Line Open-Sources ‘japanese-large-lm’: A Japanese Language Model With 3.6 Billion Parameters
Since November 2020, LINE has embarked on a transformative journey of research and development to create and harness the power of an advanced large-scale language model tailored specifically for the Japanese language. As a significant milestone in this journey, LINE’s Massive LM development unit has announced the release of their Japanese language models, “Japanese-large-lm,” as open-source software (OSS). This release is poised to significantly impact both the research community and businesses seeking to leverage cutting-edge language models.
These language models come in two variants—the 3.6 billion (3.6B) parameter model and the 1.7 billion (1.7B) parameter model, aptly referred to as the 3.6B model and 1.7B model. By unveiling these models and sharing their comprehensive insights into language model construction, LINE aims to provide a glimpse into the intricacies of their approach and contribute to the advancement of the field.
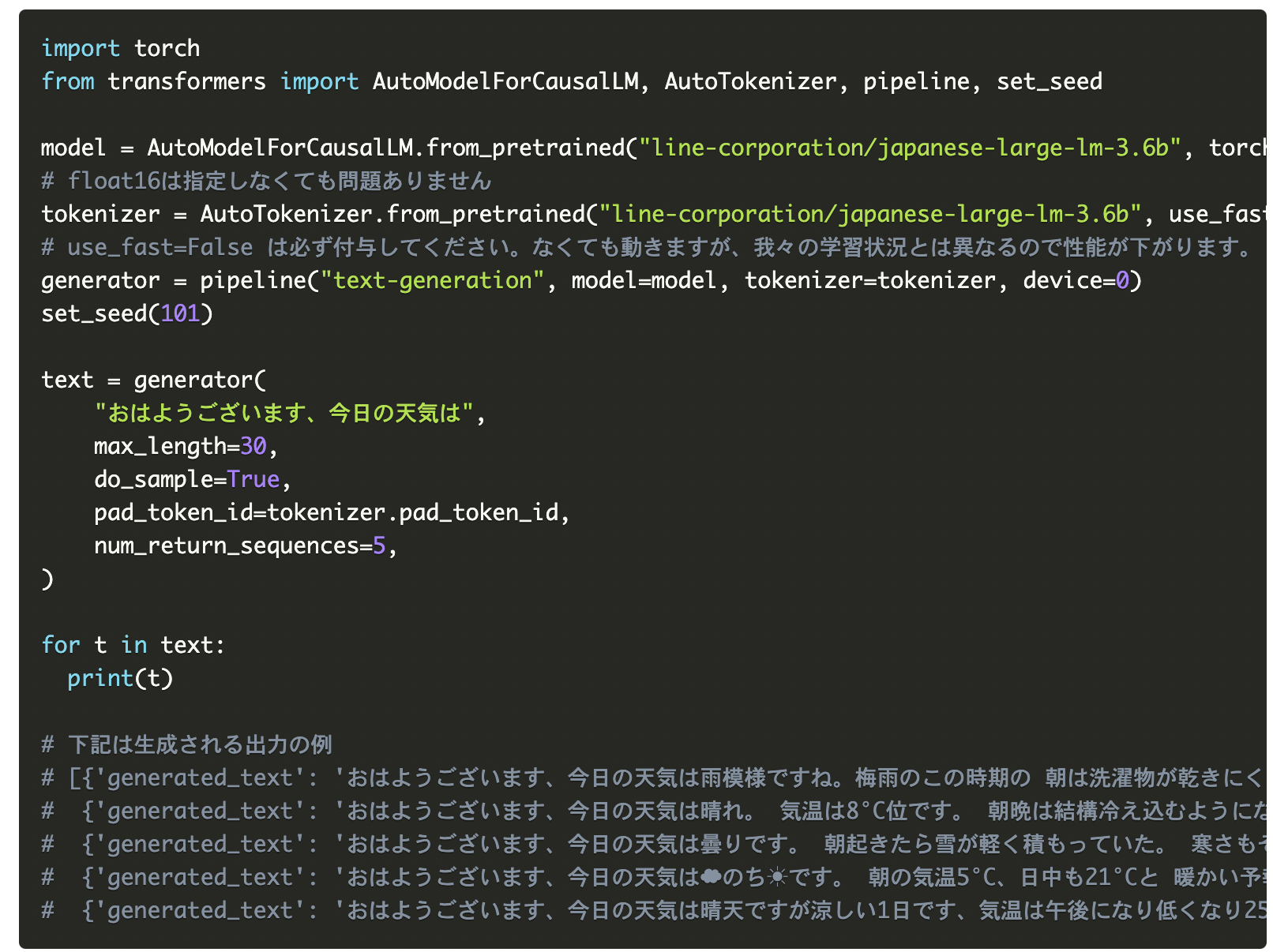
The 1.7B and 3.6B models are accessible via the HuggingFace Hub(1.7B model, 3.6B model), offering seamless integration into various projects through the popular transformers library. Licensing these models under Apache License 2.0 ensures that a wide spectrum of users, including researchers and commercial entities, can leverage their capabilities for diverse applications.
A cornerstone in developing any high-performing language model lies in utilizing an extensive and high-quality training dataset. LINE tapped into its proprietary Japanese web corpus—a repository enriched with diverse textual data to achieve this. However, the challenge web-derived content poses is its inherent noise, including source code and non-Japanese sentences. LINE’s response was to employ meticulous filtering processes powered by the HojiChar OSS library. These processes were instrumental in distilling a large-scale, high-quality dataset, forming the bedrock of the models’ robustness.
Efficiency in model training was a key consideration, and LINE rose to the occasion by implementing innovative techniques like 3D Parallelism and Activation Checkpointing. These advancements facilitated the efficient assimilation of voluminous data, effectively pushing the boundaries of computational capability. Astonishingly, the 1.7B model was developed using just 4000 GPU hours on an A100 80GB GPU—a testament to the efficacy of their learning approach.
Notably, the development trajectory of this Japanese language model diverged from that of HyperCLOVA. Built along a distinct development line, meticulously overseen by LINE’s dedicated Massive LM development unit, this model is a testament to LINE’s commitment to crafting exceptional pre-trained models for the Japanese language. Their overarching goal remains steadfast—integrating insights and lessons from their extensive experience with large-scale language models.
LINE delved into perplexity scores (PPL) and accuracy rates for question-answering and reading comprehension tasks to assess the models’ efficacy. PPL provides insight into the model’s predictive capabilities, while accuracy rates offer tangible performance measures. The results were promising, with LINE’s models showcasing competitive performance across various tasks, rivaling established models in the field.
Underpinning their success was a series of invaluable tips for effective large-scale language model training. These encompass considerations for fine-tuning, the hyperparameter Adam’s beta2, optimal learning rates, and applying a judicious learning rate scheduler. By delving into these technical intricacies, LINE has developed potent models and shared insights that benefit the wider community.
In conclusion, LINE’s release of the 1.7B and 3.6B Japanese language models marks a significant stride in natural language processing. Their commitment to releasing tuned models in the future underscores their dedication to enhancing the capabilities of language models. As LINE continues to make advancements, the global community eagerly anticipates the enduring impact of their ongoing contributions.
Check out the Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.