local updates for communication efficiency. Meanwhile, due to the variable amount of data stored by clients, overly aggressive local updates can also harm the model. The idea is to determine the least number of communication rounds required to converge to a model that performs comparably to centralized training.
Many FL applications strive to improve heterogeneous data clients. Unlike traditional FL, Personalized FL trains a single model and learns a set of client-specific models that minimize test errors beyond what a single global model can. Existing work on personalized FL frequently develops algorithms from a heuristic optimization formulation to reduce the discrepancy between local and global parameters.

On-device hardware capacity must be accommodated in a functional FL system for edge devices. But, there are two major tradeoff factors. Each on-device model must be minimal in size due to memory limits as servers face issues in working on huge function classes for large data. Knowledge transfer and distillation, heterogeneous on-device models with neural parameter sharing, and neural architecture search are all promising possibilities.
Second, because of computational limitations, devices are only able to conduct a limited amount of gradient updates. This creates the problem of extended training times, which necessitates the development of a client-side optimization solver as well as a server-side aggregation algorithm. Low-energy devices are also engaged infrequently, resulting in a low client sampling rate and potentially large swings in the aggregated model.
FL is inherently ideal for improving data privacy because it does not require raw data transmissions such as customers’ photos and audio. However, some study has demonstrated that gradients can be used to obtain personally-identifying information from clients. To reduce the possibility of on-device data being hacked, only a minimal amount of data may be stored on a device at a time, which complicates FL training.
Traditional FL systems are only meant to learn a single task from data collected from a single channel. As a result, their ability to generalize is limited in most real-world learning settings where the underlying data and tasks change over time.
The goal of lifelong FL is to create systems that can learn continuously during execution, improve performance steadily over time, and adapt current models to changing environments without forgetting what they’ve learned previously. However, there are significant challenges in the development of such a system.
Instead of keeping a static local dataset, a client frequently receives new data online throughout the continuous operation of an FL system. Therefore, each round’s local training includes both previously observed and newly observed data, complicating the convergence of an FL model. Furthermore, a client may store only a limited amount of data due to memory or security constraints. Thus the local training cannot replay prior data. Consequently, training must be done from a single run of data, posing a significant problem for FL model incremental updates online.
Conclusion
Over the last few years, federated learning has made significant development. However, there are still many tough and intriguing scientific questions to be investigated. The difficulties in federated learning are not well investigated from an algorithmic standpoint and need to be discussed more rigorously. Furthermore, the issues of resource limits at the edge nodes, security, and privacy are all open areas from a system design standpoint. FL research is quickly progressing in application domains beyond computer vision and natural language processing, in addition to algorithmic and system design problems. Therefore, the performance of FL models will only keep getting better over time.
Paper: https://assets.amazon.science/16/e1/9d0192c14604b211336be6c442f5/federated-learning-challenge-and-opportunities-an-outlook.pdf
Credit: Source link
Comments are closed.