Latest Research From Stanford Introduces ‘Domino’: A Python Tool for Identifying and Describing Underperforming Slices in Machine Learning Models

This summary article is based on the paper 'SAT2LOD2: A SOFTWARE FOR AUTOMATED LOD-2 BUILDING RECONSTRUCTION FROM SATELLITE-DERIVED ORTHOPHOTO AND DIGITAL SURFACE MODEL' and all credit goes to the authors of this paper. Please don't forget to join our ML Subreddit
Machine learning and Artificial Intelligence models have gained promising results in recent years. The major factor behind their success is the availability and development of vast datasets. However, regardless of how many terabytes of data you have or how skilled you are at data science, machine learning models will be useless and even dangerous if you can’t make sense of data records.
A slice is a collection of data samples with a common feature. For example, in a picture dataset, photographs of antique vehicles make up a slice. When a model’s performance on the data samples in a slice is significantly lower than its overall performance, the slice is considered underperforming.
Deploying models underperforming on crucial data slices could seriously harm safety and fairness. For instance, models trained to detect collapsed lungs in chest X-rays generally make predictions based on the presence of chest drains, a common therapeutic device. As a result, computer models typically fail to detect collapsed lungs in images without chest drains, a critical data slice in which inaccurate negative predictions could be catastrophic.
Not many studies have considered underperforming slices during model evaluation. Researchers believe that knowing which slices their models underperform would help practitioners not just make better decisions regarding model deployment but also improve model robustness by upgrading the training dataset or utilizing robust optimization strategies.
Detecting slices is challenging because the “hidden” data slices are linked by a notion that isn’t easily derived from unstructured inputs or labeled in metadata (e.g., images, video, time-series data).

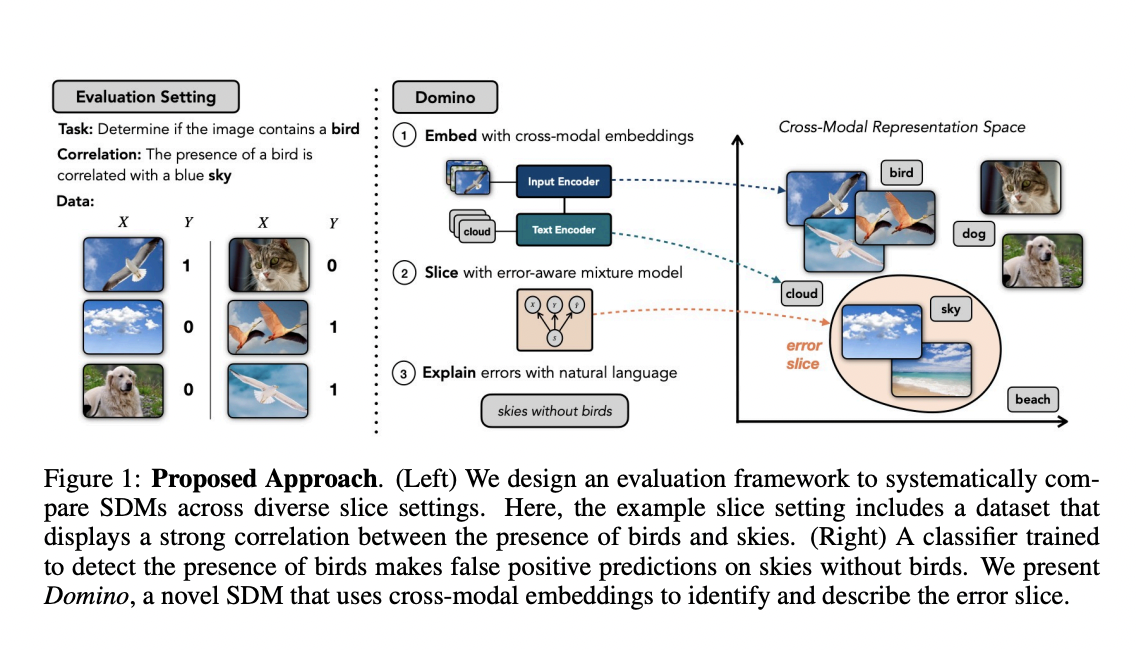
In this article, we dive into new research conducted by a Stanford team that introduces a novel method for identifying and describing underperforming slices.
The researchers introduce a novel slice discovery approach called Domino in their paper “DOMINO: DISCOVERING SYSTEMATIC ERRORS WITH CROSS-MODAL EMBEDDINGS.” The method uses a new family of cross-modal representation learning algorithms that produce semantically meaningful representations by combining images and text in the same latent space. Their experiment results show how cross-modal representations improve slice coherence while allowing Domino to produce plain language descriptions for recognized slices.
Slice discovery involves searching unstructured input material (such as photos, movies, and audio) for semantically significant subgroups where a model fails. Slice Discovery Methods (SDMs) compute a set of slicing functions that partition the dataset into slices given a labeled validation dataset and a trained classifier. An ideal SDM should identify slices, including cases when the model underperforms or has a high error rate. Furthermore, the slices should be identified by examples that are coherent or closely correlate with a human-understandable idea.
Domino follows a three-step process as follows:
- Embed: It uses a cross-modal encoder to embed the validation images alongside the text in a shared embedding space.
- Slice: It uses an error-aware mixture model to discover locations in the embedding space with a high concentration of mistakes.
- Describe: Domino creates natural language descriptions of the slices to help practitioners understand the commonalities among the cases in each slice. It accomplishes this by surfacing the text closest to the slice in the embedding space using the cross-modal embeddings generated in Step 1.
The Domino study was inspired by a variety of recently developed new slice finding methods such as the Spotlight (D’Eon et al. 2022), GEORGE (Sohoni et al. 2020), and MultiAccuracy Boost. Like Domino, these approaches have (1) an embed step and (2) a slicing step. However, they employ different embeddings and slicing algorithms. These approaches, in particular, lack a (3) description stage, forcing users to manually evaluate examples and find common properties. The researchers evaluate SDMs for two criteria: eliminating the embedding choice and the slicing algorithm.
Unlike prior evaluation approaches, which use a qualitative way to visualize identified slices for practitioners to inspect them and evaluate whether they “made sense,” the researchers aimed to estimate an SDM’s failure rate. One of the arguments they give in their papers is that qualitative assessments are subjective and don’t scale beyond a few settings. Furthermore, they have no way of knowing if the SDM has missed a crucial, cohesive slice. As a result, they wanted to know how often SDM fails to identify a coherent slice on which the model performs poorly. Estimating this failure rate, they claim, is difficult since the whole set of slices on which a model underperforms is unknown.
They trained 1,235 deep classifiers with the goal of underperforming on pre-determined slices. This was done in three domains: natural photos, medical images, and medical time series. Their method entailed:
- Getting a dataset containing some annotated slices
- Altering the dataset so that a model trained on it would almost certainly perform poorly on one or more of the annotated slices.
This framework allowed them to evaluate Domino quantitatively. Their results show that Domino correctly recognizes 36% of the 1,235 slices in the architecture. Furthermore, in 35% of cases, the created slice’s natural language description matches the slice’s name exactly.
The researchers discovered that representation matters a great deal. They show that performance is improved by cross-modal embeddings. In the precision-at-10 test, slice discovery approaches based on cross-modal embeddings outperform those based on a single modality by at least 9 percentage points. Compared to employing the trained model’s activations, the difference is 15 percentage points. Given that classifier activations are a frequent embedding choice in existing SDMs, this finding is particularly intriguing.
According to the team, slice discovery is more accurate when both the prediction and the class label are modeled. It is not enough to have good embeddings; the algorithm used to extract the underperforming slices from the embedding space is also important. The study’s findings show that a simple mixed model that models the embeddings, labels, and predictions achieves a 105 percent improvement over the next best slicing technique. This is because their approach is unique. It models class labels and model predictions as independent variables, resulting in slices with “pure” error types (false positive vs. false negative).
Domino is currently being used to test a popular off-the-shelf classifier: a ResNet18 that has been pre-trained on ImageNet. They examine the model’s ability to recognize automobiles, particularly to see if there are any interesting slices where the model underperforms. Their findings show that the model has trouble distinguishing between photographs of automobiles taken from the inside and photos of racecars. The team wishes to add more training examples to improve performance in certain slices, depending on the model’s intended use case.
The researchers wish to collaborate with others to build more reliable slice discovery methods. To that end, they have shared 984 models and their accompanying slices as part of dcbench, a set of data-centric benchmarks. This will allow other researchers to replicate their findings and develop new slice discovery strategies. Further, they are also publishing Domino, a Python package that includes implementations of common slice finding methods.
Paper: https://arxiv.org/pdf/2203.14960.pdf
Article: http://ai.stanford.edu/blog/domino/
Github: https://github.com/HazyResearch/domino
Credit: Source link
Comments are closed.