Latest Robotics Research Releases ‘Hora’: A Single Policy Capable of Rotating Diverse Objects With a Dexterous Robot Hand
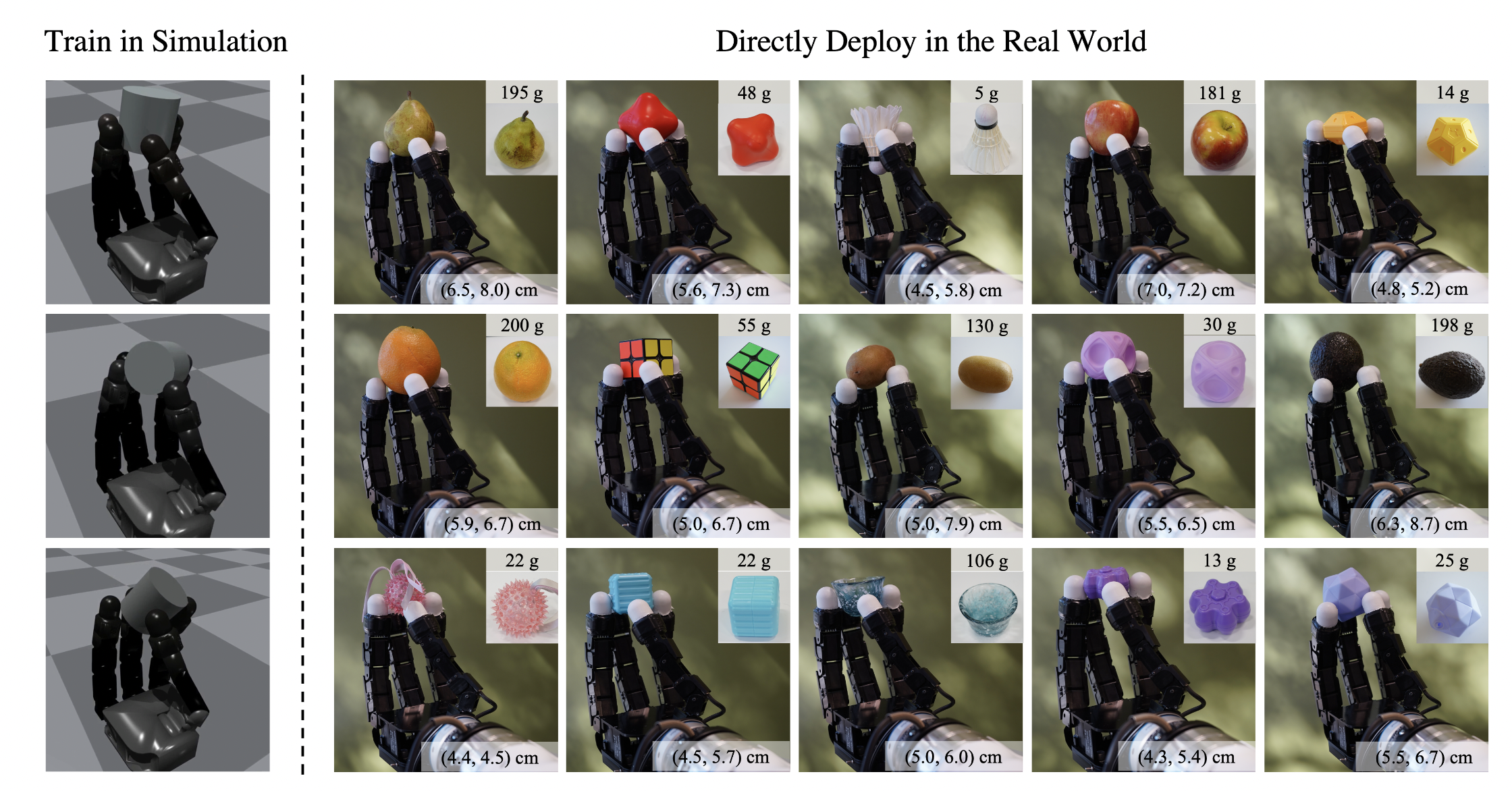
In this article, UC Berkeley and Meta researchers demonstrate how an adaptive controller can be trained to rotate various objects over the z-axis using the fingers of a multi-fingered robot hand. They called it ‘Hora’: a single policy capable of rotating diverse objects with a dexterous robot hand. Hora is trained entirely in simulation and directly deployed in the real world.
Their strategy draws inspiration from recent developments in reinforcement learning-based legged locomotion. These works’ primary objective is to teach pupils how to walk by imparting a condensed depiction of several terrain characteristics known as extrinsic. The learning process results in a flexible and fluid finger gait. The method used by the researcher demonstrates the surprisingly successful use of proprioception sensory signals alone for object adaption, even in the absence of vision and tactile sensing. Interpretable extrinsic values, according to researchers, are correlated with changes in mass and scale as well as a low-dimensional embedding structure. Interest in using reinforcement learning for in-hand manipulation directly in the real environment has grown recently. Instead, they train an adaptive policy using model-free reinforcement learning and then use adaptation to accomplish generalization. Transferring the findings to the actual world remains difficult, even if complicated skills like reorientating various objects can be acquired in simulation.

When facing down, the hand efficiently picks up finger-gaiting behavior and converts it to a real robot. Their method, which can be learned in a few hours, focuses on generalizing a wide range of items. They first go through how to train a base policy using object attributes supplied by a simulator, and then they talk about how to train an adaptation module that can infer these values.
Better training performance and a lot better generalization to out-of-distribution object parameters are made possible by adapting to the shape and dynamics of the object.

Compared to all baselines, the research’s strategy with online adaptation delivers the best result. The periodic baseline, which is just the expert policy being played back, does not provide acceptable performance. With an average Rotation of 23.96 (and an equivalent rotation velocity of 0.8 rad s1), their policy can achieve continuous rotation for nearly all trials without encountering a fall.
Since it is oblivious to item attributes and needs to acquire a single gaiting behavior for all objects, the DR baseline is highly cautious and slow in all trials. With a better Rotation metric but a lower TTF and Rotations, the SysID baseline learns more flexible and dynamic behavior.
The DR baseline can execute a stable but slow in-hand rotation for the container and the shuttlecock, but it mainly fails for the other objects. In the real world, they conducted one continuous evaluation event during which we held six different things in their hands once every 30 seconds. By grouping the extrinsic vector generated when rotating various objects, it is possible to grasp the estimated extrinsic z better. The generic SO(3)reorientation problem is made simpler by rotating an object in your hand along the z-axis. The fundamental realization that enables this generalization is that the shape of the things as experienced by the hand’s fingertips may be condensed into a small area of low-dimensional space. Their approach, which depends on proprioceptive sensing, is blind to the precise points at which the fingertips contact the objects.
Their policy can achieve stable and continuous in-hand rotation in 22 out of 33 objects. This set includes objects with different scales, masses, coefficients of friction, and shapes. The policy can still perform stable and dynamic in-hand rotations for objects with a very high center of mass (the plastic bottle and paper towel). Failure cases are mainly objected to falling from the fingertips because of incorrect contact positions. The policy achieves a smooth gait transition between rotations over different axes.
They find this task harder than single-axis training and need about 1.5× training time. In MLP, they flatten and concatenate the observations over time and directly feed them into the policy network. They also explore using an LSTM network to capture the temporal correlation of input observations.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'In-Hand Object Rotation via Rapid Motor Adaptation'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, github link and project. Please Don't Forget To Join Our ML Subreddit
![]()
Ashish kumar is a consulting intern at MarktechPost. He is currently pursuing his Btech from the Indian Institute of technology(IIT),kanpur. He is passionate about exploring the new advancements in technologies and their real life application.
Credit: Source link
Comments are closed.