LinkedIn Engineering Team Develops ‘Opal’ to Ingest Mutable Data and Build Mutable Dataset on Top of the Immutable File System
This article is based on the research article from Linkedin Engineering 'Opal: Building a mutable dataset in data lake'
Trusted data platforms and high-quality data pipelines are critical at LinkedIn for accurate business KPIs and sound decision-making. Today, online data repositories account for a significant portion of LinkedIn’s data. Internet datasets must be migrated to the data lake for further processing and business analytics, whether they are SQL or NoSQL systems.
However, because the data lake architecture is immutable, it cannot be easy to reflect online table updates, inserts, and deletes. Opal was introduced to balance data quality, latency, scan performance, and system scalability (computational resources and operational costs).
LinkedIn Engineering Developed ‘Opal’ that can be utilized to ingest changeable data, such as database entries (Oracle, MySQL, Espresso, Venice, etc.). It creates a modifiable dataset on top of an immutable file system without eagerly reconciling the data files that have been consumed. Simultaneously, it demonstrates the ability to query the snapshot view at any historical time point, a feature known as “time traversal.”

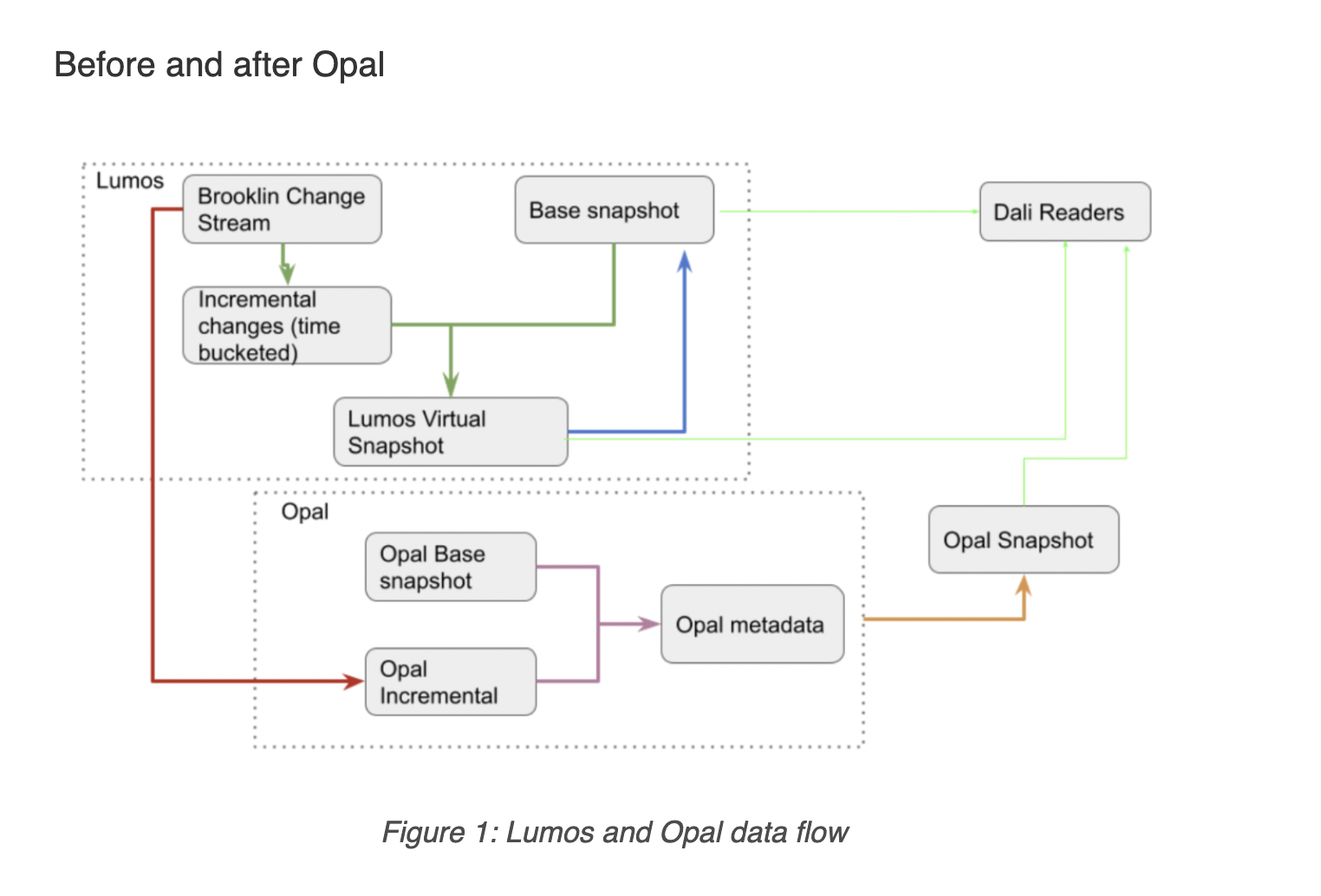
Before Opal, laying down data in an LSM-tree structure to ease merging a base snapshot and delta data was expected to create a snapshot dataset. This system is known as “Lumos.” Another process reorganizes the data from the change stream into delta format. The snapshot is evolved regularly by merging the primary image with the delta.
Rewriting files is an unavoidable part of those activities. Thus write-amplification problems were common, where modest updates squander system resources and make the data system challenging to align with the continuing growth in data volume and use cases. Furthermore, because of the significant latency imposed by the combine, delivering reliable, new data promptly is impractical.

Opal employs read-time filtering, rather than sort-merge, to discover the most recent row for a given key. An updated representation of the data without sorting and restructuring can be found since the data layout is decoupled from the filtering condition. The latency of a shot update can be substantially shorter when filtering metadata is updated within a streaming ingestion task than with the legacy system.
Opal uses a columnar file format to increase full-table scan speed (e.g., Apache ORC). An Opal dataset’s data is divided into logical “segments.”
Each row in a segment has a SegmentOffset and is identifiable by a two-part id: (SegmentIdPart, SegmentIdSeq). These three numbers combine to form a unique row id for the dataset. Each row contains the SegmentIdPart and SegmentIdSeq variables, which can be used to combine numerous logical segments in a data file. These three elements are part of the data file’s schema and can be used to identify a record at a global level, indicating an upstream mutation (update, insert, delete). The “Opal row id” is a tuple that must be unique inside the dataset.

The ingestion engine is in charge of creating such values. For example, when a batch job is launched, an incrementing SegmentIdPart can be assigned to it. By incrementing a sequence number preserved in the ingestion state, files inside the same execution are given a unique SegmentIdSeq. The SegmentOffset tracks the logical offset within a single segment. These attributes are filled in during the ingestion process to provide a unique row id for each ingested record.
Consider each mutation record as a key-value pair, with the key being the primary key of the dataset. It looks like this with Opal columns (A and B are updated throughout two job runs):
The mod time column is a unique column that indicates when the mutation occurred. This column is usually a modification time or sequence number that originates from the upstream source. It’s known as the “delta column,” required in all Opal datasets.

To determine if a record is visible throughout the read time, Opal keeps a validity metadata bitmap. This bitmap comprises two parts: a key store at the dataset level and segment-level segment logs.
The before-image information for each mutation is stored in the key store, which contains the row id for the last valid record for each key in the dataset. The validity state transition for each row id is tracked in segment log entries, arranged by the logical segment id (segmentIdPart, segmentIdSeq). The segment log entries for incoming change stream records are generated by referring to the key store to see if the change invalidates an existing document.
Consider an example. Two log events are emitted when a mutation record (A, 1, 101, 3, 4000) is applied on top of the initial state (shown as bold text, green-colored rows). The record at offset 0 is invalidated first (segmentIdPart=1, segmentIdSeq=101), followed by a SET_VALID_FROM event at offset 3.
The segment logs now consist of the entire series of validity occurrences. The log events for segment –segmentIdPart=1, segmentIdSeq=101 are shown in the following segment log excerpt.
Opal uses specific internal tracking metadata to quickly link segment logs to a particular data file. Because data files and segment logs are not necessarily one-to-one mappings, this is required (due to compaction). Two-staged mappings are used to achieve data-to-segment log correlation:
- Data to segment: Returns a list of all the components associated with a data file.
- The metadata that maps segment ids to data files is saved in the “data management metadata” state store.
The ingestion job keeps track of all files ingested for the dataset by updating the data management information. Batch processing is used for the majority of our ingestion flows. “MetaGen” is the name of the metadata update task, which is a Spark job.
The MetaGen task takes the data files generated by the ingestion process as input and writes updates to the segment log files and bitmap files, which the Opal dataset reader uses to filter out inactive rows. It also informs the key-store of each updated key’s current location. This job updates the log management metadata to keep track of the list of data files that have been handled.
The Opal metadata is updated in the ingestion job with an inline metadata update. Because data isn’t accessible until it’s processed and the metadata is updated, inline metadata updates could help minimize latency. The key-store is kept in this mode in a low-latency key-value store like RocksDB, allowing point lookups and changes.
A base directory is used to hold all Opal data files. The key-store, segment log metadata, and Opal versioning metadata are all kept in sub-directories within this base directory.
Opal’s functionality is similar to Apache Iceberg, Delta Lake, and Apache Hudi. Only Hudi was accessible as open source at the time Opal was conceived. Hudi was not explored because one of the aims for Opal was to prevent read time merging and reduce the need for compaction. Iceberg and Delta Lake were released as Opal was finalizing the first use cases, and they didn’t enable row-level mutations, which are essential for the big base data, small change size datasets.
Copy-on-write overhead would be significant for these datasets. Row-level deletes are included in the Iceberg V2 specification, and implementation is now underway.
Since 2020, Opal has continued to support LinkedIn’s low-latency use cases, including DED at LinkedIn, which spans petabytes of data. It will continue to become better in the future.
Source: https://engineering.linkedin.com/blog/2022/opal–building-a-mutable-dataset-in-data-lake
Suggested
Credit: Source link
Comments are closed.